Сбор, обработка и представление данных в Google Analytics 4
В разных сообществах поднимается много вопросов относительно того, как Google Analytics 4 собирает и обрабатывает данные в своих ресурсах. Почему некоторые данные по событиям отображаются в DebugView и Исследованиях, но не отображаются в стандартных отчетах, какие данные попадают в строку (other), есть ли в GA4 семплирование (выборка данных), пороговые значения, различается ли статистика в интерфейсе от данных, экспортированных в BigQuery, что такое HyperLogLog++, кардинальность и много чего еще. В этой статье я постараюсь собрать весь практический опыт и знания по сбору и обработке данных в Google Analytics 4, известные на текущий момент.
Этот материал будет обновляться по мере появления новых фактов. Если у вас будут какие-то комментарии, дополнения или замечания по статье, пожалуйста, напишите мне по форме обратной связи.
В тот же день, что и вышел этот материал, я на своем YouTube-канале провел лекцию по этой теме. Если вам легче воспринимать видеоматериал, то можете посмотреть видео ниже:
Принцип работы Google Analytics
Чтобы правильно интерпретировать данные, важно понимать общие принципы их сбора и обработки. В Google Analytics есть 4 основных компонента: сбор данных, обработка данных, настройка (конфигурация) и отчетность.
Схематично это можно представить так:
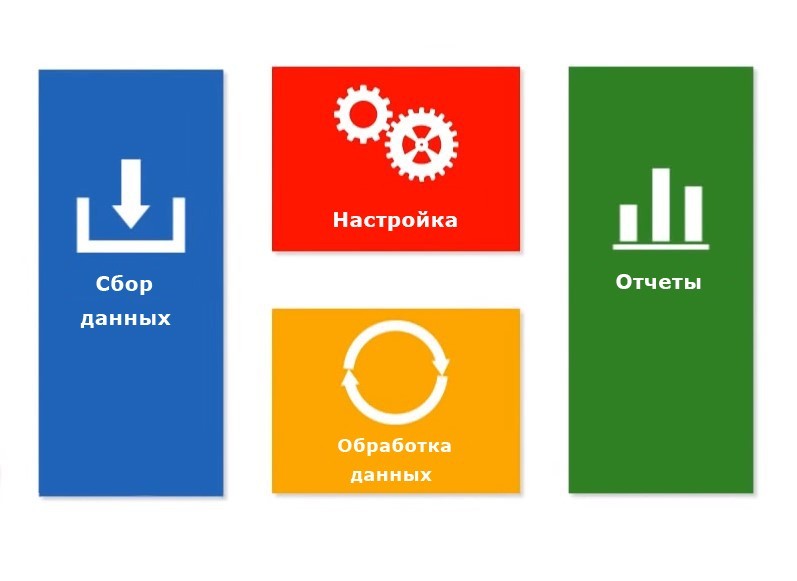
Сбор данных, обработка данных, настройка и отчеты
Сбор данных
Для этого в Google Analytics используется небольшой фрагмент кода на языке программирования JavaScript (его еще называют тегом Google или страничным тегом), который собирает различную информацию о действиях ваших пользователей. Его необходимо добавить на все отслеживаемые страницы сайта. Вы также можете собирать данные с HTML-страниц, SPA-сайтов, ускоренных AMP-страниц и мобильных приложений. Но в этом материале я буду делать акцент именно на веб-потоки (сайты).
С выходом нового тега Google (обновленного глобального тега, gtag.js) этот код в интерфейсе Google Analytics стал выглядеть так:
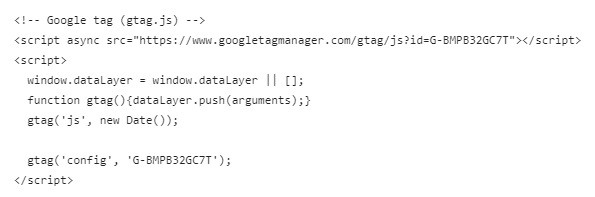
Код тега Google (Google Tag, gtag.js)
Этот тег использует собственные файлы cookie для идентификации уникальных пользователей и сеансов. После того, как вы установите счетчик Google Analytics 4, и пользователи начнут посещать ваш сайт, для каждого из них в браузере будут созданы следующие файлы cookie:
- _ga - позволяет различать пользователей (срок жизни - 2 года);
- _gid - позволяет различать пользователей (срок жизни - 24 часа);
- _ga_<container-id> (с идентификатором потока данных) - позволяет сохранять состояние сеанса, включая идентификатор и номер сеанса (срок жизни - 2 года);
- _gac_gb_<container-id> (с идентификатором потока данных) - содержит данные, связанные с кампанией (срок жизни - 90 дней). После установления связи между аккаунтами Google Analytics и Google Ads размещенные на сайте теги конверсии Google Рекламы будут получать данные из файла cookie, если вы не отключите эту возможность. Подробнее об этом читайте в официальной документации Google.
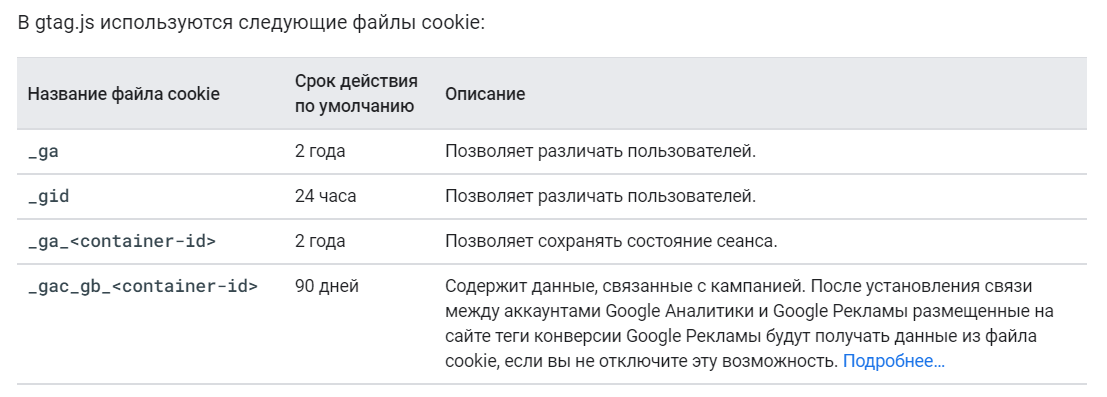
Файлы cookie в gtag.js
Ключевым файлом cookie Google Analytics является именно _ga, который содержит уникальный идентификатор пользователя.
Уникальный идентификатор пользователя (Client ID, идентификатор устройства) - это метка, состоящая из случайного числа и даты первого посещения пользователем сайта в Unix формате (количество секунд с 1 января 1970 года 00:00:00 UTC), которая сохраняется в основном файле cookie (_ga) в течение 2 лет (по умолчанию) или пока пользователь не удалит его.
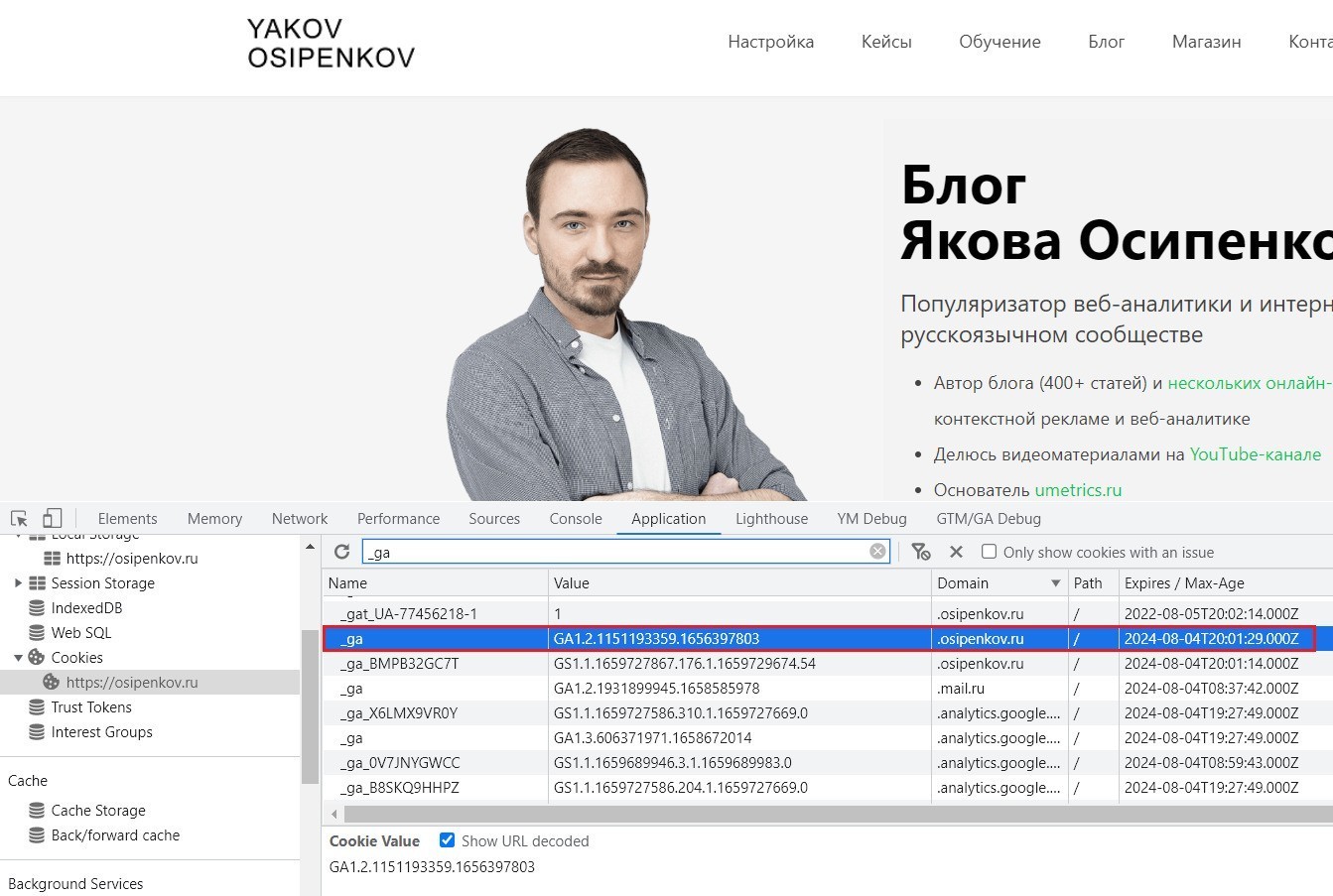
Пример основного файла cookie (_ga)
Каждый раз, когда посетитель переходит на ваш сайт, в его браузере выполняется код отслеживания. Во время первого захода он вместе с автоматически регистрируемым событием first_visit (первый визит) записывает в браузер посетителя файл cookie, в котором содержится уникальный идентификатор пользователя Client ID.
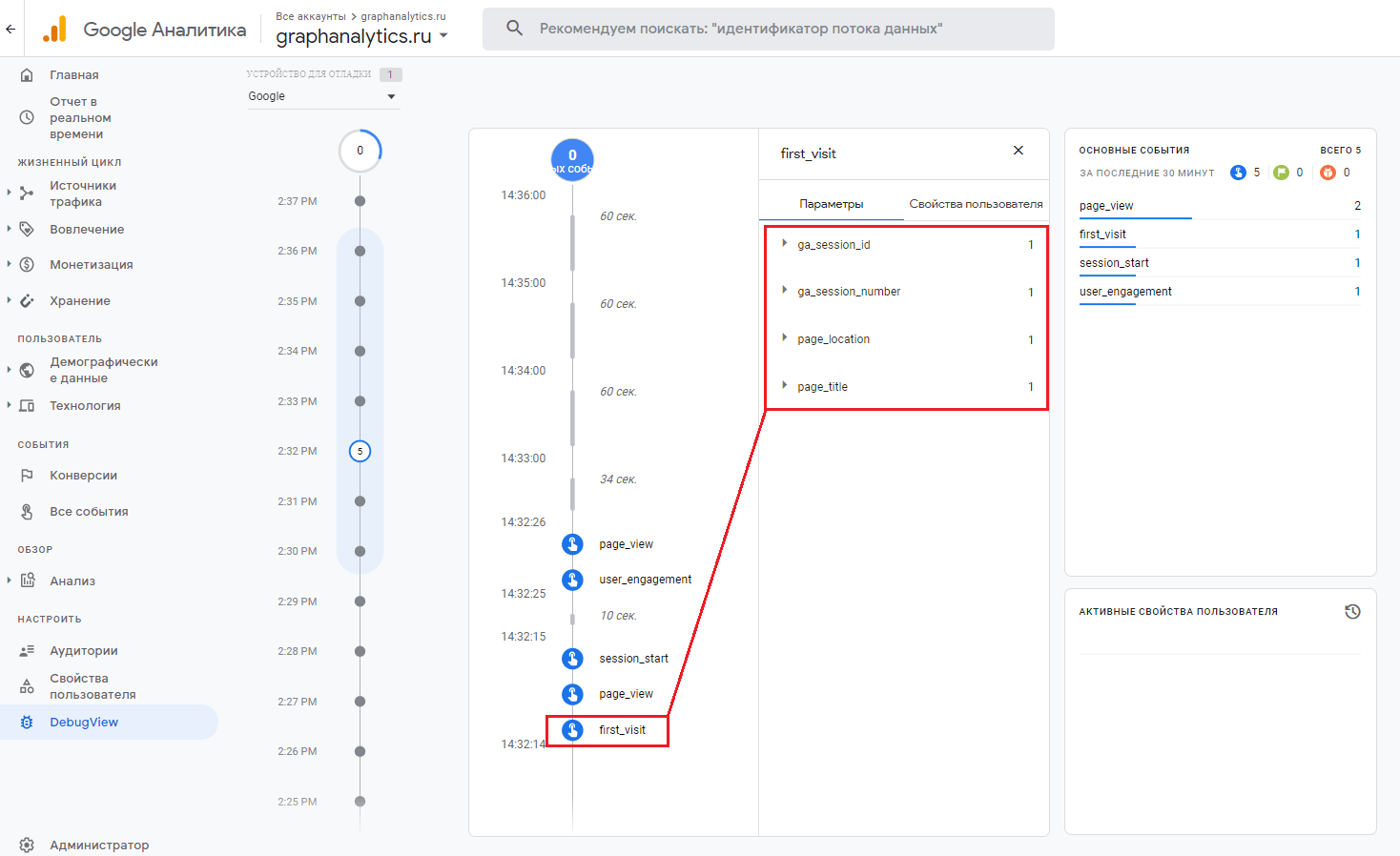
При первом заходе с событием first_visit впервые у пользователя создается Client ID
Этот файл cookie будет храниться установленный в настройках Google Analytics 4 по умолчанию срок. Все последующие сеансы с того же браузера будут засчитаны системой Google Analytics как возвраты этого посетителя, его повторные посещения. Client ID является одним из способов идентификации и установления связи между событиями и пользователями. Но, как вы понимаете, Google Analytics 4 не сможет собирать данные о пользователях, которые отключили файлы cookie, блокируют их с помощью специальных программ, расширений и браузеров, а также периодически удаляют их из браузера (чистят историю посещений) или в принципе отказались от отслеживания благодаря режиму согласия и политике GDPR.
Таким образом, есть много вариантов, когда Google Analytics не сможет отследить действия пользователя на вашем сайте:
- файлы cookie блокируют блокировщики рекламы типа AdBlock, Ghostery и т.д.;
- файлы cookie блокирует сам браузер с помощью системы интеллектуального отслеживания (Safari, Firefox, Brave и другие);
- в настройках браузера по умолчанию заблокированы файлы cookie;
- антивирус, установленный на ваш компьютер, может влиять на отслеживание;
- пользователь удалил файлы cookie (историю посещений) и зашел повторно – кука новая, ее еще нет в счетчике GA4 -> это снова новый пользователь;
- пользователь запретил отслеживание файлов cookie с помощью режима согласия;
- на вашем сайте много различных кодов отслеживаний, которые затрудняют запуск счетчика Google Analytics. Пользователь зашел на сайт, что-то на нем поделал и вышел, а GA4 так и не прогрузился и не отследил это.
Client ID не является единственным вариантом отслеживания в GA4. Есть еще User ID, сигналы Google, моделирование. Подробнее о способах идентификации пользователей в Google Analytics 4 читайте по ссылке и ниже в этой статье.
Таким образом, код отслеживания JavaScript может собирать:
- информацию с самого сайта, например, URL тех страниц, которые просматривает пользователь или товары, которые он добавлял в корзину;
- данные браузера пользователя: языковые настройки, название браузера, устройства, разрешение экрана, операционная система;
- информацию об источнике, с которого пользователь перешел на сайт;
- приблизительное местоположение посетителя;
- и многое другое.
Если в интерфейсе вы активируете сбор событий улучшенной статистики для веб-потока, то и они будут собираться автоматически для вашего ресурса.
Вы можете передавать дополнительную информацию о ваших пользователях в Google Analytics 4 даже в том случае, если они были совершены за пределами вашего сайта или мобильного приложения, с любого устройства, подключенного к интернету (извне/офлайн). Делать это можно с помощью специальных запросов Measurement Protocol.
Все эти данные группируются и отправляются на серверы Google для дальнейшей обработки.
Обработка данных
Google Analytics может собирать большое количество данных, используя только стандартный код отслеживания JavaScript без каких-либо модификаций. После того, как обращения от пользователя будут отправлены на серверы Google, следующим этапом станет их обработка. Здесь все наши необработанные данные преобразуются в более ценную информацию по определенным критериям. Например, идет классификация по типам устройств, местоположению, источникам перехода и т.д.
Но существуют также и параметры конфигурации, которые позволяют вам задать способ обработки данных вручную. Именно на этом этапе к вашим данным будут применяться настройки, которые вы указали в своем ресурсе GA4 в интерфейсе или выполняете с помощью Admin API. Эти настройки отличаются от предыдущей версии Universal Analytics, но их по-прежнему много и заданная конфигурация тега Google будет влиять на итоговую обработку данных.
Настройка (конфигурация)
К таким настройкам в Google Analytics 4 относятся все, которые находятся в разделе Потоки данных - Веб-поток - Тег Google - Настройки тега:
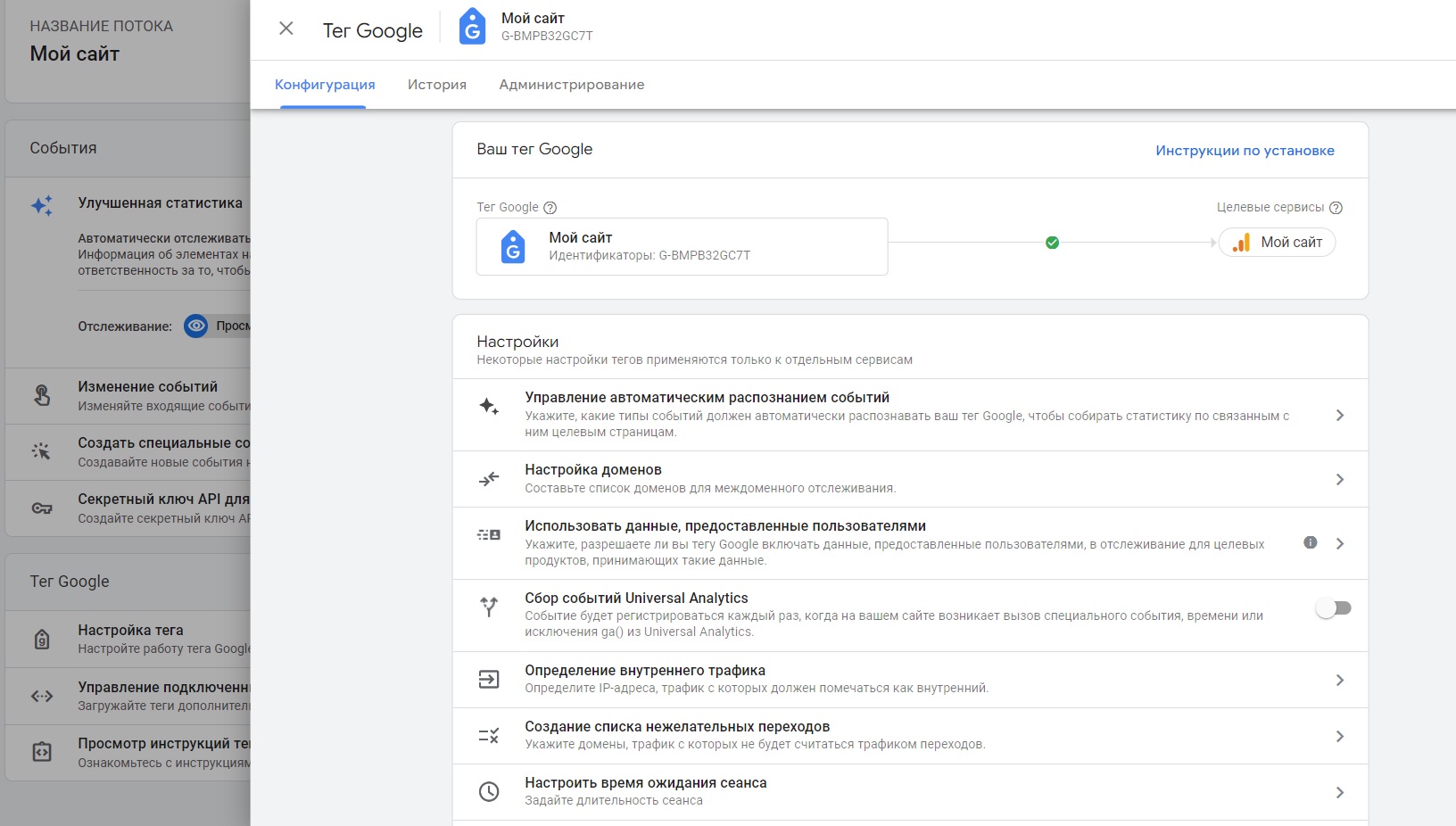
Настройки тега Google
- Управление автоматическим распознанием событий;
- Настройка доменов;
- Использование данных, предоставленных пользователями;
- Сбор событий Universal Analytics;
- Определение внутреннего трафика;
- Создание списка нежелательных переходов;
- Изменение длительности сеанса.
Подробнее о том, как работает каждая из них, читайте в этой публикации.
К дополнительным настройкам еще относятся:
- события улучшенной статистики;
- настройки ресурса (сфера деятельности, часовой пояс и валюта);
- срок хранения данных о событиях;
- сбор данных с помощью сигналов Google (Google Signals);
- сбор подробных данных о местоположении и устройстве;
- расширенные настройки для персонализации рекламы;
- группы контента;
- фильтры данных;
- группы каналов;
- импорт данных;
- способы идентификации пользователей;
- настройки атрибуции;
- различные связи с другими продуктами Google (BigQuery, Search Console, Ads, Merchant Center, AdSense, Google Play и другими)
Важно помнить, что ваши данные Google Analytics сохраняются в базе данных на серверах Google, где их невозможно изменить. Как правило, настройки ресурса GA4 применяются к новым данным и не затрагивают исторические, уже собранные и отображаемые в отчетах. Поэтому при настройке тега не исключайте данные, которые могут вам пригодиться. После того, как статистика обработана и включена в базу данных, ее не изменить. Затем на основе обработанных данных Google строит отчетность.
В предыдущей версии Universal Analytics была возможность очень гибко настроить конфигурацию своего ресурса на уровне представления - задать фильтры, исключить/включить трафик на определенный хост, изменить параметры ссылки, скорректировать источник трафика и многое другое. В Google Analytics 4 такой возможности нет, а фильтры данных ограничены только трафиком разработки и внутренним трафиком.
Отчетность
Обработанную информацию Google предоставляет нам в виде красивых отчетов и графиков в интерфейсе Google Analytics 4. Это могут быть как стандартные отчеты, обзорные отчеты, так и созданные вами специальные отчеты, или Исследования - Когортное исследование, Исследование пути, Исследование воронки, Наложение сегментов, Статистика пользователей, Общая ценность пользователя.
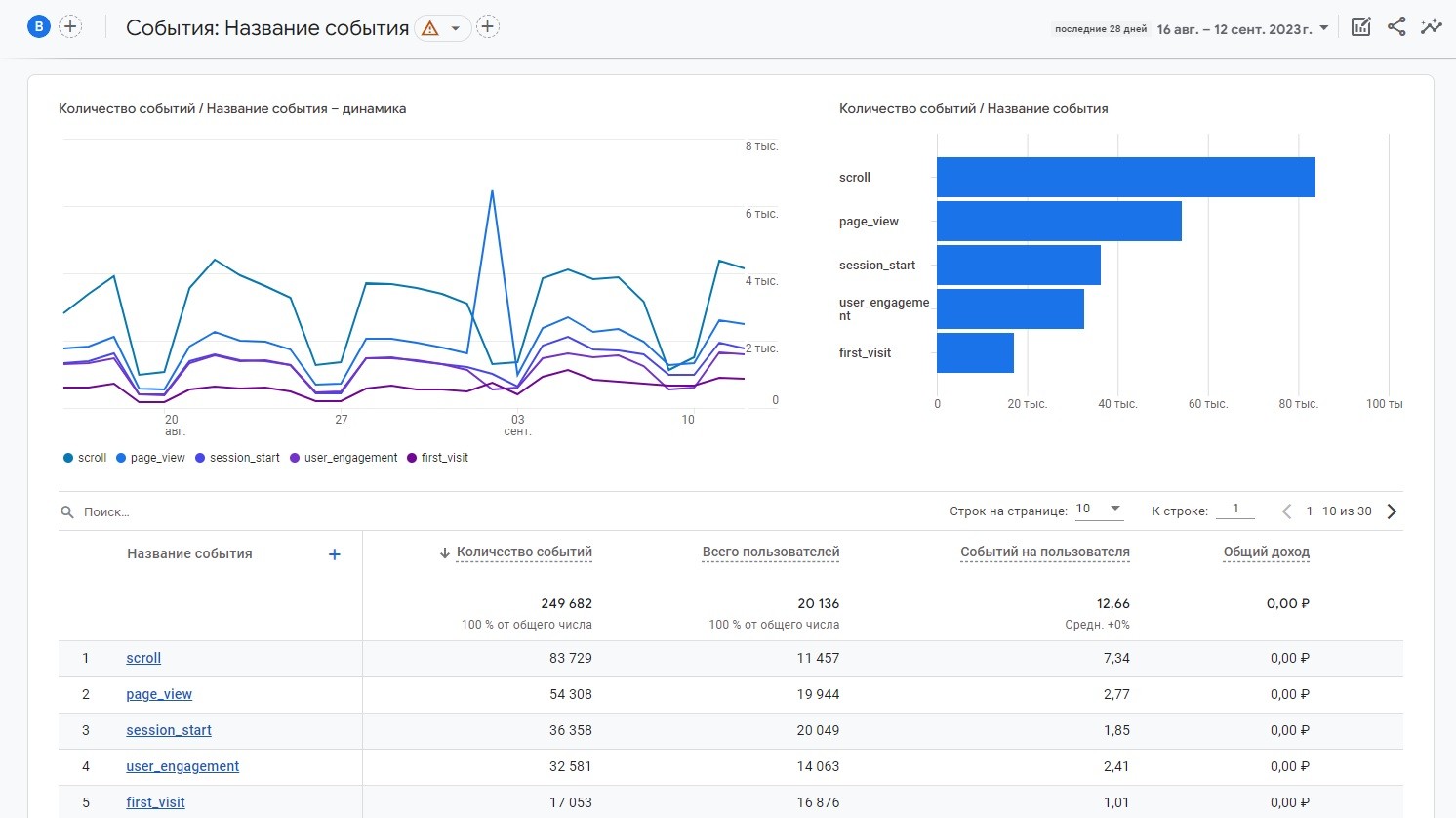
Пример отчета в Google Analytics 4
Однако вы также можете выгружать данные из аккаунтов Google Analytics с помощью API Google Analytics 4 (Data API) или же работать с ними в облачном хранилище Google BigQuery или Looker Studio (Google Data Studio). В отчетах GA4 также доступен экспорт данных в Google Таблицы или локальное сохранение в формате CSV или скачивание PDF документа. А еще с недавнего времени Google выпустил дополнение для Google Таблиц - GA4 Reports Builder for Google Analytics.
Теперь давайте перейдем к ограничениям Google Analytics 4, которые могут сказаться на результатах вашей работы и о которых вы должны знать прежде, чем начнется углубленно изучать его функционал. Поверьте, их куда больше, чем в предыдущей версии Universal Analytics, и в некоторых местах они куда болезненнее.
Срок хранения данных - 2 или 14 месяцев
Подробнее про хранение данных читайте в официальной справке Google.
В Google Analytics 4 вы можете указать, в течение какого времени должны храниться данные о пользователях и событиях. По истечении этого срока данные автоматически удаляются с серверов Google. По умолчанию, после создания счетчика Google Analytics 4, срок хранения данных на уровне пользователя составляет 2 месяца. Он также применяется для данных о конверсиях. Я рекомендую изменить это значение на 14 месяцев (Администратор - Ресурс - Настройки данных - Хранение данных):
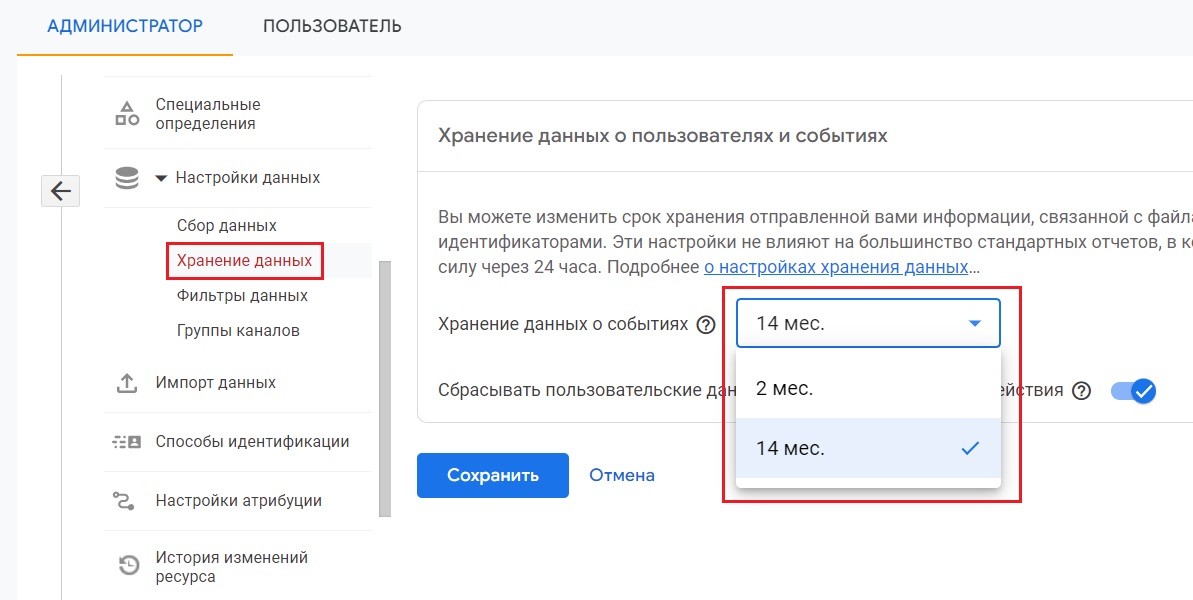
Хранение данных о событиях
Для всех остальных данных о событиях вы можете выбрать один из следующих вариантов:
- 2 месяца;
- 14 месяцев;
- 26 месяцев (только в Google Аналитике 360);
- 38 месяцев (только в Google Аналитике 360);
- 50 месяцев (только в Google Аналитике 360).
Примечание: если вы увеличите срок хранения, это затронет уже собранные данные и те, которые вы еще не удалили. Новый срок хранения начинает действовать через 24 часа после его выбора. В течение этого времени вы можете отменить изменение без последствий для своих данных.
Важно понимать, что срок хранения данных не учитывается в стандартных агрегированных отчетах (включая основные и дополнительные параметры), даже если вы используете функцию сравнения (в русском интерфейсе она еще называется Добавить акции). Эта настройка распространяется только на отчеты в инструменте Исследования и отчеты по последовательностям. Это означает, что вы можете выбрать диапазон дат больше, чем за последние два года в стандартных отчетах.
Например, вот так выглядит отчет по источникам трафика моего счетчика Google Analytics 4 за февраль 2020 года:
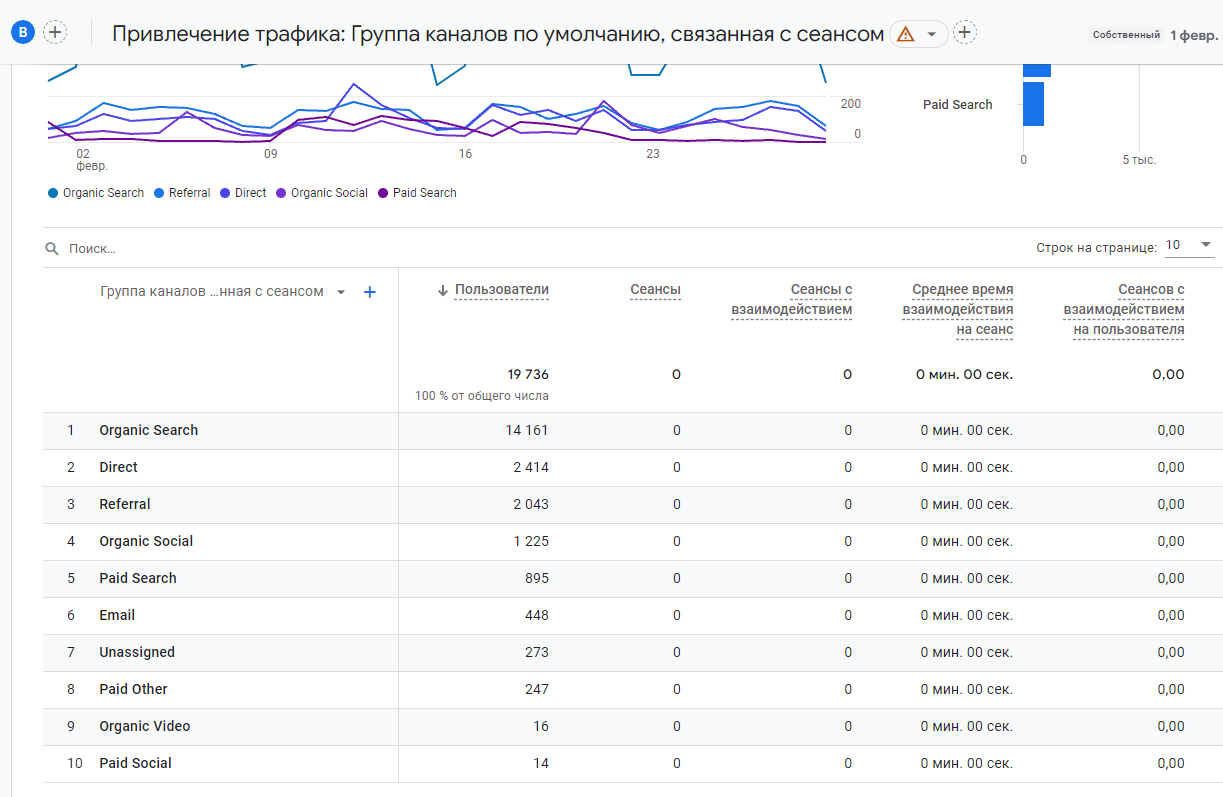
Пример стандартного отчета по источникам трафика Google Analytics 4 (февраль 2020)
Как видите, в нем присутствует статистика на уровне пользователей, хотя период выбран больше, чем срок хранения. Правда данные по сеансам и другим показателям в нем отсутствуют, но в предыдущей версии Google Analytics за тот же самый диапазон дат вы ее могли посмотреть:
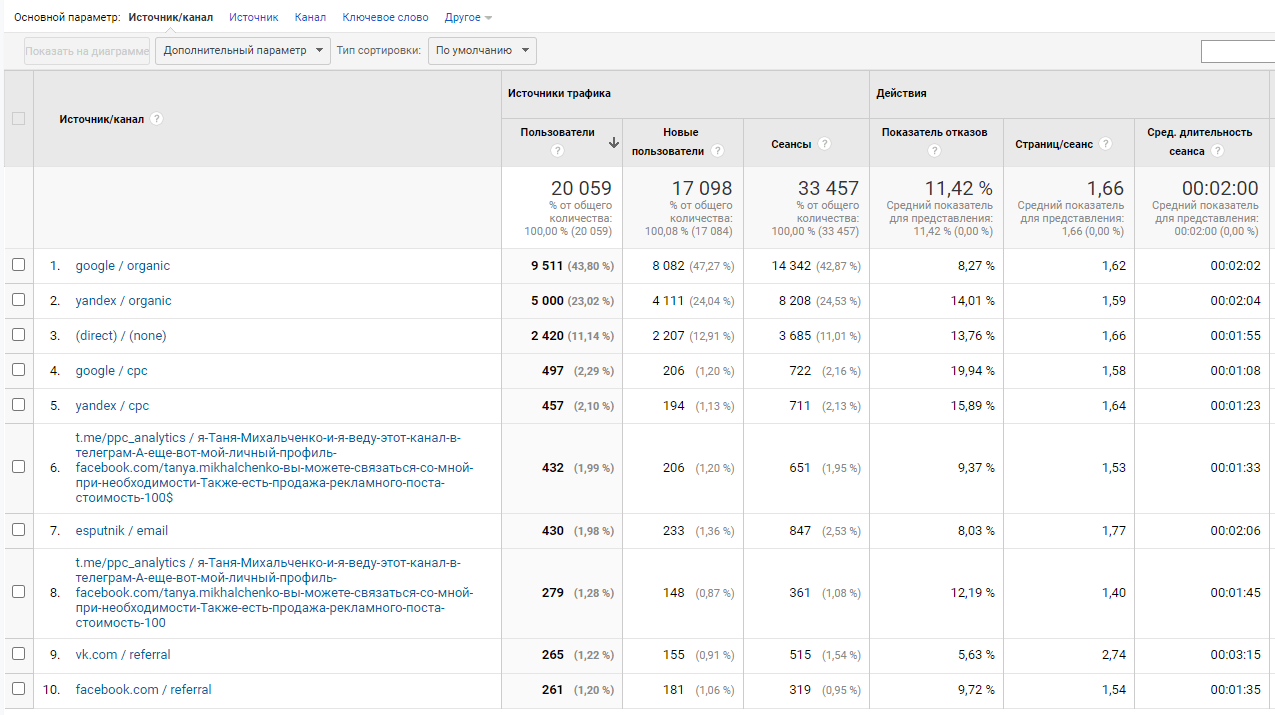
Пример стандартного отчета по источникам трафика в Universal Analytics (февраль 2020)
Но такой же диапазон дат (февраль 2020) я не смогу выбрать в Исследованиях, поскольку в них действует ограничение на срок хранения:
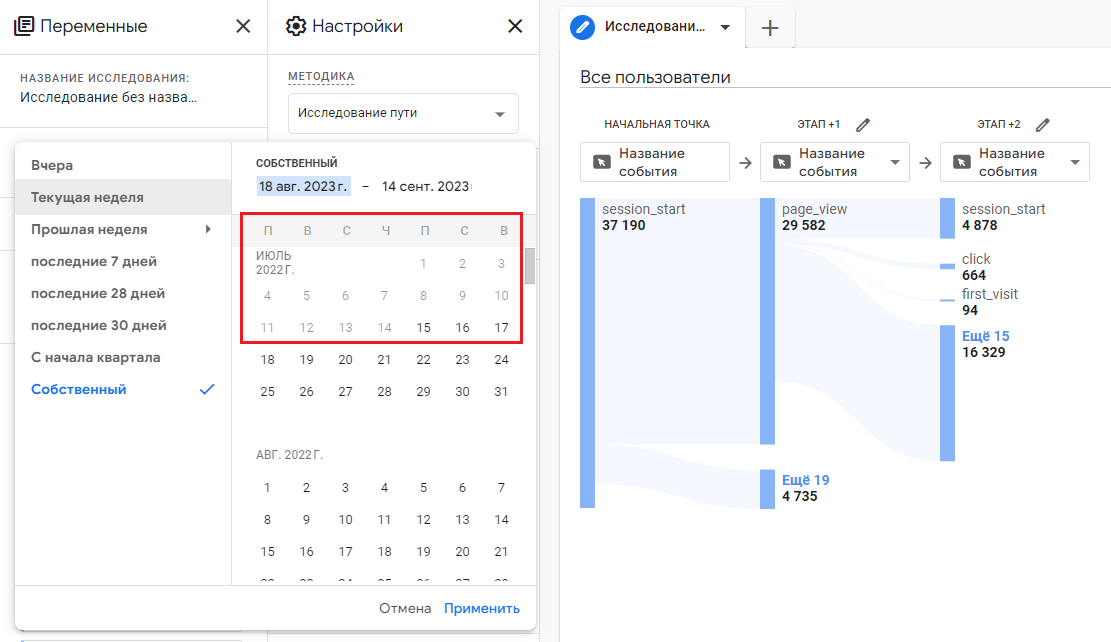
В Исследованиях действует ограничение на 2/14 месяцев
Эту статью я писал в середине сентября 2023 года, поэтому максимальный диапазон дат, который можно выбрать - 14 месяцев (выбран в настройках), то есть до середины июля 2022 года.
Данные по событиям в агрегированных отчетах тоже будут доступны за больший, чем срок хранения период:
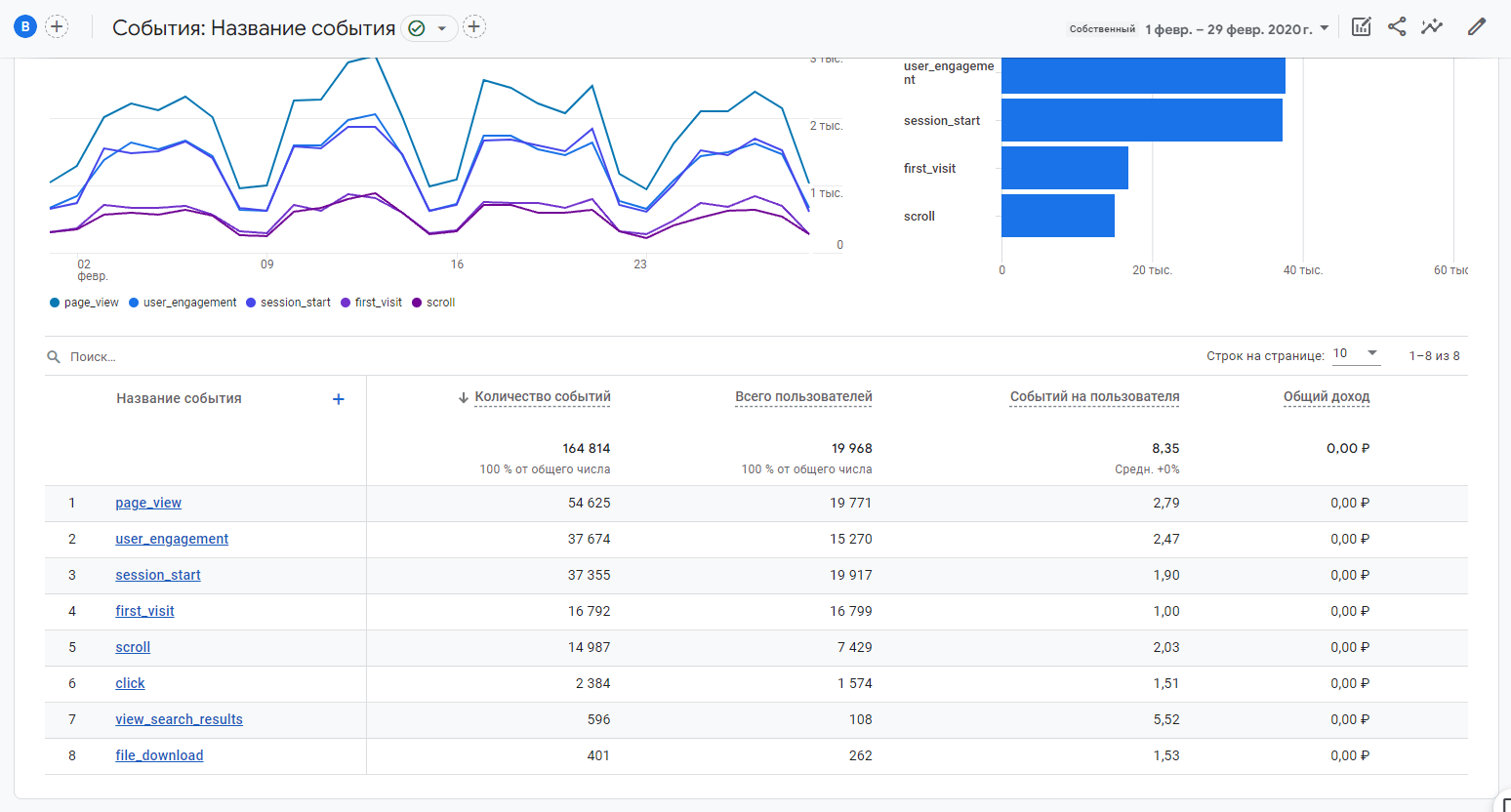
Пример стандартного отчета по событиям Google Analytics 4 (февраль 2020)
Настройки срока хранения данных и обновления информации о действиях пользователей применяются к данным на уровнях событий и пользователей. Однако некоторые данные с идентификаторами пользователей (возраст, пол, интересы и т.п.) по умолчанию удаляются системой через 2 месяца.
Вне зависимости от заданных настроек максимальное время хранения для данных в сигналах Google составляет 26 месяцев. По умолчанию срок хранения данных, связанных со входом в систему Google, истекает спустя 26 месяцев, если не задан более короткий период.
Итого
В Google Analytics 4 существуют ограничения по сроку хранения данных, и они достаточно жесткие:
- для связывания действий с определенным идентификатором пользователя и его событиями устанавливаются значения 2 или 14 месяцев (для Google Analytics 4 линейки 360 - срок хранения увеличен до 50 месяцев);
- срок хранения данных не учитывается в стандартных (агрегированных) отчетах. Эта настройка распространяется только на отчеты в инструменте Исследования и отчеты по последовательностям;
- изменение срока данных влияет на уже собранные данные. Новый срок хранения начинает действовать через 24 часа после его выбора;
- данные о поле, возрасте и интересах всегда хранятся два месяца, независимо от заданных вами настроек;
- вне зависимости от заданных настроек максимальное время хранения для данных в сигналах Google составляет 26 месяцев;
- для увеличения срока хранения всех данных, которые собрал для вас Google Analytics 4, рекомендуется использовать Google BigQuery.
Вы должны не забывать все эти ограничения и учитывать их при работе с рекламными кампаниями в Google Ads и других инструментах, а также при построении сквозной аналитики, где фактор пользователя и его идентификатора (Client ID/User ID) крайне важен.
Сигналы Google (Google Signals)
Подробнее:
Google Analytics 4 может использовать 4 разных типа идентификаторов, чтобы связать действия конкретного пользователя между разными устройствами, браузерами и платформами. Если вы перейдете в интерфейсе в раздел Способы идентификации, то увидите их все:
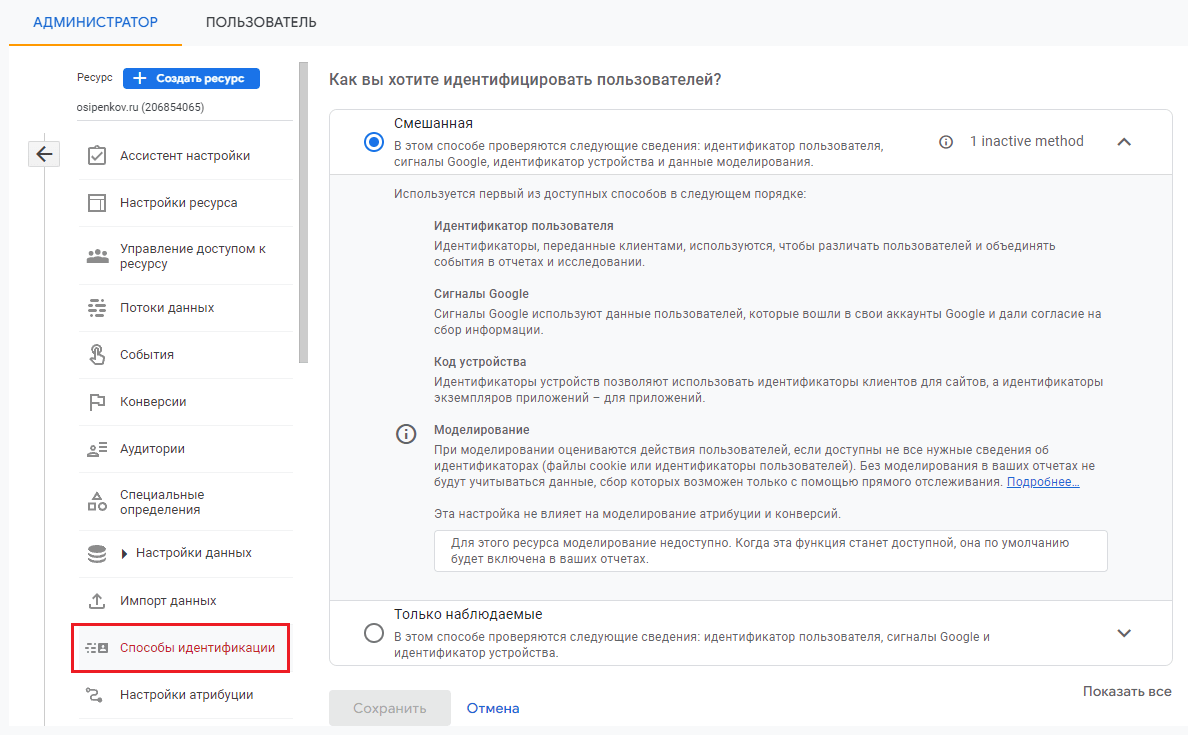
Способы идентификации пользователей в Google Analytics 4
В порядке приоритетности они идут так:
- когда пользователь инициирует событие на вашем сайте или в мобильном приложении, GA4 проверяет, есть ли у этого пользователя User ID;
- если идентификатор отсутствует, GA4 старается определить пользователей по сигналам Google;
- если сигналы тоже недоступны, GA4 идентифицирует пользователя по идентификатору устройства (Client ID для сайта и Instance ID для приложения);
- если пользователь вообще отказывается от отслеживания (используя режим согласия), запрещает сбор файлов cookie, то поведенческие данные о нем станут недоступны, и тогда в дело вступает так называемое Моделирование. В этом случае система использует сведения о похожих людях, которые дали тому же ресурсу согласие на использование файлов cookie, чтобы смоделировать недостающую информацию. Другими словами, на основе тех данных о пользователях, что у GA4 есть, он моделирует недостающие сведения для тех пользователей, которые отказались предоставлять информацию о себе. Это и есть моделирование в самом простом смысле.
Примечание: в Google Analytics 4 используется смешанный способ идентификации по умолчанию (User ID -> сигналы Google -> Client ID -> моделирование).
Сейчас нас интересуют только сигналы Google. Настройка, включенная в интерфейсе GA4, позволяет на основе агрегированных данных о пользователях, использующих Персонализацию рекламы, создавать общую модель поведения на нескольких устройствах. При этом учитываются данные о пользователях, а не о сеансах. К этой информации относится местонахождение конечного пользователя, история поиска, история YouTube, а также данные с партнерских сайтов Google. Такие агрегированные анонимные данные используются для составления статистики о поведении пользователей на нескольких устройствах.
Для отслеживания действий на нескольких устройствах используются:
- устройства iOS;
- устройства Android;
- Google Chrome;
- браузер Google Chrome;
- другие браузеры;
- клиентские приложения, для работы с которыми требуется аккаунт Google;
- другие приложения, для работы с которыми требуется аккаунт Google.
То есть Google может на основе своей статистики по всей экосистеме и различным продуктам связать авторизацию пользователя в учетной записи Gmail в единый профиль, и склеивать его действия в одной карточке пользователя в GA4. Это позволит вам настроить свои рекламные кампании в Google Ads таким образом, что ваши объявления будут видеть пользователи, которые включили персонализацию рекламы -> улучшить работу ремаркетинговых кампаний.
Например, вы зашли с телефона в дороге под своей почтой Gmail, а затем с рабочего компьютера с той же почты -> Google это зафиксировал и объединил все данные у себя в системе. Он понимает, что по ту сторону экрана, скорее всего, находится один и тот же человек. Сигналы Google очень полезны, когда у вас нет возможности настроить User ID, но отслеживать действия пользователей на разных устройствах необходимо.
С помощью таких сигналов Google Analytics 4 связывает данные о событиях на вашем сайте со сведениями о пользователях, которые вошли в свои аккаунты Google и дали согласие на сбор данных. Благодаря интеграции между Google Signals и Google Analytics 4, все отчеты в GA4 предоставляют возможность анализировать действия пользователей с разных устройств.
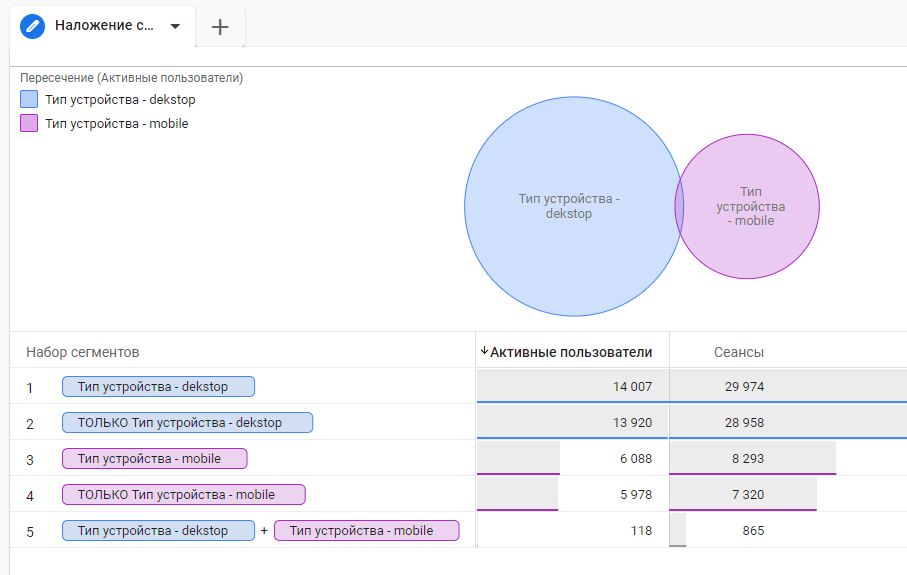
Пример пересечения аудиторий с разных устройств
Предполагая, что идентификатор пользователя и сигналы Google не реализованы, если человек просматривает ваш сайт в трех разных веб-браузерах, Google Analytics будет считать его тремя разными пользователями, а экспорт BigQuery будет иметь три отдельных идентификатора user_pseudo_id.
Но с активированными сигналами Google и человеком, вошедшим в свою единую учетную запись Google во всех трех браузерах, Google Analytics будет объединять данные в одного пользователя и показывать это количество в стандартных отчетах. Однако BigQuery по-прежнему будет отображать три отдельных идентификатора user_pseudo_id. Информация о сигналах Google недоступна в экспорте BigQuery. Таким образом, отчеты с данными Google Signals, скорее всего, будут иметь меньшее количество пользователей по сравнению с экспортом BigQuery.
Лучший способ уменьшить этот эффект — внедрить идентификаторы пользователей в свой ресурс GA4 вместе с активацией сигналов Google. Это гарантирует, что дедупликация произойдет сначала на основе user_id . Для зарегистрированных пользователей поле user_id будет заполнено в BigQuery и может использоваться для расчетов. Однако для пользователей, которые не вошли в систему (т.е. для сеансов без user_id), сигналы Google по-прежнему будут использоваться для дедупликации.
Включить сигналы Google в своем ресурсе Google Analytics 4 можно через Настройки данных - Сбор данных:
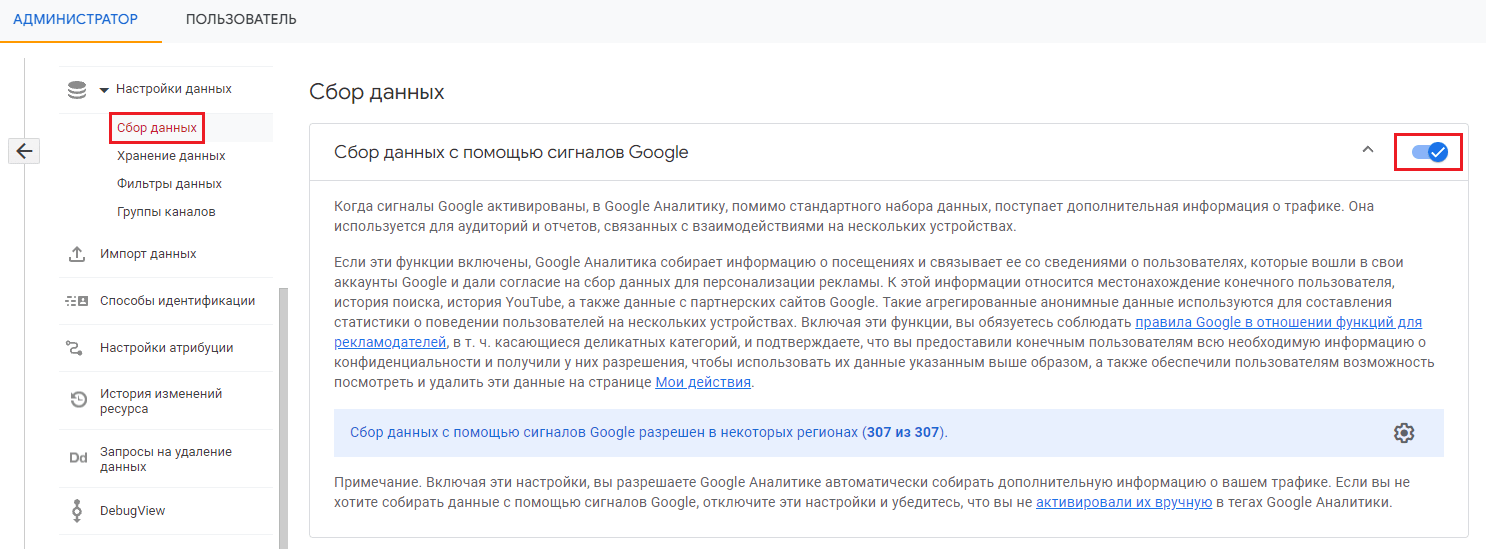
Сбор данных с помощью сигналов Google
Вы можете настроить сбор данных с помощью сигналом Google в разных регионах по-разному, в зависимости от регуляторов и местного законодательства, а где-то и вовсе отключить. Если сигналы Google включены, GA4 собирает данные во всех регионах. Если вы отключите сбор для конкретного региона, то Google Analytics перестанет собирать новые данные, но будет хранить ранее собранные сведения (они зависят от настроек). Если вы отключите сбор данных сигналов Google, у вас не будет доступа к межплатформенным отчетам, спискам ремаркетинга на основе данных GA4, функциям отчетов о рекламе, демографическим данным и категориям интересов.
Обязательно внизу подтвердите Согласие с условиями сбора пользовательских данных:

Согласие с условиями сбора пользовательских данных
Итого
Именно какой-то отдельной графы, что такие-то данные были собраны с помощью сигналов Google, в отчетах Google Analytics 4 вы не увидите. Но при их отключении в GA4 или изменении способа идентификации пользователей На основе устройства вы будете видеть больше данных на уровне пользователей, поскольку некоторые пороговые ограничения в ваших отчетах будут сняты. Подробнее об этом читайте ниже.
Google накладывает на функцию Google Signals определенные ограничения:
- активировав сигналы Google, вы получите подробные демографические данные о своей аудитории - пол, возраст, интересы;
- Google Signals позволяют использовать аудитории Google Analytics 4 в качестве аудиторий ремаркетинга в Google Ads (вы сможете показывать им более точную рекламу);
- сигналы Google не поддерживаются на устройствах с iOS 14+ и более поздних версий (Apple больше не поддерживает идентификаторы IDFA);
- чтобы данные сигналов Google отражались в отчетах, каждый месяц для ресурса должно регистрироваться в среднем 500 пользователей в день;
- вне зависимости от заданных настроек максимальное время хранения для данных в сигналах Google составляет 26 месяцев;
- в регионах, для которых вы отключите сигналы Google, ремаркетинг будет недоступен. Кроме того, в этих регионах будут значительно снижены объемы моделирования взаимодействий на разных устройствах и конверсий по заинтересованному просмотру. Это также повлияет на моделирование конверсий и отчеты в связанных аккаунтах Google Рекламы и Поисковой рекламы 360;
- данные могут быть удалены из отчетов или Исследования, если сигналы Google включены и у вас мало пользователей за указанный период;
- GA4 не экспортирует в BigQuery данные, связанные с сигналами Google, поэтому количество событий в Google Analytics и в BigQuery может быть разными;
- чтобы при просмотре отчета или Исследования нельзя было идентифицировать отдельных пользователей, к ресурсам, для которых включены сигналы Google, могут применяться пороговые значения. О них мы подробнее поговорим далее.
GDPR, TCF v 2.0, CMP, режим согласия, персонализация рекламы
Подробнее:
- Режим согласия Google
- Режим согласия Google и Cookiebot
- Новые настройки режима согласия в Google Tag Manager
- Включение и отключение функций для рекламодателей и персонализации рекламы
- CMP-платформа Cookiebot и Google Tag Manager
- Разблокировать теги Google при использовании режима согласия
- Правила использования функций Google Аналитики для рекламодателей
25 мая 2018 года в Евросоюзе вступил в силу общий регламент защиты персональных данных (General Data Protection Regulation, сокр. GDPR), который предоставляет резидентам Евросоюза (ЕС) возможность управлять своими персональными данными - спрашивать у компаний цель сбора и обработки информации, месте хранения, а в случае необходимости, сделать запрос на ее удаление. Под такие данные попадают IP-адреса, идентификаторы устройств, данные о местоположении и файлы cookie.
Другими словами, все компании, которые обрабатывают личные данные пользователей, находящихся на территории ЕС, обязаны соблюдать GDPR. И это вовсе не значит, что соблюдение регламента не распространяется на российские компании. Напротив, требования GDPR имеют отношения к компаниям в любой стране, деятельность которых направлена на физических лиц в ЕС.
Уверен, что вы стали чаще видеть на различных сайтах всплывающие окна такого типа:
Уведомление о том, что вы соглашаетесь со сбором ваших данных (файлов cookie)
Это плашка для пользователя с уведомлением о том, что вы, как владелец сайта, будете собирать его данные (его файлы cookie) для рекламных, аналитических и системных задач. Если пользователь соглашается со сбором данных, то вы имеете право фиксировать все его действия и отправлять эту информацию в сервисы Google (Google Analytics 4, Google Рекламу и т.д.), в том числе достижение конверсий. Если он отказывается (например, от персонализации рекламы), то вы не имеете права показывать ему рекламу и "бегать" за ним с объявлением "купи". В случае полного отказа от сбора всех данных вы вообще не имеете права согласно GDPR и TCF v 2.0 регистрировать его заходы на ваш сайт. Этого пользователя как бы нет в вашей статистике, поскольку идентификатор клиента (файл cookie _ga) не сохраняется в системе.
Вы должны надлежащим образом уведомлять конечных пользователей о том, какие функции Google Analytics 4 каким образом вы используете, в том числе о том, какие данные вы собираете и связываете ли вы их с другими доступными вам сведениями о конечных пользователях. Необходимо получить согласие конечных пользователей или предоставить им возможность отказаться от применения данных функций.
Google старается соблюдать законодательства тех стран, в которых он работает. И даже для этого изменяет функционал в своих сервисах. Например, в 2020 году был разработан режим согласия (Google Consent Mode), а чуть позже в Google Tag Manager появились дополнительные настройки для него. В Google Analytics 4 в разделе Настройки данных - Сбор данных добавили отдельную опцию персонализации рекламы Advanced Settings to Allow for Ads Personalization:
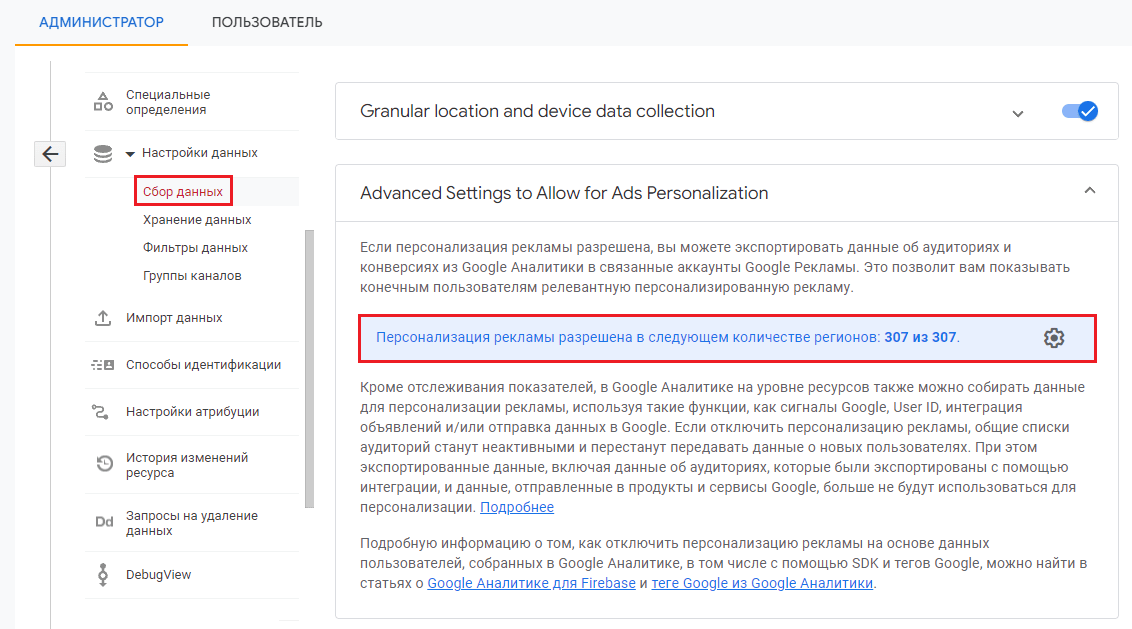
Персонализация рекламы
Эта настройка действует независимо от того, включены ли сигналы Google. Включение и отключение персонализации рекламы не влияет на сбор данных для сигналов Google. Если персонализация рекламы отключена для определенной страны или региона, то сигналы Google от пользователей из этого региона собираются только для отслеживания статистики, а не для персонализации рекламных объявлений в Google Ads.
Помимо этого Google Analytics 4 позволяет запретить персонализацию рекламы на основе отдельных событий или специальных параметров. После добавления такой пометки данные в GA4 будут использоваться только для статистики (не для ремаркетинга!), и их нельзя будет импортировать в Google Рекламу, Дисплей, Видео 360 и Поисковую рекламу 360. А аудитории, к которым относятся исключенные элементы, могут быть экспортированы в нерекламные продукты, например в Google BigQuery.
Для этого перейдите в раздел События и напротив нужного события справа нажмите на иконку трех точек, а затем добавьте пометку о неперсонализированной рекламе:
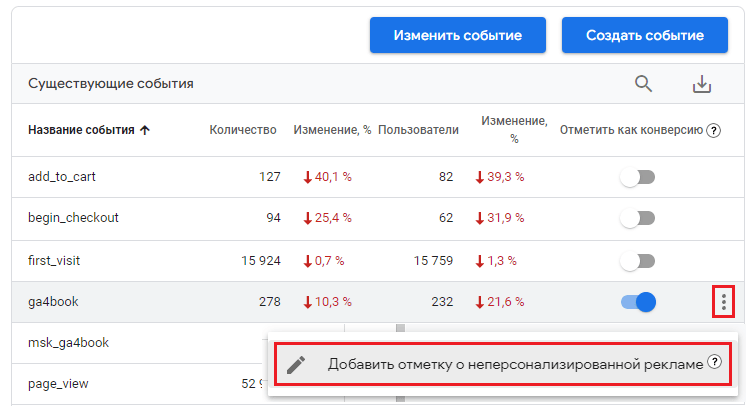
Отметка о неперсонализированной рекламе
Отдельные события и специальные параметры на уровне пользователя, исключенные из персонализации рекламы, можно экспортировать в рекламные продукты, но нельзя использовать в этих продуктах для персонализации. Отметка о неперсонализированной рекламе не влияет на данные, которые уже были экспортированы в Google Рекламу или Дисплей и Видео 360. Чтобы запретить или разрешить использование таких данных для персонализации в любом из этих сервисов, необходимо перейти в него. Показатели на основе событий, не связанных с персонализированной рекламой, такие как общая ценность, по умолчанию не рассматриваются как таковые. Настроить использование таких показателей можно только в Google Рекламе или Дисплее и Видео 360.
Итого
- Google трепетно относится к конфиденциальности и безопасности данных пользователей;
- для соблюдения законодательств разных стран были разработаны режим согласия и добавлены дополнительные настройки (персонализация рекламы);
- для упрощения создания уведомлений (плашек на сайте) и внедрения функционала сбора/отказа сбора данных были разработаны так называемые CMP-платформы.
IP, география и местоположение пользователей
Подробнее об определении местоположения пользователей в Google Analytics 4 читайте в этой статье.
Географические параметры, такие как город, страна, континент и т.д. (то есть местоположение) в Google Analytics 4 определяются на основе IP-адреса устройства пользователя. Полученные значения посетителя сопоставляются с информацией из базы данных по географическим идентификаторам, после чего в отчетах вы видите фактическое местоположение пользователя. Как вы понимаете, такой способ определения геоданных является приблизительным, поскольку ваш интернет-провайдер, вышки сотовой связи, браузеры и даже ваш антивирус могут изменять/переопределять или скрывать ваш IP-адрес. А он, в свою очередь, может отличаться от фактического IP-адреса. Другими словами, Google Analytics думает, что ваш IP-адрес - это IP 123, который находится в Нижнем Новгороде, а на самом деле вы делаете покупки на сайте в Москве и ваш настоящий IP-адрес XYZ.
Google Analytics предоставляет приблизительные данные о местоположении, выводя из IP-адресов следующие метаданные:
- город (и его географическую широту и долготу);
- континент;
- страну;
- регион;
- субконтинент (и соответствующие идентификаторы).
Помимо этого, значения стандартных географических параметров локализуются на язык пользователя. Это может усложнить обмен географическими данными с теми, кто говорит на других языках или работает с другими инструментами. Именно поэтому в отчетах аналитики вы видите определенные аномалии по обращениям из городов, на которые вы либо не настраивали рекламу (не таргетировались), либо вообще не имеете каналы сбыта и свою аудиторию.
При сборе данных Google Analytics 4 не регистрирует и не сохраняет IP-адреса. Прежде чем регистрировать данные о пользователях из Европейского союза (ЕС) через размещенные в ЕС домены и серверы, Google Analytics исключает из них все IP-адреса. Также в разделе Настройки данных - Сбор данных вы можете активировать или деактивировать опцию сбора подробных данных о местоположении и устройстве пользователей (Granular location and device data collection):
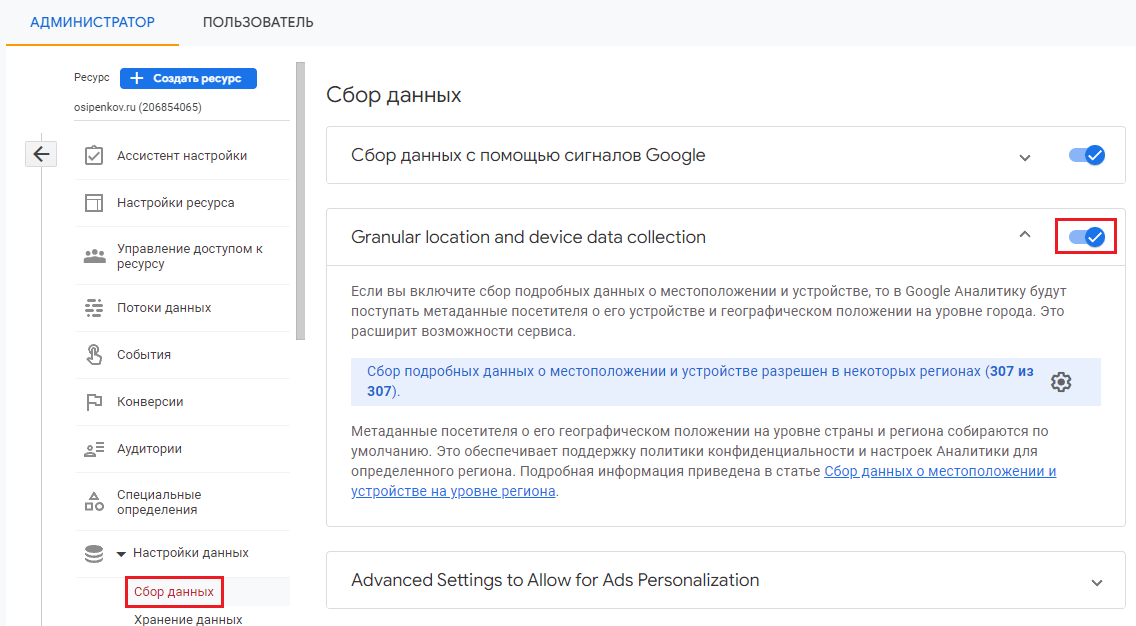
Сбор подробных данных о местоположении и устройстве пользователей
Если вы включите сбор подробных данных о местоположении и устройстве, то в Google Analytics 4 будут поступать метаданные посетителя о его устройстве и географическом положении на уровне города. Это расширит возможности сервиса. Метаданные посетителя о его географическом положении на уровне страны и региона собираются по умолчанию.
Если вы отключите его, GA4 не будет собирать следующие данные:
- город;
- широта расположения города;
- долгота расположения города;
- промежуточная версия браузера;
- строка User-Agent браузера;
- бренд устройства;
- модель устройства;
- название устройства;
- промежуточная версия операционной системы;
- промежуточная версия платформы;
- разрешение экрана.
Итого
- Google Аналитика 4 не регистрирует и не сохраняет отдельные IP-адреса;
- IP-адрес считается личной информацией (PII) в соответствии с действующими правилами конфиденциальности GDPR и CCPA, поэтому на него распространяются те же правила, что и на телефон, электронную почту и другие личные данные пользователя;
- географические параметры и местоположение пользователя в GA4 определяются на основе IP-адреса устройства пользователя, поэтому они могут быть неточными;
- для отслеживания данных пользователя на уровне города вам необходимо активировать функцию сбора подробных данных о местоположении и устройстве пользователей в интерфейсе GA4;
- если вы отключите сбор точных данных о местоположении и устройствах для региона, количество смоделированных конверсий в этом регионе значительно уменьшится. Это также повлияет на моделирование конверсий и отчеты в связанных аккаунтах Google Рекламы и Поисковой рекламы 360.
Правила использования загруженных данных
Подробнее:
- Импорт данных в Google Analytics 4
- Импорт данных о расходах в Google Analytics 4 на примере статистики Яндекс.Директа (ручной способ)
- Measurement Protocol
Функция импорта данных позволяет загружать данные из разных источников и объединять их со статистикой GA4. Она находится на уровне ресурса в разделе Импорт данных:
Импорт данных в Google Analytics 4
На данные, загруженные в Google Analytics 4 извне, распространяются следующие правила: Загружая данные в Google Analytics (через API либо вручную с помощью CSV-файлов или протокола Measurement Protocol), вы предоставляете сотрудникам Google и нашим партнерам по всему миру лицензию на их использование, размещение, хранение, воспроизведение и изменение, которая применяется исключительно для обеспечения работы службы Google Analytics, согласно ее Условиям использования. Вы должны обладать достаточными правами для предоставления такого разрешения, а также для использования данных в Google Analytics. Не загружайте никакие данные, позволяющие идентифицировать личность пользователя (имена, номера социального страхования, адреса электронной почты и т. п.) или отдельное устройство (например, уникальный идентификатор мобильного телефона, если его нельзя сбросить), даже в хешированной форме. Это относится и к User ID.
Если вы нарушите указанные выше правила, ваш аккаунт Google Analytics может быть закрыт, а все данные утрачены.
Правила в отношении цифровых отпечатков и локально сохраняемых объектов
При работе с Google Analytics запрещается использовать цифровые отпечатки устройств (fingerprints) и локально сохраняемые объекты (например, файлы cookie для Flash, вспомогательные объекты браузера и HTML5 localStorage), кроме файлов cookie HTTP и сбрасываемых идентификаторов устройств, предназначенных для сбора данных или показа рекламы.
Данные в отчетах недоступны за сегодня
Теперь давайте поговорим про ограничения в данных, которые уже Google обработал и отобразил в отчетах и Исследованиях.
Обычные отчеты имеют довольно длительную задержку перед отображением данных за текущий день. Если в Universal Analytics статистика по событию или конверсии могла отобразиться в отчетах в течение 15-20 минут после его совершения, то в Google Analytics 4 на это может потребоваться несколько часов или даже день. Хотя отчет В реальном времени и инструмент DebugView регистрируют действия пользователей практически мгновенно.
Если статистика в стандартных отчетах за сегодняшний день неполная:
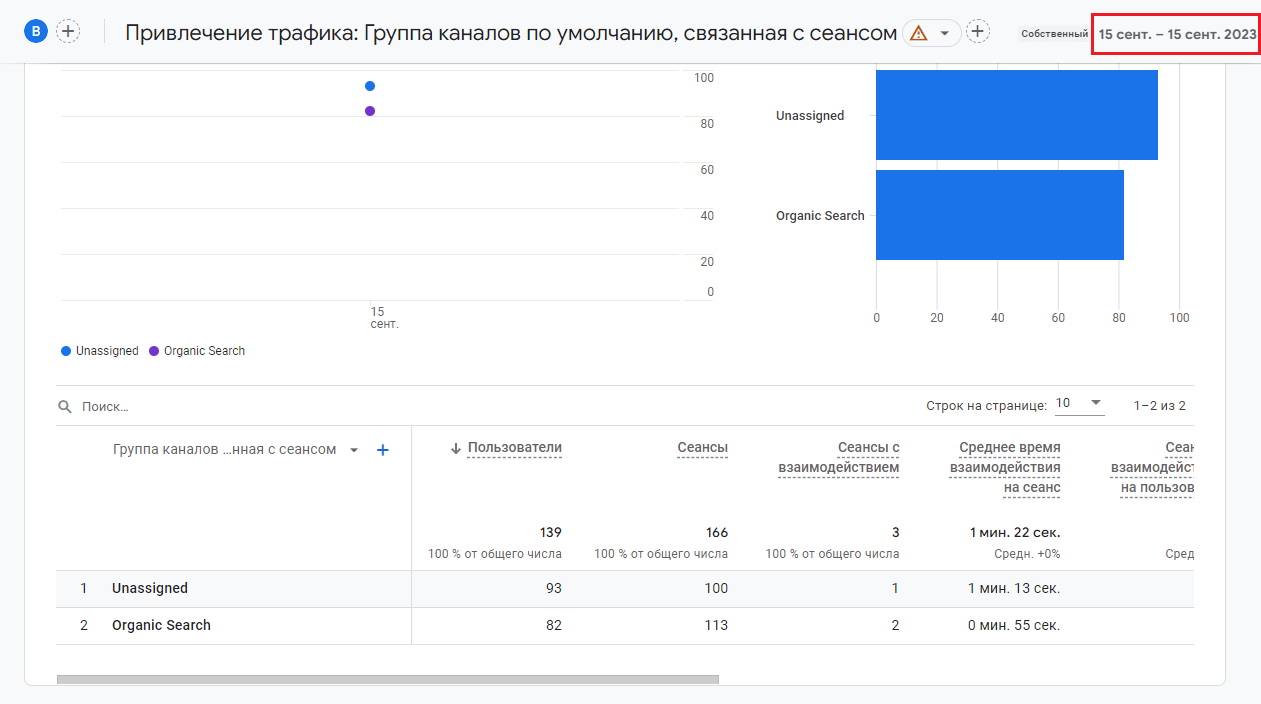
Неполная статистика в стандартных отчетах за сегодня
То в Исследованиях вы в принципе не можете выбрать сегодняшний день:
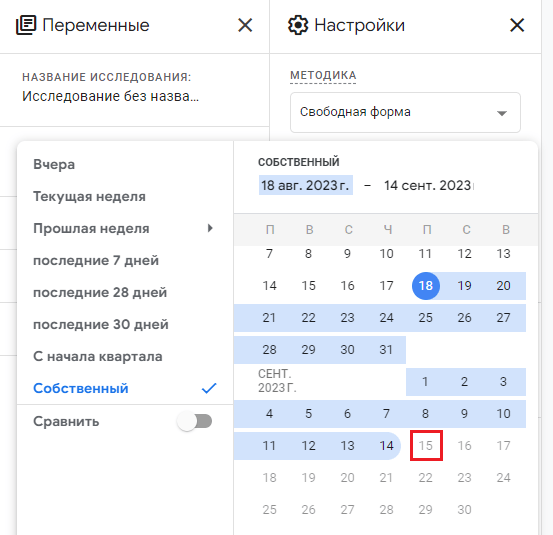
В Исследованиях нельзя выбрать сегодняшний день
Это как раз связано с процессом обработки данных, а также специальными ограничениями, установленными Google. Во-первых, в Google Analytics аналитика строится не вокруг сеансов (сессий), а вокруг событий. А согласно официальной справке Google, данные о новых событиях появляются в отчете в течение 24 часов. Иногда срок может увеличиваться до 48 часов. Во-вторых, в Исследованиях используются необработанные данные на уровне пользователей и событий, тогда как в стандартных отчетах GA4 используются ежедневные агрегированные таблицы.
Другими словами, над статистикой в стандартных отчетах уже были совершены определенные действия. Как правило, это простые арифметические операции - сложение, вычитание, умножение и деление. То есть над ними поработали за вас. А вы в отчетах видите уже готовые, обобщенные наборы данных, посчитанные заранее. А в Исследованиях каждое построение, каждое изменение диапазона дат, добавление параметра или показателя, наложение сегментов на отчет и т.п. сопровождается новым запросом к серверам Google и получению статистики "на лету". А для этого у Google уже должны быть все эти данные.
Ну и, в-третьих, хранение данных - это дорого. Да, Google Analytics 4 - бесплатный сервис, и его используют миллионы сайтов по всему миру. Хранить и обрабатывать такое количество информации даже для международной корпорации накладно. Именно поэтому GA4 можно назвать условно-бесплатным инструментом, поскольку Google всеми силами пытается "подсадить" вас на хранение данных в Google BigQuery/Google Cloud, в котором взимается плата. Зато там вы сможете получить доступ к необработанным данным на уровне пользователя и событий практически в реальном времени, даже за текущий день, а также целый ряд дополнительных преимуществ работы с сырыми данными. Или же, в случае больших организаций, переход на версию Google Analytics 360.
В связи с текущими событиями в мире Google приостановил работу Google Cloud Plaftorm для пользователей из России. На момент публикации этой статьи вы не сможете привязать свою банковскую карту, выпущенную на территории РФ. Наиболее простое и эффективное решение - выпустить карту другой страны (Казахстан, Киргизия, Армения и т.д.), чтобы иметь возможность полноценно пользоваться Google BigQuery без каких-либо ограничений по сроку жизни таблиц и оплачивать счета.
Задержка сбора данных
Теперь вы знаете про задержку отображения данных в отчетах по событиям, составляющую 24-48 часов. Но это еще не все. Поскольку в Google Analytics 4 вы можете отправлять свои собственные данные извне (офлайн-события) с помощью Firebase SDK или Measurement Protocol, то для обработки такого рода событий Google нужно еще некоторое время. В таком запросе вы можете использовать временную метку timestamp_micros, которая должна находиться в пределах 72 часов с момента регистрации события. Если ее не указывать, то отправляемое офлайн-событие будет записано в момент его загрузки.
Из-за этого окна в 72 часа Google может обновлять и пересчитывать свои табличные данные в интерфейсе. Поэтому когда вы заходите в отчеты и видите одни данные, а через некоторое время в тот же самый день - другие, то не удивляйтесь. Вероятно, это связано с задержкой данных и пересчетом таблиц ежедневного экспорта с учетом этих 72 часов. В этот момент данные в интерфейсе Google Analytics 4 и в вашем проекте Google BigQuery могут отличаться.
Специальные события не отображаются в стандартных отчетах
Для некоторых это может показаться удивительным открытием, но так оно и есть. И подтверждению этому - небольшая сноска в официальной справке Google, в которой написано следующее:
Специальные события вы создаете и полностью настраиваете сами. Это следует делать, только если вы не можете найти подходящих готовых событий. Данные специальных событий не включаются в большинство стандартных отчетов, поэтому вам также нужно будет настроить специальные отчеты или исследования.

Данные специальных событий не включаются в большинство стандартных отчетов
Поэтому ситуация, при которой в стандартном отчете по событиям вы будете видеть только автоматически регистрируемые, рекомендуемые и события улучшенной статистики, и не видеть специальные события - не редкость. Они могут отображаться в отчете В реальном времени, в DebugView, в BigQuery, но в разделе Отчеты - Взаимодействия - События вы не будете их видеть.
Вот такая статистика может отображаться в стандартном отчете:
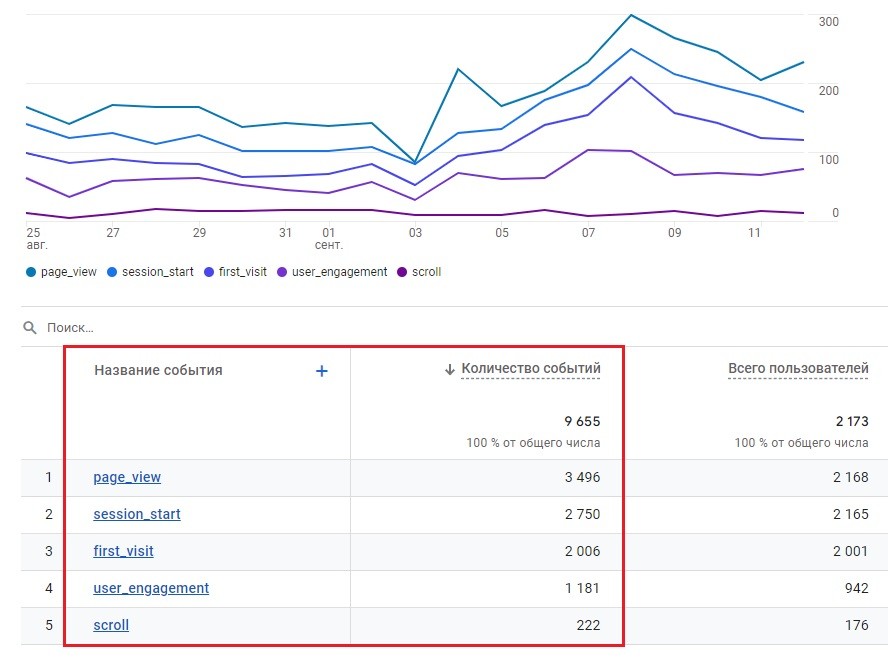
События в стандартном отчете
Как видите, в нем представлены только автоматически регистрируемые события и событие scroll из улучшенной статистики. А в Исследовании данных по событиям за тот же самый диапазон дат представлено гораздо больше:
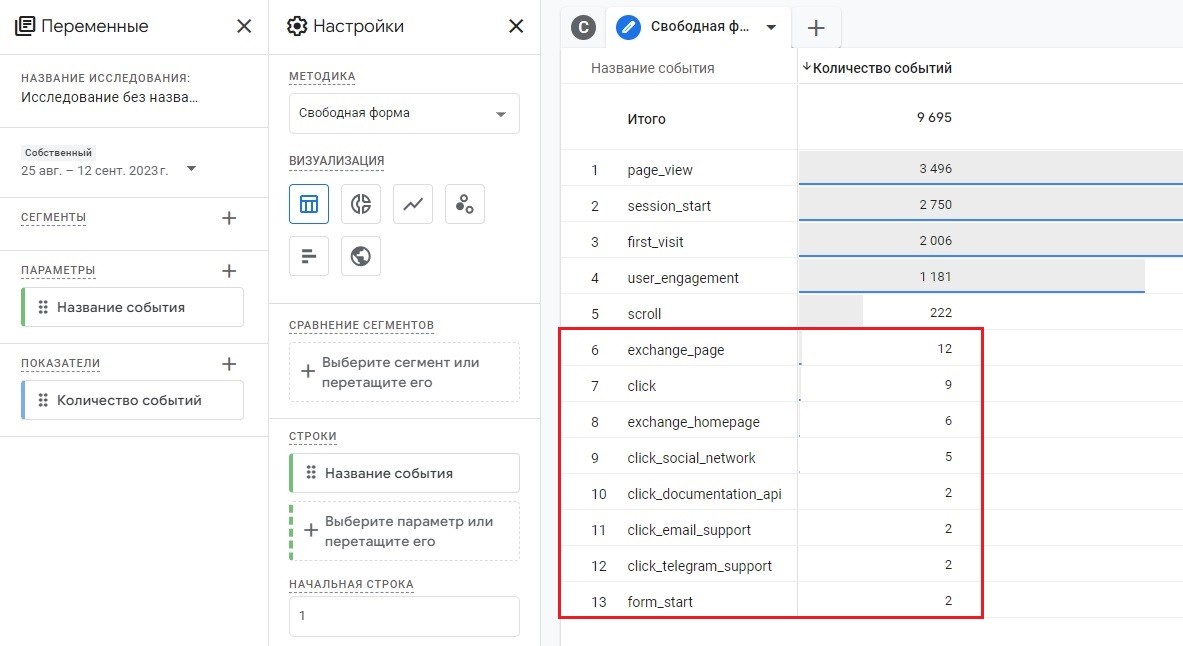
События в Исследовании
И в нем отображаются настроенные вами специальные события. Таким образом, мы подтвердили малоизвестный, но все же упоминаемый в официальной документации факт - специальные события не включаются в большинство стандартных отчетов Google Analytics 4.
Качество данных
Подробнее о качестве данных написано в официальной справке Google.
Рядом с каждой карточкой, отчетом и Исследованием в GA4 присутствует значок качества данных. Он отображается в заголовках отдельных отчетов:
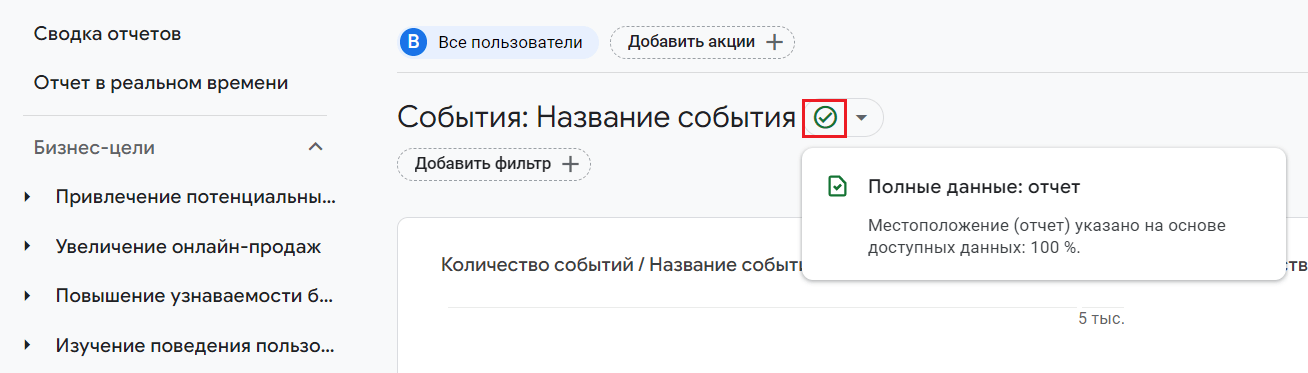
Значок качества данных в названии отчета
В правом верхнем углу каждой карточки обзорного отчета:
Значок качества данных в углу сводной карточки в обзорном отчете
И в Исследованиях:
Значок качества данных в Исследованиях
Всегда при анализе полученных данных обращайте внимание на этот значок, потому что в зависимости от его отображения на вашу статистику накладываются различные ограничения. Например:
- Зеленая иконка с галочкой - показываются все доступные данные (100%). Полный отчет, который создан на основе анализа всех доступных данных;
- Восклицательный знак в треугольнике - показывается часть доступных данных. Это означает, что на отчет установлены пороговые ограничения;
- Восклицательный знак в кружке - показывается маленький процент доступных данных, которые относятся к выбранным параметрам и показателям. Это означает, что ваше Исследование построено с ограниченном количеством данных и может содержать не очень точные сведения.
Для диапазона дат показаны неполные данные
В стандартных и специальных отчетах вам также может повстречаться такое уведомление - Для диапазона дат показаны неполные данные. В этом отчете содержатся данные, начиная с ....
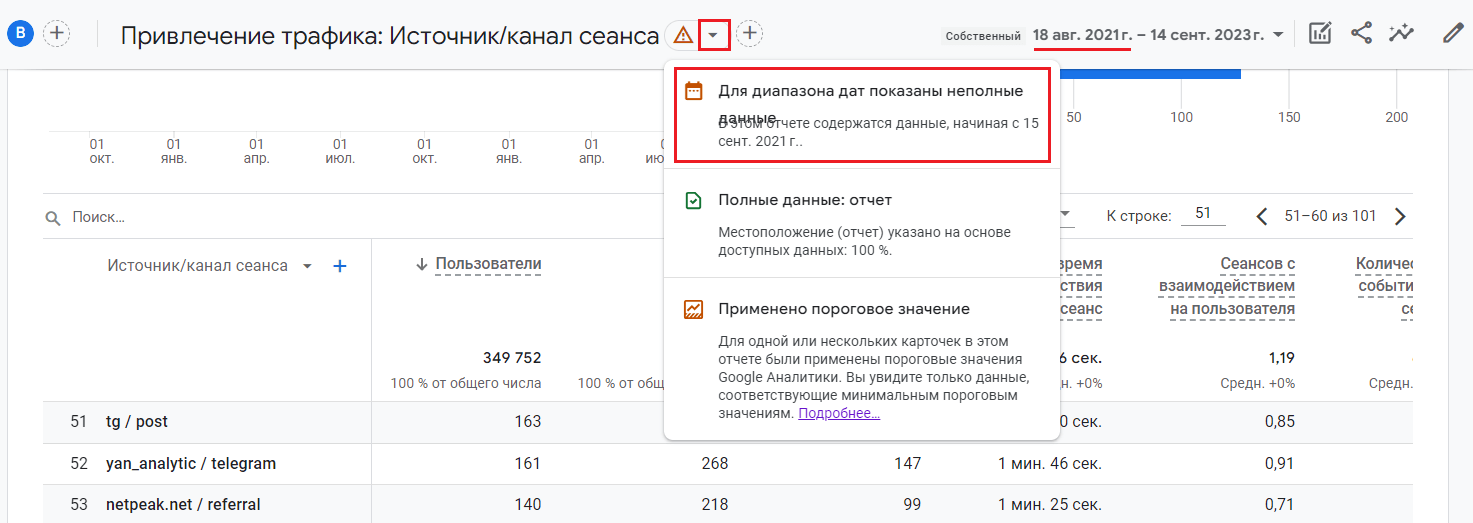
Для диапазона дат показаны неполные данные
Это как раз связано с тем, что выбранный для отчета диапазон дат превышает срок хранения данных о событиях ресурса, установленный в разделе Настройки данных - Хранение данных (см. выше). Чтобы устранить проблему, измените диапазон дат, используя дату начала, указанную рядом с этой надписью.
Пороговые значения
Подробнее:
Google Analytics 4 может удалять из ваших отчетов и Исследований некоторые данные, если их объем не соответствует пороговому значению. Об этом свидетельствует оранжевый восклицательный знак рядом с названием отчета и надпись Применено пороговое значение:
Применено пороговое значение
Этот индикатор также позволяет понять, когда к вашим данным применяется выборка. Подробнее рассмотрим ниже.
Аналогично и в Исследовании:
Пороговые значения в Исследованиях
Что самое страшное - пороговые значения определяются системой, их нельзя изменять. Никто не может точно сказать когда они будут применены, а когда нет. Черный ящик... Просто поймите и простите Google.
Но когда точно могут применяться пороговые значения? Конечно, когда данных мало или когда вы один на сайте что-то тестируете. Например, вы только создали сайт, установили на него счетчик Google Analytics 4 и пытаетесь настроить различные отслеживания. Вы видите, как все корректно отображается в отчете В реальном времени и инструменте DebugView. Однако спустя 24 часа ваши данные так и не появились в отчетах. Это как раз может быть связано с пороговыми значениями - система идентифицировала конкретно вас. И пока на вашем сайте мало данных, GA4 скрыл информацию о конкретном пользователе и всех его действиях.
Google применяет пороговые значения, чтобы при просмотре отчета или Исследования нельзя было идентифицировать отдельных пользователей на основе возраста, пола, категорий интересов и сигналов Google, так как по этим косвенным данным теоретически можно установить личность человека. Как? Не знаю, но Google так считает. Если, конечно, только не передавать дополнительные идентификаторы или данные, позволяющие идентифицировать пользователя с использованием localStorage или fingeprints. Однако это запрещено политикой Google.
Другой пример, когда применяются пороговые значения - это когда включены сигналы Google (Google Signals). По умолчанию в вашем ресурсе Google Analytics 4 они отключены. Но после их активации вы будете чаще наблюдать иконку Применено пороговое значение и в стандартных отчетах и Исследованиях. Достоверно точно неизвестно от какого числа пользователей применяются пороговые значения, поскольку Google официально не раскрывал эту цифру (лишь то, что они определяются системой и на них нельзя влиять), но на некоторых зарубежных сайтах, в том числе в блоге analyticsmania.com фигурирует число 50 пользователей/событий. Опровергнуть или подтвердить это невозможно, просто берем 50 за точку отсчета. Хотя я встречал и значение 37.
Поэтому, если вы просматриваете отчет (например, по источникам трафика) и некоторые источники трафика привлекли менее 50 пользователей за выбранный диапазон дат, в интерфейсе GA4 эти данные будут скрыты. Но они по-прежнему хранятся в базе данных на серверах Google, просто не отображаются в интерфейсе.
Примечательно, что проверив еще в нескольких ресурсах эту информацию, я также увидел 37:
Пороговые значения могут быть в диапазоне от 35 до 50 пользователей/событий (нижняя планка)
По всей вероятности, нижняя планка пороговых значений лежит в интервале от 35 до 50 пользователей/событий. Если будет ниже, то данные в отчетах скрываются.
Как избежать пороговых значений в Google Analytics 4? Самое простое - не включать сигналы Google в настройках ресурса. Если вы не планируете использовать демографические данные (страна, регион, город, язык, возраст, пол, интересы) и не планируете использовать аудитории GA4 для ремаркетинга в Google Рекламе, эта функция необязательна. Но если эта информация для вас важна и вы бы хотели скрыть надпись Применено пороговое значение, вам необходимо будет изменить способ идентификации пользователей в своем ресурсе.
Для этого перейдите в раздел Способы идентификации и нажмите кнопку Показать все:
Способы идентификации - Показать все
Вместо установленного варианта Смешанная или Только наблюдаемые, где для идентификации пользователей используются сигналы Google, вам необходимо выбрать вариант На основе устройства (Device-based) и сохранить изменения.
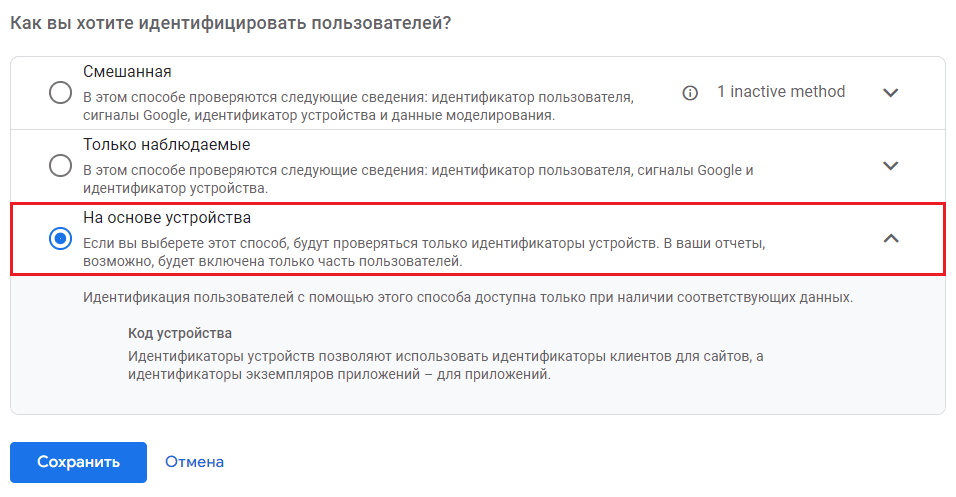
Идентификация пользователей на основе устройства
При таком способе Google будет ориентироваться только на уникальный идентификатор пользователя, взятый из основных файлов cookie браузера и устройства. Помните про _ga и Client ID? Вот это он и есть, только в переводе на русский язык в интерфейсе GA4 он называется Код устройства. Сигналы Google не будут использоваться для подсчета пользователей, и пороговое значение исчезнет.
Примечание: какой бы вариант вы ни выбрали, это не повлияет на сбор и обработку данных. Вы можете изменить способ идентификации в любой момент, и это не затронет сами данные.
Как только вы это сделаете, вы можете вернуться в стандартные отчеты и убедиться в том, что надпись Применено пороговое значение исчезла, а вместо нее отображается зеленая иконка с полными данными (отчет построен на основе 100% данных). В самом же отчете количество записей станет в разы больше, и вы сможете проанализировать статистику даже по одному пользователю:
Полные данные (100%) без пороговых значений
Таким образом, переключаясь между способами идентификации в любой момент, вы можете анализировать статистику как с пороговыми значениями, так и полные данные. Это решение поможет и тем, кто имеет сайты с низкой посещаемостью или только-только запустил свой проект и еще выполняет настройки отслеживания, проводит отладку без какого-либо продвижения. Однако не забывайте, что если на вашем сайте настроен User ID, то при выбранном способе идентификации На основе устройства он не будет учитываться, и данные будут менее точными.
Итого
- Google применяет пороговые значения, чтобы при просмотре отчета или Исследования нельзя было идентифицировать отдельных пользователей на основе возраста, пола, категорий интересов и сигналов Google;
- пороговые значения появляются когда включены сигналы Google. Об этом свидетельствует надпись Применено пороговое значение над отчетом;
- по наблюдением различных специалистов, нижняя планка пороговых значений лежит в интервале от 35 до 50 пользователей/событий. Если будет ниже, то данные в отчетах GA4 скрываются;
- чтобы убрать пороговые значения, отключите сигналы Google или в способах идентификации задайте вариант На основе устройства. Изменить обратно вы сможете в любой момент без влияния на сбор и обработку данных;
- создавая специальные события с включенными сигналами Google, вы можете убедиться, что применение пороговых значений не влияет на сбор данных. Для этого выберите в настройках способов идентификации вариант На основе устройства. Тогда GA4 будет использовать собственные файлы cookie. В отчетах о количестве пользователей пороговый объем данных для этих идентификаторов не применяется;
- если отчет или Исследование содержит демографические данные, а идентификация происходит На основе устройства, то строка с этими данными может быть удалена при недостаточном количестве пользователей;
- если отчет или Исследование содержит информацию о поисковых запросах, строка с этими данными может быть удалена при недостаточном количестве пользователей;
- пороговые значения могут применяться, если в отчете или исследовании задан узкий диапазон дат, за который не накопилось достаточного количества пользователей или событий. Расширив диапазон дат, вы сможете увеличить число пользователей, активировавших событие. Это позволит вам увидеть данные, которые ранее были недоступны из-за пороговых значений.
Выборка данных
Подробнее:
Помимо пороговых значений, в Google Analytics 4 есть выборка. Если пороговые значения применялись в случае активации сигналов Google и малого количества данных в ресурсе, то выборка, наоборот, применяется, когда в Исследовании содержится очень много данных.
В Universal Analytics (GA3) выборка применялась, когда вы использовали дополнительные параметры или сегменты в стандартных отчетах, при условии, что для этого было достаточно данных, а также при достижении лимита 500 тыс. сеансов на уровне ресурса для выбранного диапазона дат. Желтый значок в Universal Analytics рядом с названием отчета говорил о том, что к нему было применено семплирование:

Выборка данных в Universal Analytics
Семплирование (англ. Sampling) – метод выбора подмножества наблюдаемых величин из данного множества, с целью выделения неких свойств исходного множества. Иными словами, Google берет некоторую выборку данных, например, 10%, умножает ее на 10 и говорит нам, что так вели бы себя все 100%.
При работе с большими объемами данных все отчеты строятся быстро, нет никаких проблем с их загрузкой и отображением. А теперь представьте, что под такую выборку попала статистика по вашим рекламным кампаниям. В отчете на основе семплированных данных может быть показан доход 100 000 руб., а на самом деле за этот период он составил 150 000 руб.
В официальной справке Google приведен другой пример для лучшего понимания выборки данных: если вы хотите оценить количество деревьев на площади в 100 гектаров с более или менее равномерным распределением деревьев, можно подсчитать количество деревьев на одном гектаре и умножить на 100. Вы также можете подсчитать число деревьев на половине гектара земли и умножить его на 200. Это позволит определить количество деревьев на всей площади в 100 гектаров.
В стандартных отчетах Google Analytics 4 семплирование (выборка) не применяется, то есть нет никаких ограничений по количеству пользователей, сеансов и событий. Отчет показывает 100% данных независимо от того, какие фильтры и сравнения были использованы.
Полные данные в стандартных отчетах
В отчеты и в API Google Analytics 4 (Data API) GA4 загружает данные из заранее обработанных таблиц баз данных (агрегированная статистика). Например, отчет по целевым страницам содержит параметры показатели из соответствующей таблицы базы данных. Использование заранее обработанных таблиц позволяет Google Analytics быстро предоставлять данные.
А вот в Исследованиях дела обстоят иначе - там используются необработанные данные на уровне событий и пользователей, которые загружаются напрямую, не используя предварительно обработанные таблицы баз данных. За счет этого Google Analytics 4 может предоставить более подробные результаты, но для их загрузки может потребоваться больше времени.
Наверняка вы замечали, как при изменении диапазона дат, добавлении параметров или показателей, наложении сегментов на отчет и т.п. обновление отчета сопровождается новым запросом к серверам Google и получению статистики "на лету". Так работают Исследования.
Исследования используют необработанные данные и запросы выполняются "на лету"
Если количество событий, которые нужно обработать в Исследовании, превышает лимит квоты, GA4 использует репрезентативную выборку из доступных данных. А в правом верхнем углу вы увидите уведомление такого типа - Исследование с очень малой выборкой:
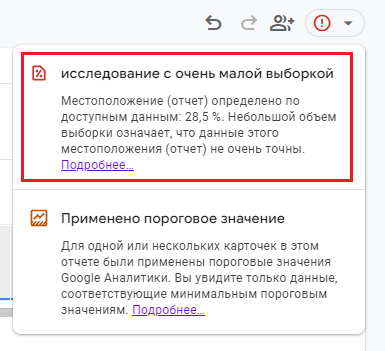
Исследование с очень малой выборкой
Лимит квоты составляет 10 млн событий для пользователей бесплатной версии Google Analytics 4 и 1 млрд событий для пользователей Google Analytics 360.
При работе с выборочными данными соотношение между общим объемом данных и размером выборки может влиять на точность результатов запроса. Обычно чем больше размер выборки (в процентах от общего объема данных), тем точнее результаты. Если размер выборки для Исследования слишком мал, попробуйте сократить диапазон дат, чтобы уменьшить объем данных, к которым применяется выборка. Это позволит получить более точные результаты.
Однако самый лучший способ справиться с выборкой данных - связать GA4 с BigQuery и работать с данными именно в облаке посредством SQL-запросов, а не в интерфейсе Google Analytics 4. Это позволит вам получить доступ к необработанным (сырым) данным, с которыми вы можете делать все, что хотите. Например:
- построить воронки на любых событиях, в том числе для электронной торговли;
- настроить передачу данных в режиме реального времени;
- создать различные карты (путей пользователей от страницы к странице, по событиям, по источникам трафика и т.д.);
- проанализировать возвращаемость пользователей, оценить удержание клиентов, построить когортный анализ;
- создать собственные модели атрибуции, группы каналов, построить ассоциированные конверсии;
- обогатить события на сайте данными из других систем, то есть реализовать сквозную аналитику, объединив информацию из разных источников;
- воссоздать любые базовые отчеты - посещаемость, по utm_меткам, популярные страницы и прочее;
- построить различные дашборды в Looker Studio (Google Data Studio)и связать статистику Google Analytics 4 с другими наборами данных вашей организации или вообще с данными, которые могут находиться вне вашей базы данных (например, объединение информации о ваших заказах с информацией о погоде, чтобы узнать, как дождь влиял на итоговое количество обращений и выручку компании);
- использовать модель машинного обучения BigQuery ML с целью прогноза будущих показателей.
HyperLogLog++ и кардинальность
Подробнее:
- Алгоритм HyperLogLog, или Оцениваем мощность множества за O(1)
- О расхождениях между интерфейсом Google Аналитики и данными экспорта в BigQuery
- Приближение уникального подсчета в Google Analytics
- Насколько точен HyperLogLog++ в GA4?
- HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm
- Damn Cool Algorithms: Cardinality Estimation
Вы хотите получить точные данные (или хотя бы одинаковые данные) в Google Analytics 4? Забудьте. Это утопия. Если вы видите разные данные в стандартных отчетах, специальных отчетах, Исследованиях, при выгрузке с помощью API и в Google BigQuery, то знайте - это нормально. И причина этому достаточна проста - так работают алгоритмы в GA4.
В апреле 2023 года в официальной документации разработчиков вышел очень любопытный материал о расхождениях между интерфейсом Google Аналитики и данными экспорта в BigQuery, который проливает свет на многие вопросы по этой части, но при этом поднимает и другие, не менее важные темы. Вам обязательно нужно его прочитать.
Идея заключается в том, что Google Analytics 4 использует вероятностный алгоритм HyperLogLog++ (Гиперлоглог++, HLL++), где ++ обозначает дополнения, внесенные в алгоритм HyperLogLog, который эффективно оценивает приблизительное количество отдельных значений в наборе данных. То есть когда вы просматриваете данные в интерфейсе или через API и хотите подсчитать уникальное количество каких-то показателей (пользователей, сеансов, конверсий, количество событий, транзакций и т.д.), вы будете видеть приблизительное, а не точное значение.
Примечание: HLL++ не является чем-то новым для GA4, он использовался и в предыдущей версии Google Analytics для подсчета пользователей, начиная с 2017 года. К тому же алгоритм HyperLogLog используется многими организациями, от небольших технологических компаний до таких гигантов, как Facebook, Twitter, Presto, Redis для быстрого и эффективного получения приблизительных оценок мощности для очень больших наборов данных (Big Data).
Это связано с тем, что для подсчета уникального количества элементов в множестве данных Google требуется куда больше вычислительных ресурсов. И чтобы снизить нагрузку на свои сервера, компания использует данный алгоритм измерения. HLL++ оценивает количество элементов, используя меньше памяти и повышая производительность, а затем отображает эти данные в интерфейсе GA4 с определенной погрешностью.
А вот если у вас настроена связь с Google BigQuery, то вы можете рассчитать значения показателей точнее интерфейсных. При этом данные в BigQuery и в интерфейсе Google Analytics 4 могут отличаться на небольшой процент. При доверительном интервале 95% точность подсчета сеансов может составлять ±1,63%. Для сеансов он менее точен, ±3,25%. Уровни точности будут различаться для разных показателей и будут меняться в соответствии с доверительными интервалами.
Для HLL++ существуют эскизы - конструкции, которые инкапсулирует информацию об отдельных значениях в наборе данных. Такие эскизы обеспечивают значительное повышение производительности при обработке запросов по вычислению приблизительной кардинальности больших наборов данных. Вычисление показателей с помощью эскиза существенно дешевле, чем вычисление точного значения. Если ваши вычисления выполняются слишком медленно или требуют слишком большого объема временной памяти.
Примечание: подсчет уникального количества пользователей или другой метрики без эскизов обычно возможен только путем выполнения запроса на необработанных данных (в BigQuery), поскольку уже агрегированные данные больше нельзя объединять.
В таблице ниже показаны поддерживаемые эскизами HLL++ значения точности, максимальный размер хранилища и доверительный интервал (CI) типичных уровней точности:
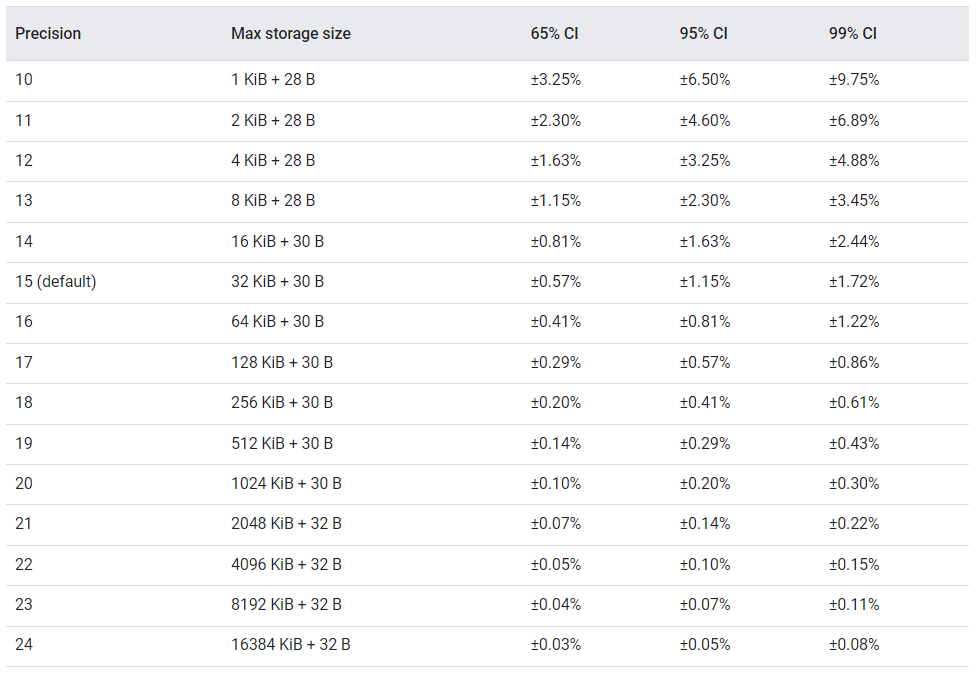
Эскизы HLL++
Как видите, при доверительном интервале 95% и точности подсчета ±1,63% значение точности равно 14.
Сам Google Analytics 4 использует следующую конфигурацию для измерения количества показателей:
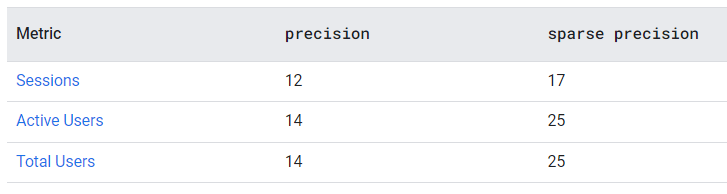
Значение точности для нескольких показателей Google Analytics 4
- Сеансы (Sessions) - precision 12
- Активные пользователи (Active Users) - precision 14
- Всего пользователей (Total Users) - precision 14
В HLL+ есть еще один параметр - sparse precision. В BigQuery его значение не определяется пользователем и фиксируется на уровне precision + 5.
Построив график по табличным данным, можно наблюдать такую картину:
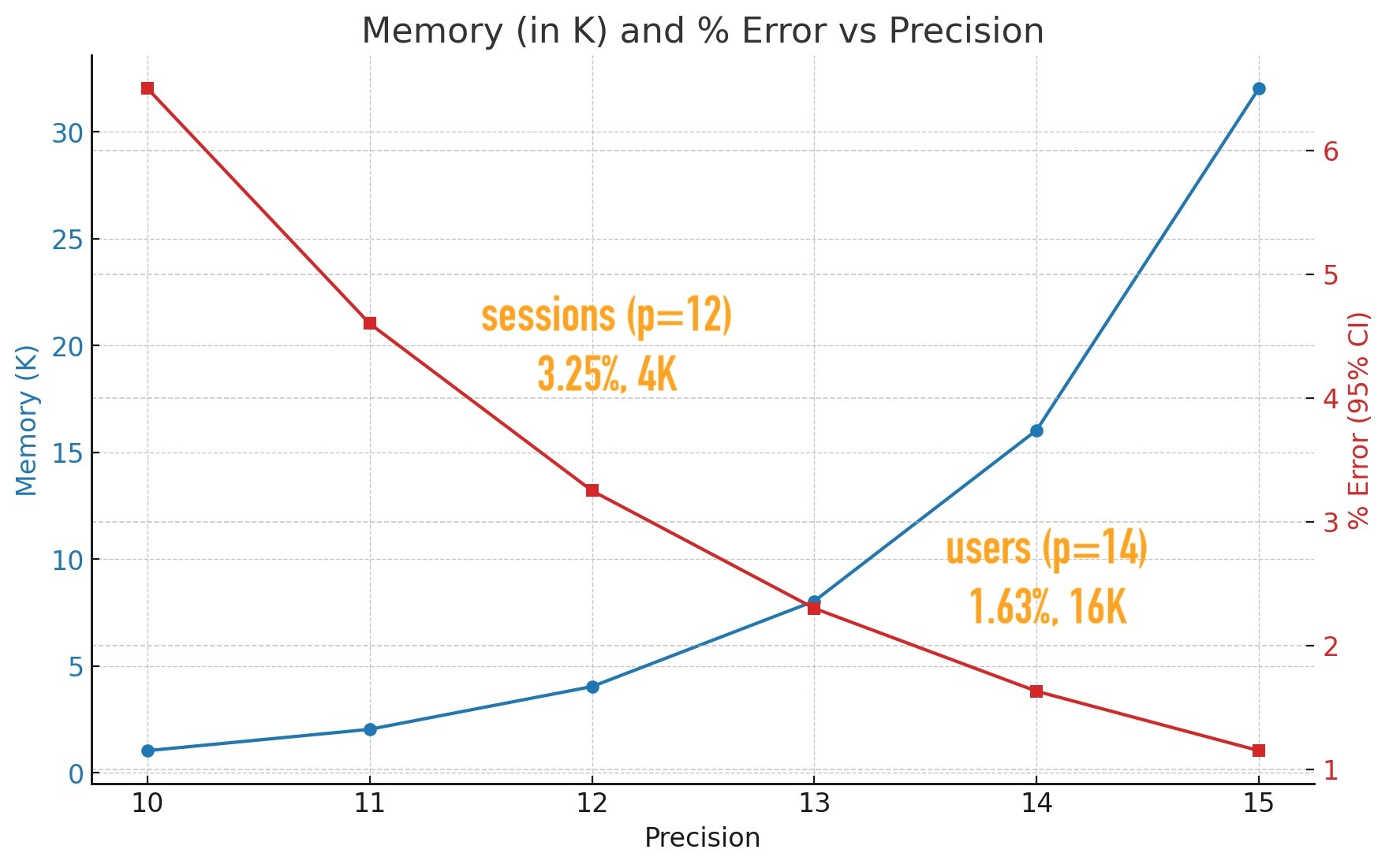
График зависимости точности от размера (quantable.com)
Здесь мы видим, что с увеличением настройки точности количество ошибок уменьшается, а объем используемой памяти увеличивается. Интересно отметить, что, хотя по умолчанию в BigQuery установлена точность (precision) 15, настройки в GA4 ниже - 12 для сеансов и 14 для пользователей. Это имеет смысл с точки зрения Google, поскольку они решили, что дополнительная точность в 0,5% не стоит удвоения размера хранилища с 16 КБ до 32 КБ… Оптимизация затрат, вычислительных ресурсов и производительности со стороны Google. Ничего личного, это просто бизнес (с).
Для чего я привел эти таблицы с эскизами и значения precision для некоторых показателей GA4? Чтобы продемонстрировать вам практически расхождения в интерфейсных данных и данных, экспортируемых в BigQuery, а также несколько запросов, с точным подсчетом и приблизительным результатом.
Итак, давайте построим отчет за 6 месяцев и подсчитаем уникальное количество пользователей (Total Users) с 3 января по 3 июля 2023 года. В стандартном отчете по событиям этот показатель равен 101 625:
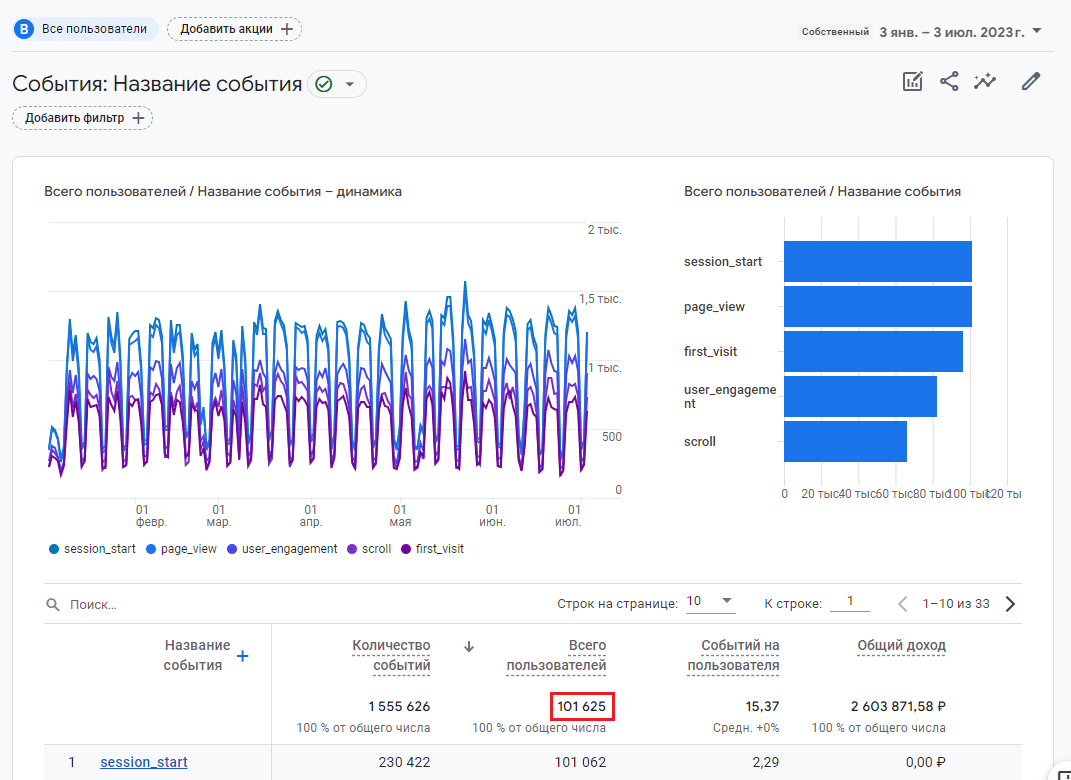
Всего пользователей за выбранный диапазон дат - 101 625
В Исследованиях за аналогичный период всего пользователей точно такое же число - 101 625:
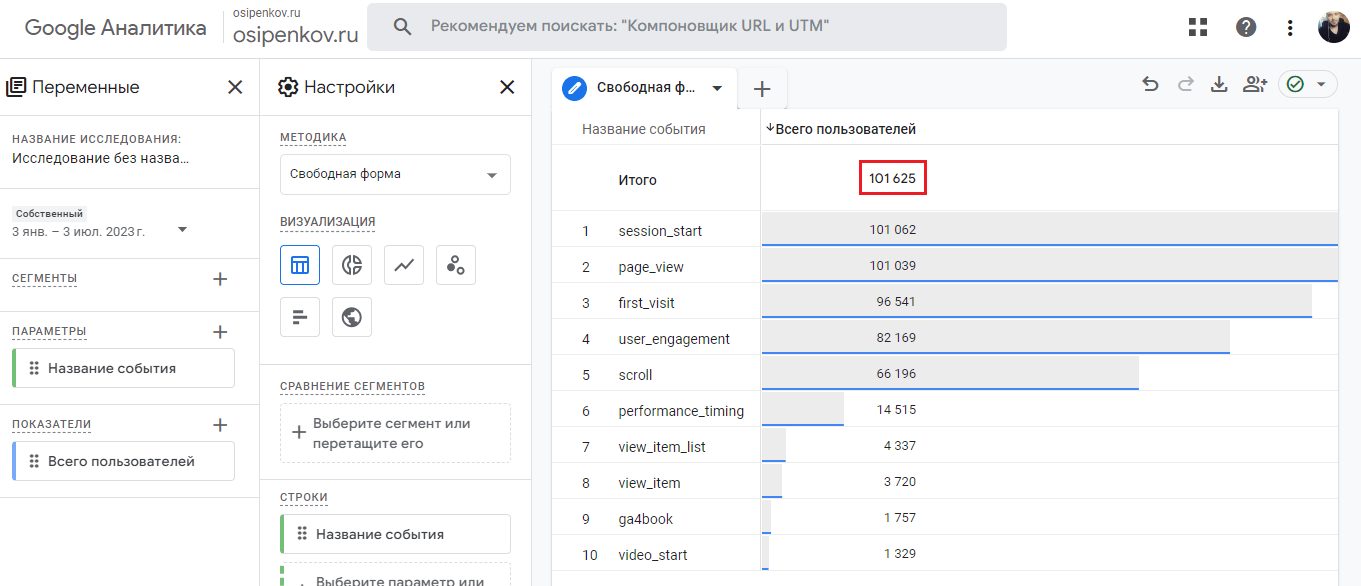
Всего пользователей за выбранный диапазон дат - 101 625
Еще у меня для проекта настроена связь с Google BigQuery. И при выполнении SQL-запроса подсчета количества пользователей за выбранный диапазон дат я могу пойти разными путями:
- использовать функцию COUNT(DISTINCT) для точного измерения числа пользователей. Этот подход требует больше памяти и требует больше времени для выполнения, особенно для больших наборов данных;
- использовать функцию APPROX_COUNT_DISTINCT, которая аппроксимирует результаты с помощью HLL++. Она не позволяет вам настраивать точность приближения;
- использовать функцию HLL_COUNT.INIT и значение точности precision в HLL++ из таблицы, которую я приложил выше.
Давайте рассмотрим каждый запрос в BigQuery и результат его выполнения.
Точный подсчет с помощью функции COUNT(DISTINCT) будет выглядеть так:
|
1 2 3 |
SELECT COUNT(DISTINCT user_pseudo_id) AS exact_total_user_count, FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*` |
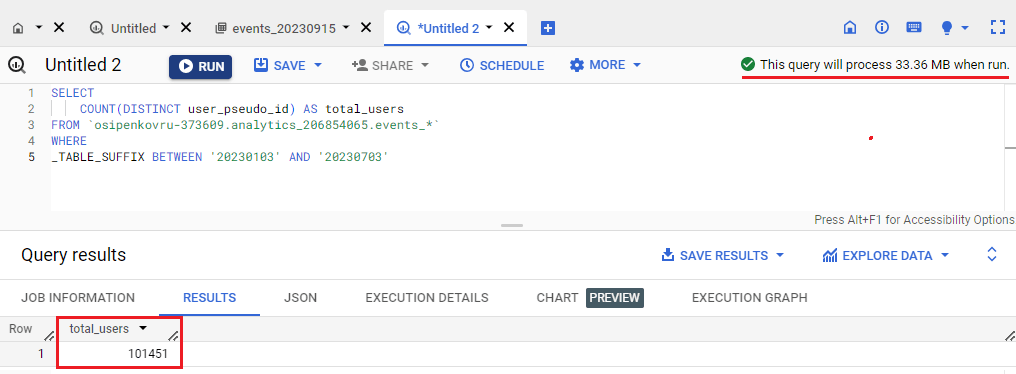
Точный подсчет пользователей в BigQuery с помощью COUNT(DISTINCT)
Как видите, количество пользователей в интерфейсе GA4 и BigQuery при точном подсчете отличается. Но процент расхождения допустимый - всего 0,17%. В моем счетчике в эти даты были активированы сигналы Google. А как вы уже знаете, GA4 не экспортирует в BigQuery данные, связанные с сигналами Google, поэтому количество событий в Google Analytics и в BigQuery может быть разными. Это связано с тем, что сигналы Google дедуплицируют полученные данные о событиях.
Другой способ - это использовать функцию APPROX_COUNT_DISTINCT для приблизительного подсчета:
|
1 2 3 |
SELECT APPROX_COUNT_DISTINCT(user_pseudo_id) AS approx_total_user_count, FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*` |
Для моего проекта в BigQuery SQL-запрос за выбранный диапазон дат даст следующий результат (размер запроса не изменится - 33,36 МБ, а количество пользователей составит 101 597):
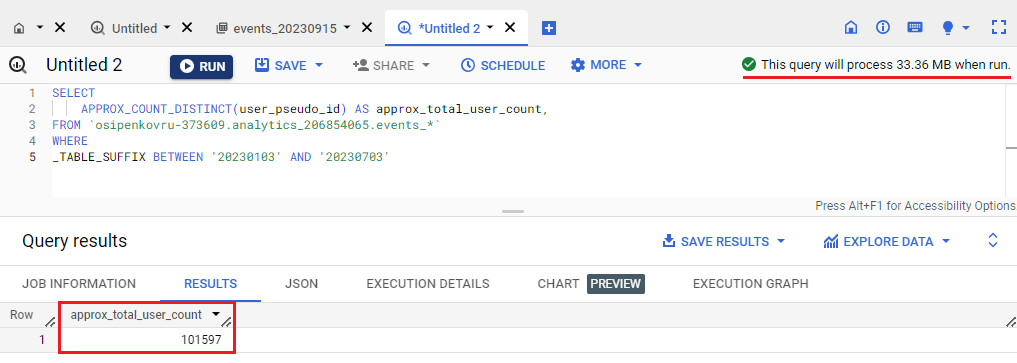
Подсчет пользователей в BigQuery с помощью APPROX_COUNT_DISTINCT
Процент расхождения при приблизительном подсчете еще меньше - всего 0,03%. В моем счетчике аналитики не так много данных, поэтому цифры при точном подсчете и приблизительном не сильно отличаются. Однако если в вашем проекте много статистики и миллионы пользователей и событий, то % расхождения будет больше, но не должен выходить за доверительный интервал, представленный в таблице выше.
Еще вы можете выполнить репликацию APPROX_COUNT_DISTINCT с помощью функций BigQuery HLL++. Это вернет идентичные или очень похожие результаты, как APPROX_COUNT_DISTINCT:
|
1 2 3 |
SELECT HLL_COUNT.EXTRACT(HLL_COUNT.INIT(user_pseudo_id, 15)) AS approx_total_user_count, FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_* |
Результат выполнения SQL-команды в BigQuery для моего проекта (размер запроса и количество пользователей не изменилось - 33,36 МБ и 101 597):
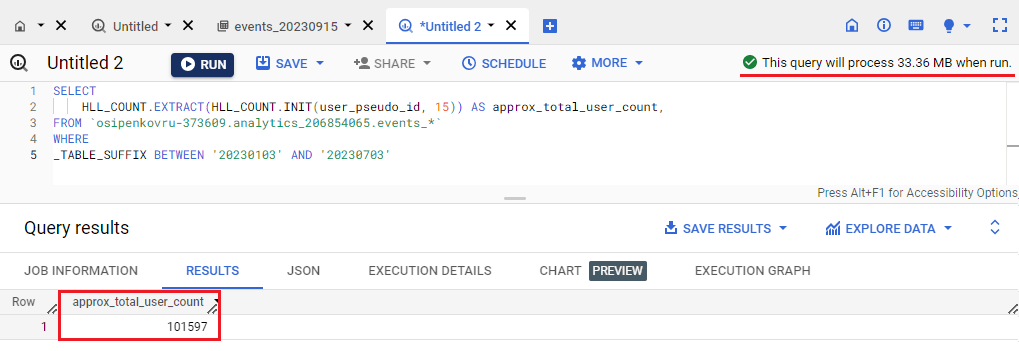
Подсчет пользователей в BigQuery с помощью функции HLL++
И, наконец, чтобы реплицировать данные в пользовательском интерфейсе Google Analytics, то есть сделать очень похожими данные в BigQuery с интерфейсом GA4, используйте функцию HLL++ и значение точности precision = 14:
|
1 2 3 |
SELECT HLL_COUNT.EXTRACT(HLL_COUNT.INIT(user_pseudo_id, 14)) AS total_user_count, FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_*` |
Результат выполнения SQL-команды в BigQuery для моего проекта с помощью функции HLL++ и задания точности 14 (размер запроса - 33,36 МБ):
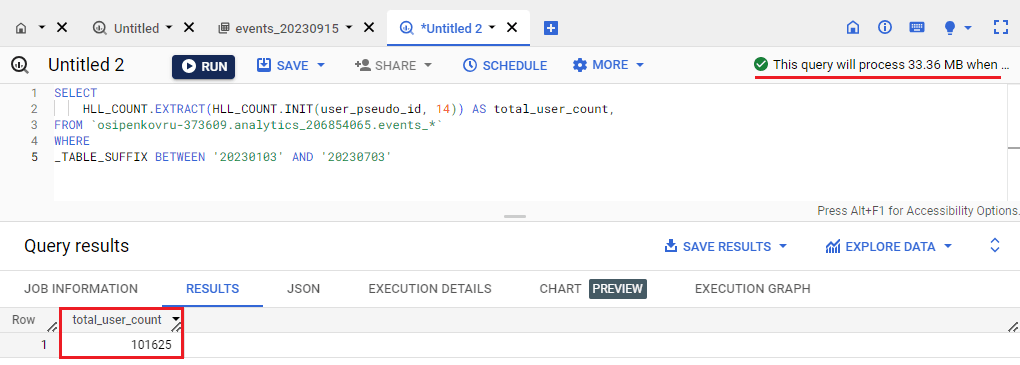
Подсчет пользователей в BigQuery с помощью функции HLL++ и указании точности (precision = 14)
Бинго! С помощью функции HLL++ и указании точности 14 мы добились 100% совпадения интерфейсных данных GA4 и табличных в BigQuery. Но опять же, здесь есть свои нюансы и об этом прописано в документации Google. Для подсчета пользователей Google Analytics использует sparse precision значение 25. Поскольку sparse precision значение BigQuery всегда равно precision + 5, по умолчанию будет установлено значение 19 (14+5). Таким образом, этот параметр не будет соответствовать пользовательскому интерфейсу Google Analytics при подсчете общего количества пользователей. Будет небольшая разница. У меня данные сошлись, потому что их не так много. Но у вас ситуация может быть другой.
Примечание: вы можете попробовать выполнить эти запросы для подсчета уникального количества пользователей самостоятельно для своего проекта, предварительно отключив в интерфейсе сигналы Google.
Это все? Разумеется, нет! Когда дело доходит до подсчета различных значений, то в Google Analytics 4 немаловажным фактором играет такое понятие, как кардинальность (cardinality). В контексте баз данных кардинальность относится к уникальности значений данных, содержащихся в столбце. Высокая мощность означает, что столбец содержит большой процент полностью уникальных значений. Низкая мощность означает, что столбец содержит много повторов в своем диапазоне данных. Если проще, высокая кардинальность - уникальные данные, низкая кардинальность - повторяющиеся данные.
Например:
- Пол - повторяющиеся значения, низкая кардинальность, поскольку значений пола всего несколько и они фиксированы - male, female и unknown;
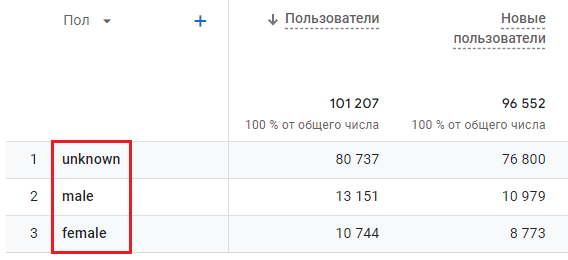
Пол - высокоповторяющиеся данные, низкая кардинальность
- Браузер - данные повторяются, но уже не так часто - средняя кардинальность;
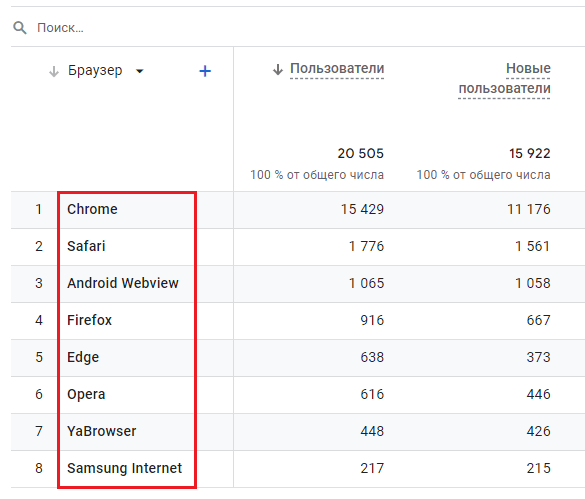
Браузер - среднеповторяющиеся данные, нормальная кардинальность
- Город - данные уникальны, высокая кардинальность, так как география пользователей очень обширна.
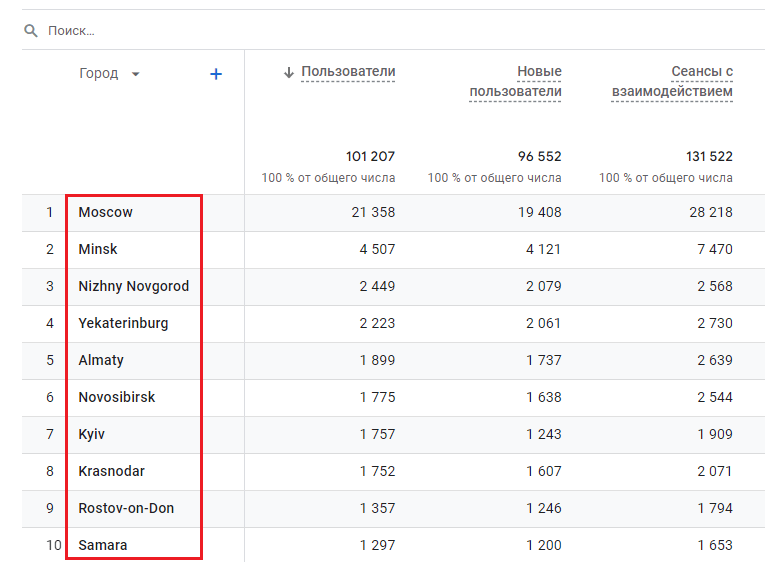
Город - много уникальных значений, высокая кардинальность
- Путь к странице - уникальных значений еще больше (на сайтах электронной торговли их может быть десятки и сотни тысяч), высокая кардинальность.
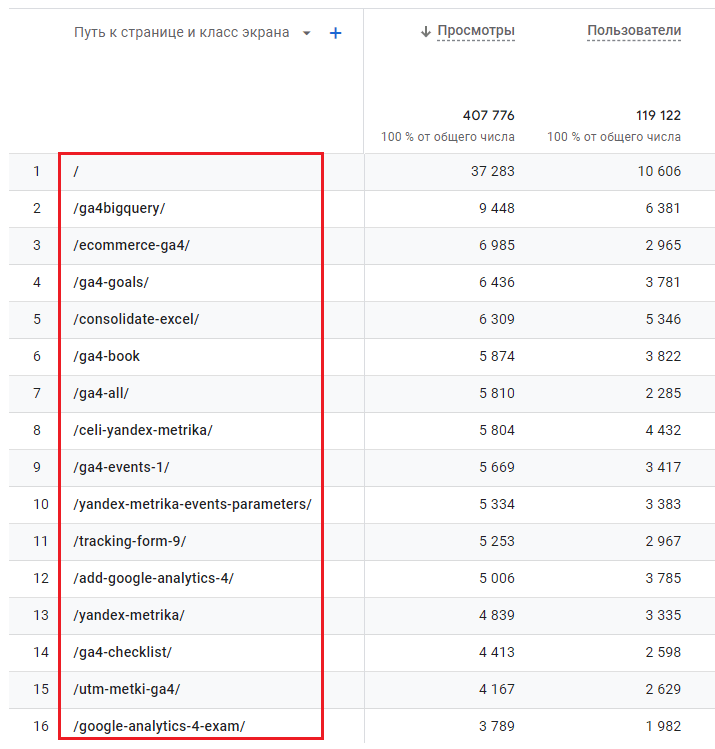
Путь к странице - еще больше уникальных значений, высокая кардинальность
Предположим, вы просматриваете стандартный отчет или выгружаете данные с помощью Data API. Он содержит большой объем данных и имеет параметры с высокой кардинальностью. Под высокой кардинальностью в Google Analytics 4 подразумеваются параметры, количество уникальных значений которых превышает 500. При наличии таких параметров может быть достигнуто максимальное количество строк в отчете, и тогда GA4 сгруппирует менее часто встречающиеся значения и отобразит их в строке (other).
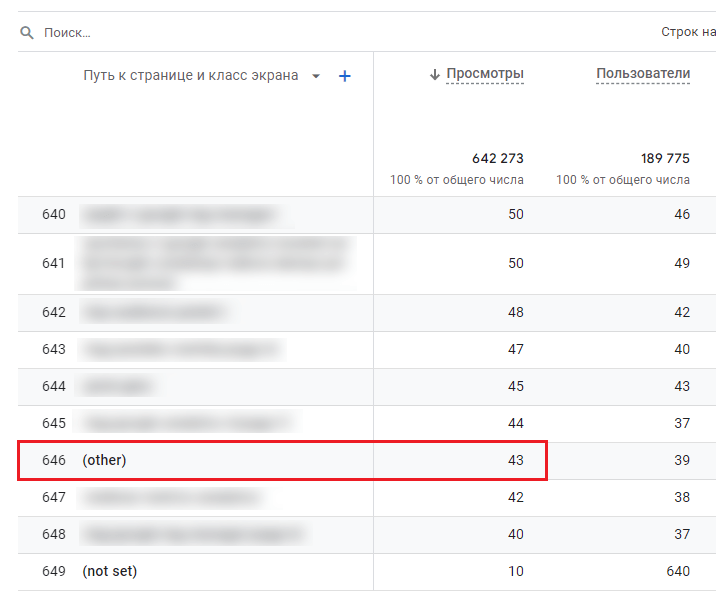
Строка (other) в стандартных отчетах
Такую строку вы иногда можете видеть в отчетах реального времени в мобильном приложении Google Analytics:
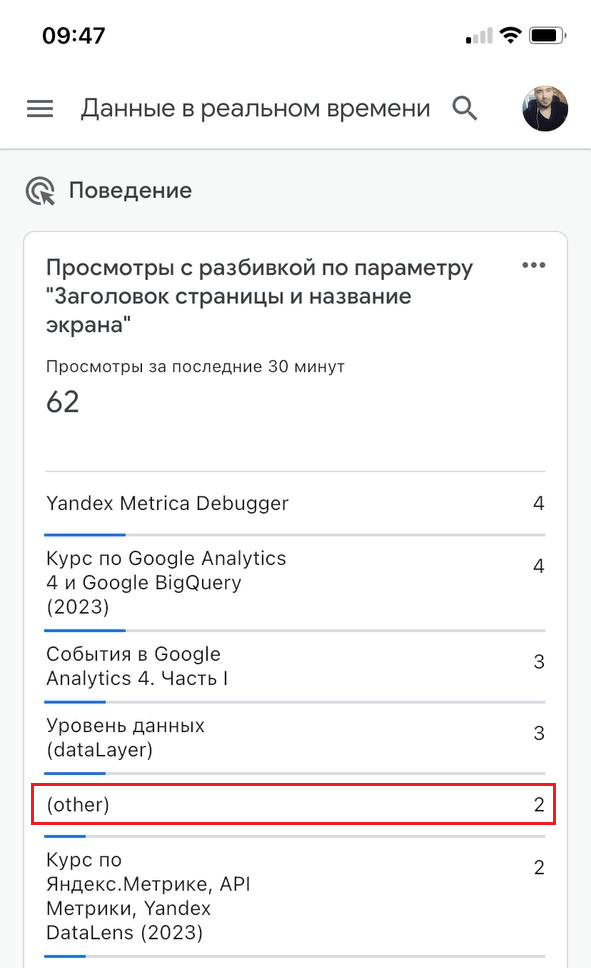
Строка (other) в мобильном приложении
Это еще одна проблема, поскольку она не позволяет точно проанализировать весь набор данных в GA4. Какие значения находятся в строке (другое)? Узнать невозможно. Однако такая строка появляется крайне редко, и только в стандартных агрегированных отчетах (включая основные и дополнительные параметры) и данных, выгруженных с помощью Data API. В Исследованиях и отчетах по воронкам она не появляется, поскольку там данные загружаются напрямую, без использования заранее обработанных таблиц.
В отчете с дополнительными параметрами, фильтрами или сравнениями это появление строки (other) более вероятно, так как для таких отчетов требуются таблицы базы данных с большим количеством параметров. В ресурсах, где много данных, легко может быть превышено ограничение на количество уникальных значений, и тогда данные будут сгруппированы и отображены в одной строке.
Если в вашем ресурсе строка (other) все же появилась, Google рекомендует выполнить следующие действия:
- использовать стандартные параметры вместо специальных (тех, которые вы самостоятельно настроили);
- собирайте параметры, у которых 500 или больше разных значений, только при необходимости;
- не используйте специальные параметры, чтобы создавать отдельные идентификаторы для каждого пользователя (Client ID или другие). Для этого в GA4 применяется функция User ID;
- посмотрите те же данные в Исследованиях;
- как правило, высокую кардинальность имеют пути к странице, особенно когда вы ведете рекламу и для одной и той же страницы создается несколько записей с параметрами запроса, в которые входят utm_метки, gclid, yclid, fbclid и т.п. О том, как исключить их из Google Analytics 4, читайте в этой статье;
- избегайте выборки данных;
- экспортируйте данные в Google BigQuery, чтобы избежать появления строки (other) и получать результаты без выборки;
- в Google Analytics 360 вы можете использовать расширенный набор данных;
- если в часто просматриваемом отчете в строке (other) постоянно группируются данные, Google Analytics 4 включает автоматическое расширение наборов данных. Вам не нужно ничего делать. Данная функция доступна в ресурсах Google Analytics 360.
Итого
- в Google Analytics используется алгоритм HyperLogLog++, который отображает в интерфейсе приблизительные значения различных показателей. Если вам нужны точные данные, то используйте Google BigQuery;
- при выполнении SQL-команд в BigQuery вы можете использовать эскизы HLL++ и его функции с указанием точности значений;
- в Google Analytics 4 есть задержка данных при отправке офлайн-событий, которая может составлять 72 часа. В течение этого времени Google будет обрабатывать эту информацию, поэтому табличные данные в интерфейсе вашего ресурса могут отличаться от экспортируемых данных в BigQuery;
- напоминаю, что GA4 не экспортирует в BigQuery данные, связанные с сигналами Google, поэтому количество событий в Google Analytics и в BigQuery может быть разными. Это связано с тем, что сигналы Google дедуплицируют полученные данные о событиях;
- параметры, количество уникальных значений которых в Google Analytics 4 превышает 500, называют параметрами с большим количеством уникальных значений. Такие параметры могут быть объединены и представляться в отчетах в строке (other). Она может появиться только в стандартных агрегированных отчетах (включая основные и дополнительные параметры) и данных Data API. В Исследованиях и отчетах по воронкам она не появляется
- сделайте экспорт данных в BigQuery, чтобы избежать появления строки (other) и получить результаты без выборки;
- используйте платную версию Google Analytics 360, если хотите дополнительный функционал, расширить лимиты и снять некоторые ограничения со своих данных.
Моделирование поведения и конверсий
Подробнее:
- Смоделированные конверсии
- Моделирование поведения для режима согласия
- Режим согласия Google
- Режим согласия Google и Cookiebot
- Новые настройки режима согласия в Google Tag Manager
- Включение и отключение функций для рекламодателей и персонализации рекламы
- CMP-платформа Cookiebot и Google Tag Manager
- Разблокировать теги Google при использовании режима согласия
Помните про GDPR, TCF v 2.0, CMP, режим согласия и персонализацию рекламы? Google Consent Mode позволяет вам сообщать статус согласия ваших пользователей на использование файлов cookie в Google. Когда посетители отказывают в согласии, GA4 заполняет пробелы в сборе данных с помощью моделирования конверсии и моделирования поведения. Но это доступно только в том случае, если вы разместили такой или аналогичный баннер, запрашивающий у пользователя разрешения на сбор его данных:
Пример баннера (плашки) для режима согласия
У Google на YouTube есть отдельное видео по моделированию. Оно на английском языке, но с помощью браузера Яндекса и встроенной функции перевода вы легко сможете понять о чем в нем идет речь:
Если пользователь отклонил запрос на отслеживание, Google Analytics 4 не будет получать данные о нем. Вместо этого алгоритмы машинного обучения будут моделировать поведение таких пользователей исходя из того, какие действия совершают другие пользователи - те, кто согласился включить файлы cookie. Моделирование позволяет оценить поведение пользователей исходя из таких показателей, как количество активных пользователей за день и коэффициент конверсии, а также другой информации о пользователях и сеансах, которую сложно собрать, если недоступны файлы cookie или идентификаторы пользователей.
Благодаря этому вы сможете получать ответы на следующие важные вопросы:
- Сколько у меня активных пользователей в день?
- Сколько новых пользователей было привлечено благодаря последней кампании?
- Какой путь прошел пользователь до совершения покупки после посещения сайта?
- Сколько пользователей из Германии и Великобритании было среди посетителей моего сайта?
- Как различалось поведение пользователей, посещавших мой сайт на мобильном устройстве и компьютере?
Для того, чтобы в вашем Google Analytics 4 стало работать моделирование, вам необходимо правильно настроить режим согласия, а также выбрать в интерфейсе GA4 смешанный типа идентификации пользователей. А поскольку модель обучается на основе наблюдаемых и исторических данных GA4, в вашем ресурсе должно быть достаточно таких данных. И для этого GA4 должен соответствовать следующим требованиям:
- на всех страницах сайта и/или на всех экранах приложений включен режим согласия;
- режим согласия для веб-страниц настроен так, чтобы теги загружались до появления диалогового окна для получения согласия. Теги Google должны загружаться в любом случае, даже если пользователь не дал согласия;
- для GA4 регистрируется не менее 1000 событий в день со значением analytics_storage='denied' в течение как минимум 7 дней;
- ваш сайт посещает не менее 1000 пользователей в день со значением analytics_storage='granted' в течение как минимум 7 дней из последних 28;
- для успешного обучения модели вам может потребоваться достигать порогового значения в течение более чем 7 дней за 28-дневный период. Однако и дополнительных данных может оказаться недостаточно.
Пока этого не будет, в настройках способов идентификации напротив Моделирование будет вам недоступно:
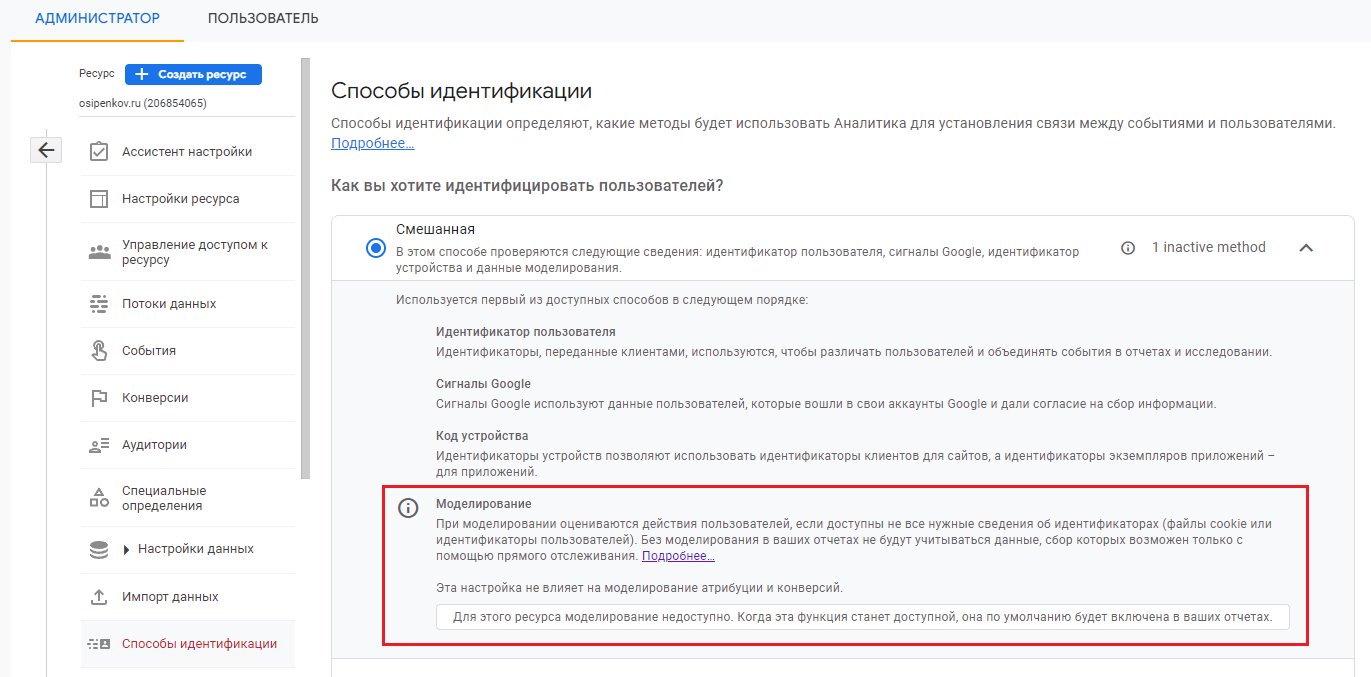
Способ идентификации - Моделирование
Моделирование поведения осуществляется с даты, когда ресурс начинает соответствовать указанным требованиям. На текущий момент в моей практике пока не встречались проекты, в которых работало моделирование. Но если ваш проект удовлетворяет вышеупомянутым требованиям и на него распространяется моделирование, то внутри Google Analytics 4 вы увидите соответствующее уведомление, а также значок качества данных Including estimated user data рядом с названием отчета:
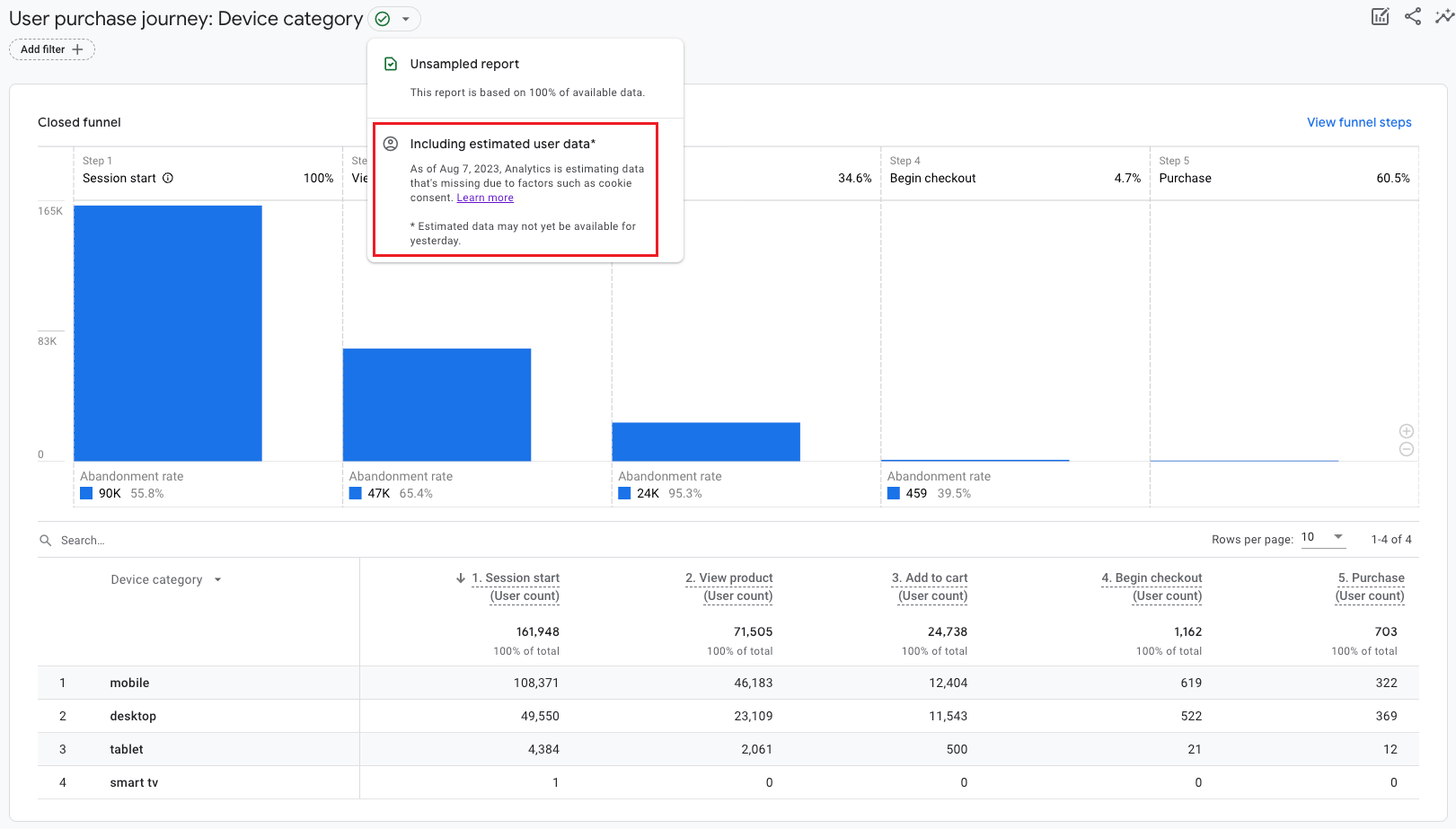
Значок качества, свидетельствующий о моделировании данных
В очень редких случаях, когда ресурс перестал отвечать требованиям для моделирования поведения, хотя раньше отвечал, расчетные данные станут недоступны. Если ресурс снова будет отвечать требованиям, расчетные данные появятся опять. Они будут доступны только с той даты, когда требования снова начали выполняться.
Смоделированные данные на текущий момент не доступны в экспорте событий BigQuery. Когда будет реализован режим согласия, набор данных BigQuery будет содержать пинги без файлов cookie (отслеживание пользователей без их согласия), собранные GA, и каждый сеанс будет иметь другой уникальный идентификатор пользователя user_pseudo_id. Из-за моделирования будут различия между стандартными отчетами и данными в BigQuery. Например, из-за поведенческого моделирования вы можете увидеть меньшее количество активных пользователей по сравнению с экспортом BigQuery, поскольку моделирование может попытаться предсказать несколько сеансов от отдельных пользователей без согласия. Чтобы уменьшить влияние этого, вы должны реализовать идентификаторы пользователей User ID (а не Client ID) в Google Analytics 4. user_id и специальные параметры экспортируются в BigQuery независимо от статуса согласия ваших пользователей.
В Исследованиях путей и воронок моделирование используется иначе, чем в отчетах. В отчетах оно применяется к показателям, таким как Пользователи, Сеансы и Новые пользователи, и не применяется к событиям, таким как page_view, first_visit или session_start. В тех случаях, когда пользователи не разрешают назначить им постоянные идентификаторы, GA4 не может определить, произошли ли различные события в результате действий одного и того же пользователя. В результате для таких пользователей регистрируется больше событий first_visit и session_start, так как данные о событии отправляются при каждой загрузке страницы.
В Исследованиях путей и воронок, напротив, моделирование применяется к событиям first_visit и session_start. В тех случаях, когда пользователи не разрешают назначить им постоянные идентификаторы, GA4 оценивает реальное количество событий first_visit и session_start. Поэтому Исследованиях путей и воронок количество событий first_visit и session_start будет ниже, чем в отчетах.
Перечисленные ниже функции не поддерживают использование смоделированных данных о поведении:
- аудитории;
- В Исследованиях Наложение сегментов, Статистика пользователей, Когортное исследование и Общая ценность пользователя;
- сегменты с последовательностью;
- отчеты об удержании;
- прогнозируемые показатели;
- экспорт данных в Google BigQuery;
Помимо моделирования поведения пользователей Google еще умеет моделировать конверсии. Моделирование делает возможной точную атрибуцию конверсий без идентификации пользователей (например, если это технически невозможно или запрещено настройками конфиденциальности, а также если один и тот же пользователь совершает действия на разных устройствах).
Давайте рассмотрим пример из видео:
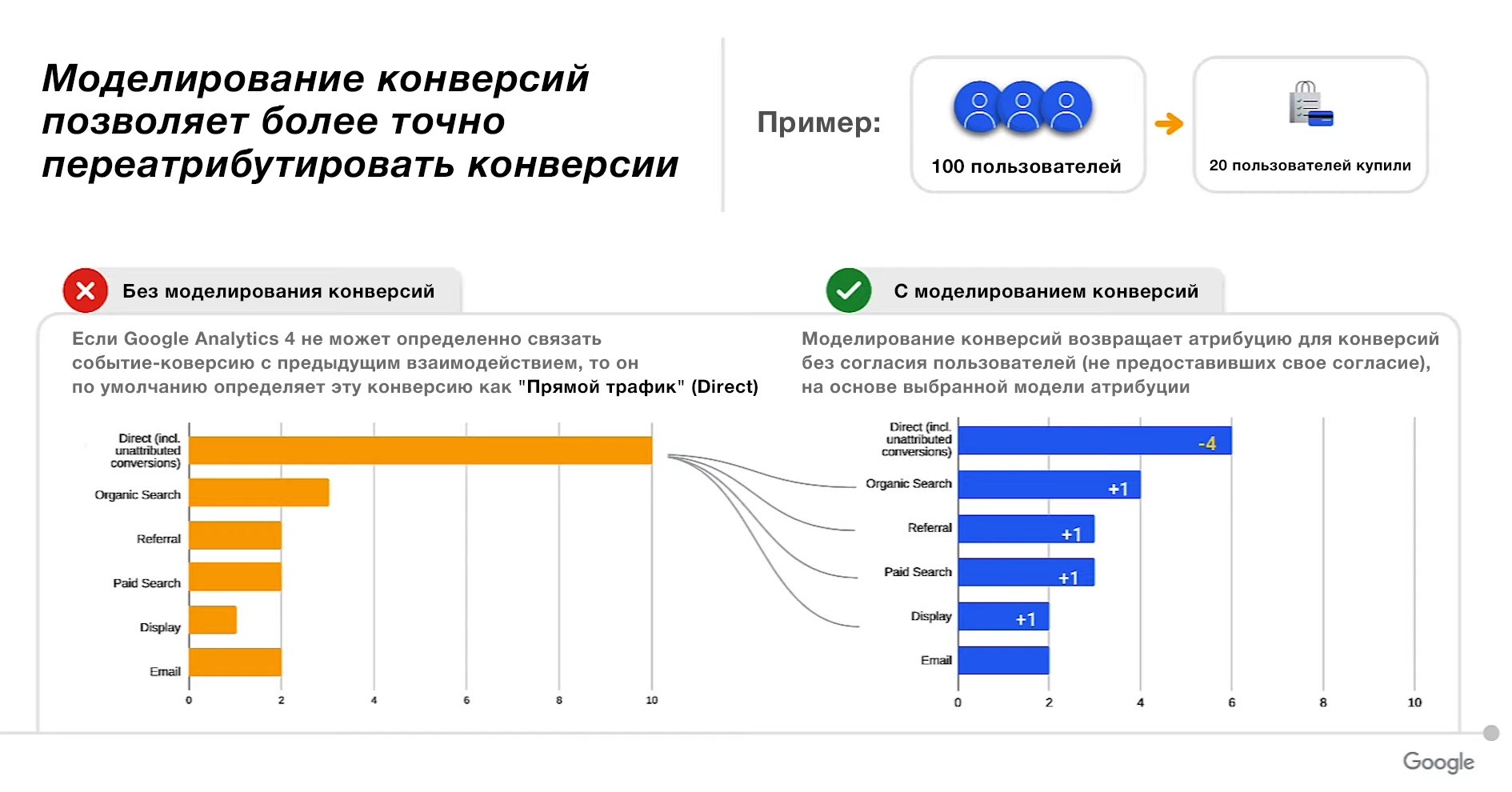
Пример с моделированием конверсий
Предположим, на ваш сайт зашло 100 пользователей и 20 из них купило. Без моделирования конверсий некоторые из 20 конверсий не могут быть напрямую связаны с предыдущими взаимодействиями, и поэтому Google Analytics 4 по умолчанию отнесет их к прямому источнику трафику (Direct) из-за уже известных вам факторов:
- файлы cookie блокируют блокировщики рекламы типа AdBlock, Ghostery и т.д.;
- файлы cookie блокирует сам браузер с помощью системы интеллектуального отслеживания (Safari, Firefox, Brave и другие);
- в настройках браузера по умолчанию заблокированы файлы cookie;
- и другие.
При моделировании конверсий Google использует машинное обучение для перераспределения конверсий по различным рекламным каналам, включая Google Рекламу, рекламу других сервисов, органический поиск и электронную почту, чтобы дать вам полную картину того, как выполняются конверсии на сайте. Модели Google выявляют закономерности между зарегистрированными конверсиями и теми, которые невозможно отследить непосредственно. Допустим, конверсии, зарегистрированные в одном браузере, похожи на конверсии без атрибуции из другого браузера. В таком случае алгоритмы смогут спрогнозировать общую атрибуцию. При этом в агрегированных данных будут учитываться как смоделированные, так и зарегистрированные конверсии. При моделировании конверсий в Google Analytics 4 общее количество конверсий не изменится. Изменятся только приписываемые конверсии для каждого канала.
Google не идентифицирует пользователей по цифровым отпечаткам (fingerprint) или другими способами. Вместо этого он собирает агрегированные данные о динамике коэффициентов конверсии, типах устройств, времени суток, географическом местоположении и т.д. На основе этих сведений GA4 прогнозирует вероятность конверсий.
Когда Google применяет моделирование конверсий?
- в некоторых браузерах нельзя отслеживать конверсии с помощью сторонних файлов cookie. В таких случаях Google моделирует данные на основе трафика сайтов;
- Google также использует моделирование, если браузеры ограничивают срок действия собственных файлов cookie;
- в некоторых странах требуется разрешение пользователей на использование файлов cookie для показа рекламы. Если рекламодатель включил режим согласия, конверсии будут моделироваться для тех, кто запретил файлы cookie;
- согласно правилам App Tracking Transparency (ATT) от Apple разработчики должны запрашивать разрешение, если они хотят использовать для рекламы определенные данные, полученные из других приложений и сайтов. Google не использует идентификаторы IDFA и другую информацию, которой касаются правила ATT. Поэтому он моделирует данные о конверсиях, полученных благодаря рекламе, на которую распространяется действие этих правил;
- данные могут моделироваться, когда пользователь взаимодействует с объявлением на одном устройстве, а конверсию совершает на другом;
- в YouTube моделирование конверсий используется как для событий на основе кликов, так и для заинтересованных просмотров, чтобы облегчить атрибуцию конверсий по таким просмотрам;
- моделирование присутствует во всех конверсиях, которые импортируются в Google Рекламу из связанных ресурсов Google Аналитики 4.
Примечание: помните, что в отчетах Google Analytics 4 данные об атрибуции конверсий по каждому из каналов могут меняться в течение семи дней после регистрации этих конверсий. Так происходит потому, что Analytics продолжает обрабатывать информацию и использует ее для обучения алгоритмов моделирования. Если вам нужны более точные данные, выберите временной диапазон, закончившийся ранее, чем неделю назад.
Смоделированные конверсии для платных и бесплатных каналов стали доступны в вашем счетчике Google Analytics 4 в конце июля 2021 года. Чтобы убедиться в этом, перейдите в раздел Настройки атрибуции и проверьте, что у вас выбран вариант Платные и бесплатные каналы для каналов, которым может назначаться ценность:
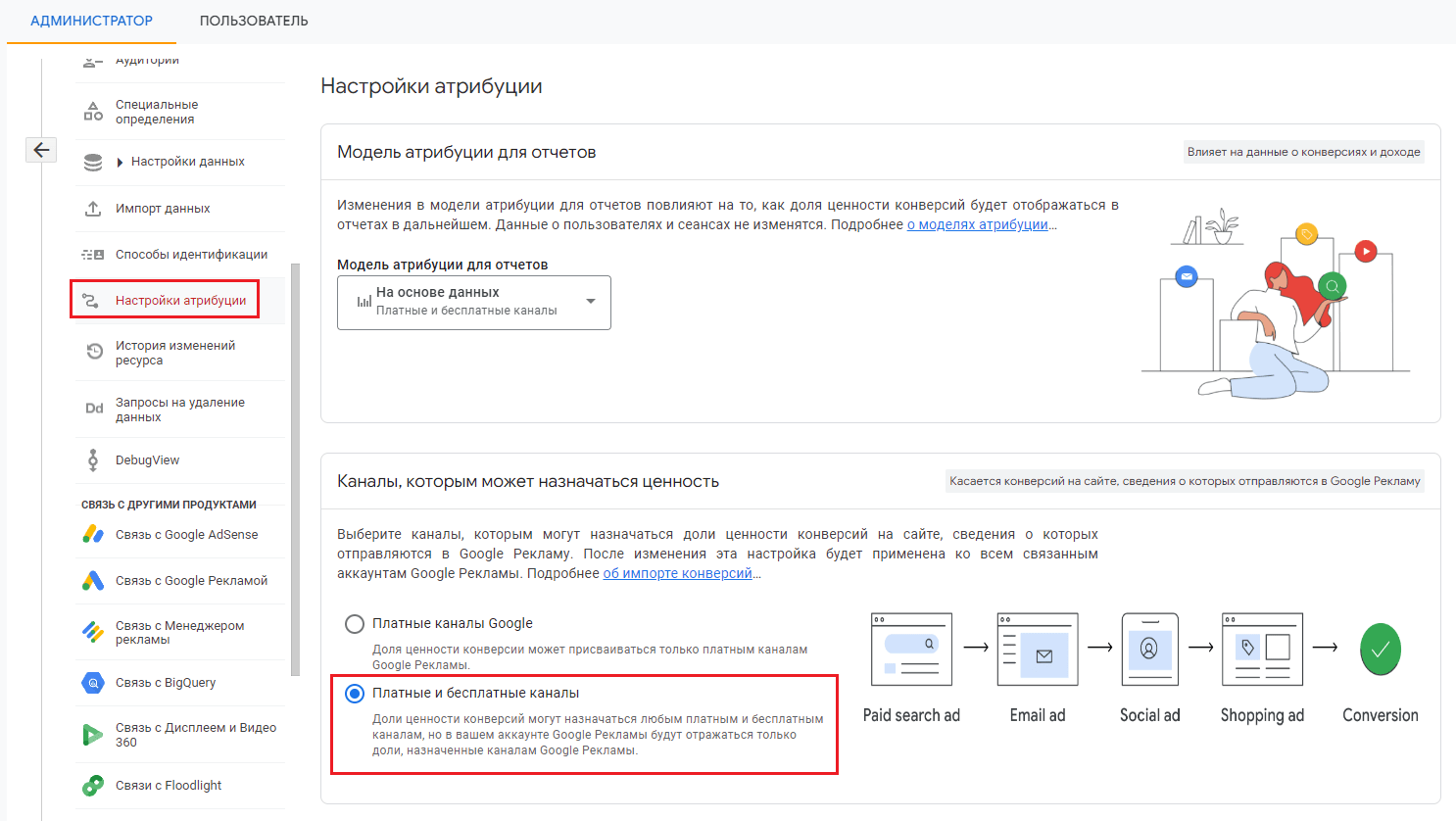
Настройки атрибуции - Платные и бесплатные каналы
Смоделированные данные будут использоваться в основных отчетах События, Конверсии, Атрибуция (раздел Реклама) и Исследованиях, в которых можно выбирать параметры на уровне события.
Итого
- данные пользователей, которые согласились на отслеживание их файлов cookie, называются наблюдаемыми данными, поскольку они поступают от пользователей, которые разрешили GA4 наблюдать за их поведением. Смоделированные данные - это те данные, которые Google смоделировал на основе алгоритмов машинного обучения для тех, кто отказался от отслеживания файлов cookie;
- моделирование поведения в GA4 станет доступно только после выполнения определенных требований, а также после настройки режима согласия;
- В Исследованиях путей и воронок моделирование работает не так, как в отчетах;
- смоделированные данные о поведении не поддерживаются в аудиториях, Исследованиях (Наложение сегментов, Статистика пользователей, Когортное исследование и Общая ценность пользователя), сегментах с последовательностью, в отчетах об удержании, прогнозируемых показателях и не доступны в экспорте BigQuery;
- Google не идентифицирует пользователей по цифровым отпечаткам (fingerprint) или другими способами для моделирования конверсий. Для этого он использует агрегированные данные о динамике коэффициентов конверсии, типах устройств, времени суток, географическом местоположении;
- смоделированные данные используются в отчетах по событиям, конверсиям, в разделе Реклама - Атрибуция, а также в Исследованиях, в которых можно выбирать параметры на уровне события;
- моделирование конверсий применяется, если - браузеры блокируют файлы cookie или устанавливают для них ограниченный срок жизни, пользователь отказался от сбора данных или когда он взаимодействует с объявлением на одном устройстве, а конверсию совершает на другом, а также когда совершаемые конверсии были выполнены с рекламы, попадающие под правила ATT от Apple;
- смоделированные конверсии для платных и бесплатных каналов стали доступны в интерфейсе Google Analytics 4 в конце июля 2021 года, и эту настройку можно изменить в интерфейсе, переключившись на назначение ценности только для платных каналов Google (Google Ads).
Расхождения в данных отчетов, Исследований и BigQuery
Подробнее:
- Расхождения в данных отчетов и Исследований
- Сравнение платформ отчетов
- Как сравнивать отчеты Аналитики с данными, экспортированными в BigQuery
После того, как вы узнали про кардинальность, HyperLogLog++, способы идентификации пользователей, сигналы Google, конфигурацию тега, выборку данных, пороговые значения, моделирование поведения и конверсий в Google Analytics 4, пришло время подытожить все это общей информацией по расхождению данных в отчетах, Исследованиях и BigQuery.
В отчетах и Исследованиях поддерживаются разные поля
В отчетах и Исследованиях используются разные представления и уровни детализации данных. Например, некоторые параметры и показатели, доступные в отчетах, не поддерживаются в Исследованиях. Если вы откроете в Исследовании отчет с неподдерживаемыми полями, они будут исключены. Если в отчете присутствует визуализация на основе неподдерживаемых полей (например, график с неподдерживаемым показателем), она не появится в Исследовании.
Например, параметр Путь к странице + строка запроса и класс экрана (Page path + query string and screen class) можно выбрать при создании собственного отчета в библиотеке:
Параметр "Путь к странице + строка запроса и класс экрана" в подробном отчете
Но такого параметра нет в Исследованиях - есть только Путь к странице и класс экрана (Page path and screen class). А это другой параметр:
Параметр "Путь к странице и класс экрана" в Исследовании
Хоть они и похожи по названию, но являются разными метриками в Google Analytics 4. Для того, чтобы точно знать, какие параметры и показатели поддерживаются в отчетах и Исследованиях, используйте инструмент data.ga4spy.com. В нем вы можете выбрать интересующий вас параметр и узнать все о нем. Например, давайте выберем этот же параметр - Путь к странице + строка запроса и класс экрана (Page path + query string and screen class). Нажав на него, вам будут показаны детальные сведения:
Данные по параметру "Путь к странице + строка запроса и класс экрана"
Как видите, данный параметр доступен в Looker Studio, по API, в аудиториях, в подробных отчетах, но его нельзя выбрать в Исследованиях и он недоступен в отчете В реальном времени. А другой параметр, который Путь к странице и класс экрана (Page path and screen class), напротив, может использоваться как в Исследованиях, так и при создании собственных отчетов:
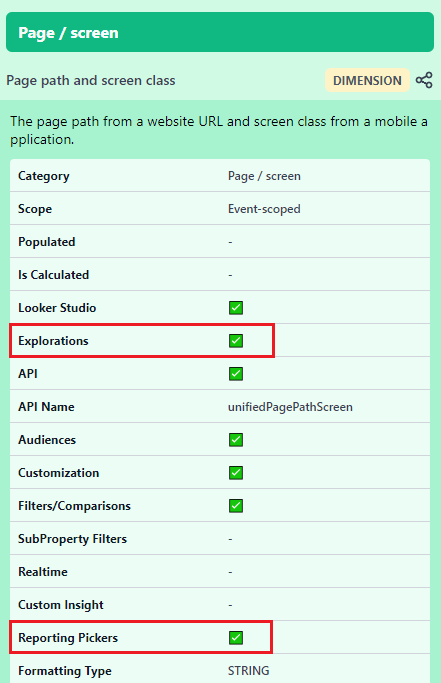
Данные по параметру "Путь к странице и класс экрана"
Утилита data.ga4spy.com очень полезна для проверки информации по различным параметрам и показателям Google Analytics 4.
В отчетах и Исследованиях по-разному работает фильтрация
В Исследованиях при фильтрации можно выбрать тип соответствия (например, содержит, точное соответствие, начинается с, соответствует регулярному выражению и т.д.) и выражение с учетом регистра:
Фильтрация в Исследовании
В отчетах над таблицей в качестве фильтра можно использовать поиск, при котором будут показаны результаты с типом соответствия содержит и без учета регистра:
Фильтр над таблицей в отчетах
С августа 2023 года в отчетах GA4 стали доступны дополнительные типы фильтрации, включая регулярные выражения. Для этого вам нужно использовать кнопку Добавить фильтр над отчетом:
Фильтр с разными типами соответствий
Различия между сегментами и сравнениями
При сравнении в отчетах могут использоваться поля, которые не поддерживаются в Исследованиях. Сравнения, представленные в отчете, который вы открываете в Исследованиях, преобразуются в сегменты. При этом все неподдерживаемые показатели и параметры в сравнении не учитываются в полученном сегменте в Исследованиях. При этом могут измениться данные, включенные в сегмент или исключенные из него.
Здесь вам на помощью то же придет инструмент data.ga4spy.com, в котором для каждого параметра и показателя есть информация по фильтрам и сравнениям:
Возможность использования в сравнениях
Различия в датах
Это вы уже знаете. Диапазон дат в Исследованиях ограничен настройками хранения данных вашего ресурса (2 или 14 месяцев), в то время как в агрегированных отчетах GA4 вы можете посмотреть статистику за куда больший период времени. Если вы создадите отчет, диапазон дат которого не соответствует настройкам хранения данных на уровне пользователя или события, и откроете его в Исследованиях, данные за более ранние периоды в него включены не будут.
Большие данные (Big Data)
Если ваш счетчик собирает много данных, в GA4 будут использоваться разные методы для построения отчетов и Исследований. Из-за этого между ними могут быть расхождения. Не забывайте также про пороговые значения и выборки.
Удаление данных из-за малого объема
Данные могут быть удалены (=скрыты) из отчета или Исследования, если у вас мало пользователей за указанный период. Google применяет пороговые значения, чтобы при просмотре отчета или Исследования нельзя было идентифицировать отдельных пользователей на основе возраста, пола, категорий интересов и других сигналов данных. Помните про пример с заходами на новый сайт, когда кроме вас на нем никого нет, и вы занимаетесь настройкой различных отслеживаний. В отчете В реальном времени и инструменте DebugView все отображается как нужно, а спустя 24 часа ваши данные так и не появились в отчетах. Это как раз может быть связано с пороговыми значениями - система идентифицировала конкретно вас. И пока на вашем сайте мало данных, GA4 скрыл информацию о конкретном пользователе и всех его действиях.
Отчеты - агрегация, Исследования - нет
В Google Analytics 4 ключевую роль играют параметры и показатели, потому что любые отчеты, которые вы используете при решении задач, состоят из целого набора различных метрик. В интерфейсе GA4 в стандартных отчетах вы видите, так называемые, агрегированные (суммарные или обобщенные) данные:
Стандартные отчеты Google Analytics 4 имеют агрегированную (обобщенную) статистику
Характерная строка Итого и среднее над таблицей свидетельствует об этом. Это означает, что со статистикой в отчете уже были совершены определенные действия. Как правило, это простые арифметические операции - сложение, вычитание, умножение и деление. То есть над ними поработали за вас. А вы в отчетах видите уже готовые, обобщенные наборы данных, посчитанные заранее, которые создаются на основе сводных таблиц с данными за день. При этом существуют определенные ограничения системы, которые мы с вами разобрали ранее. Если количество уникальных значений в данных, которые собирает ресурс, превышает ограничения системы для таблицы, все превышающие ограничение данные агрегируются в строке (other). Это вы тоже уже знаете.
Большое количество уникальных значений влияет на отчеты по-разному в зависимости от типа отчета. Все стандартные отчеты составляются на основе небольших таблиц, которые редко превышают ограничение системы – 50 000 строк. Специальные отчеты и стандартные отчеты с дополнительными параметрами, сравнениями и фильтрами создаются на основе более крупных сводных таблиц с более высокими лимитами на количество строк. В этом случае максимальное количество строк составляет 2 000 000. В этих отчетах данные с большей вероятностью будут сгруппированы в строке (other), так как таблицы содержат много параметров с большим количеством элементов.
Если отчет составляется на основе таблицы, в строке (other) которой есть данные, эта строка может появиться в результатах. Если в результатах отчета пропущена строка (other), но в нее включена часть данных, то значения примененных параметров могут округляться до более низких.
В Исследованиях используются другие данные. Там запрашиваются необработанные данные на уровне события и пользователя. Если количество событий, которые нужно обработать в запросе, превышает лимит квоты, GA4 использует выборку из доступных данных. Лимит квоты составляет 10 000 000 событий для пользователей бесплатной версии Google Analytics 4 и 100 000 000 событий для пользователей платной версии.
Исследования строятся на необработанных данных
В зависимости от объема и типа собираемых ресурсом данных эти приближенные значения могут по-разному влиять на результаты и приводить к несоответствиям между результатами отчета и Исследования. Как правило, если использовались приближенные вычисления, то более точными будут результаты Исследования. А если нужны "самые точные данные", тогда вам нужно выходить за пределы интерфейса Google Analytics 4 и использовать Google BigQuery.
Сравнение данных в Google Analytics 4 и BigQuery
Как вы уже понимаете, некоторые расхождения в данных GA4 и BigQuery - обычное явление. Это связано с тем, что для каждого сервиса доступны различные наборы данных. Чтобы выяснить, не свидетельствуют ли эти расхождения о возможной проблеме, прежде чем сравнивать данные, проверьте указанные ниже настройки.
Во-первых, в настройках своего ресурcа в способах идентификации выберите способ идентификации На основе устройства:
Идентификация пользователей на основе устройства
Выбранный способ идентификации не влияет на сбор и обработку данных. Вы можете изменить его в любой момент, и это не затронет сами данные.
После этого убедитесь, что ваши часовые пояса в Google Analytics 4 и BigQuery совпадают. Чтобы посмотреть его в интерфейсе, перейдите на уровне ресурса в раздел Настройки ресурса:
Часовой пояс в интерфейс Google Analytics 4
В BigQuery для этого вам потребуется перейти в проект, затем выбрать набор данных, открыть любую таблицу events_ и на вкладке Details в разделе Table info посмотреть в строке Created на конец временной метке:
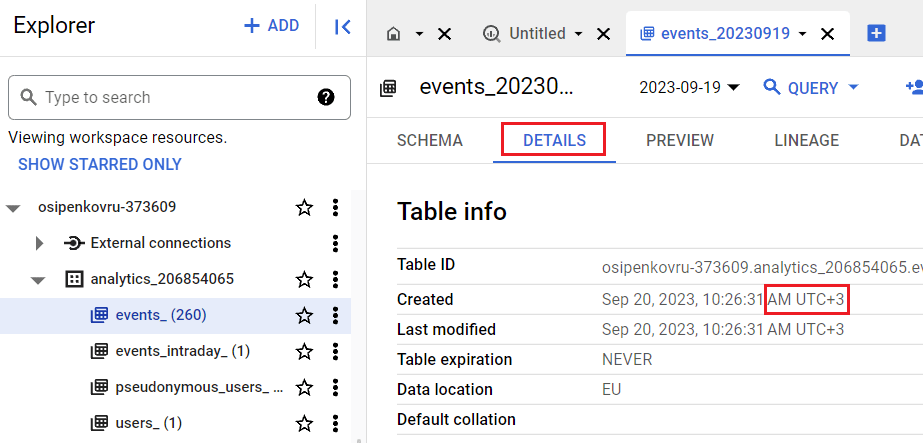
Часовой пояс в BigQuery
Сравнить данные в Google Analytics 4 и BigQuery можно и по количеству событий. Для этого в интерфейсе перейдите в отчет Взаимодействие - События и выберите нужный диапазон дат. Общее число событий будет указано над первой строкой в столбце Количество событий:
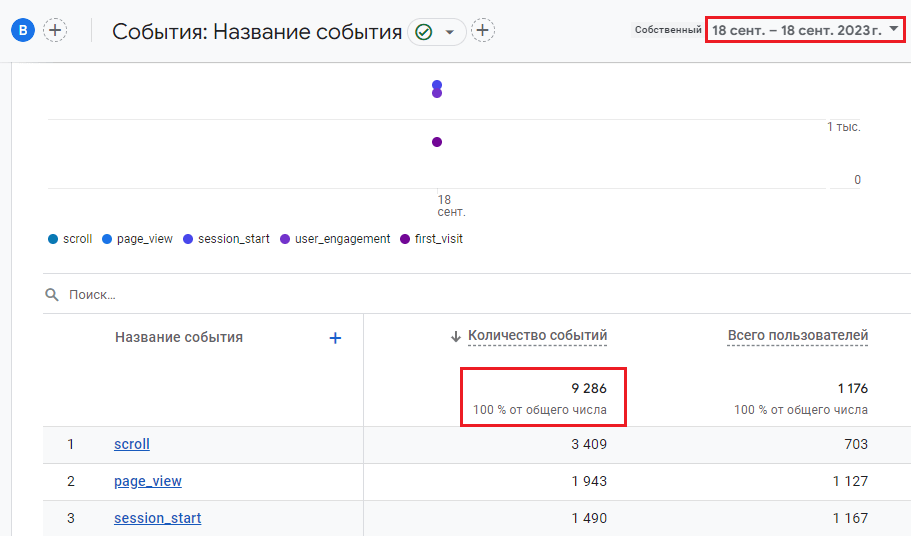
Количество событий в отчете "Взаимодействие - События"
В моем примере для 18 сентября 2023 года количество событий составляет 9286. В BigQuery откройте свой проект, выберите нужную таблицу events_ с вашей датой (если вы сравниваете статистику с одним днем как я) и на вкладке Details в разделе Storage info найдите строку Number of rows:
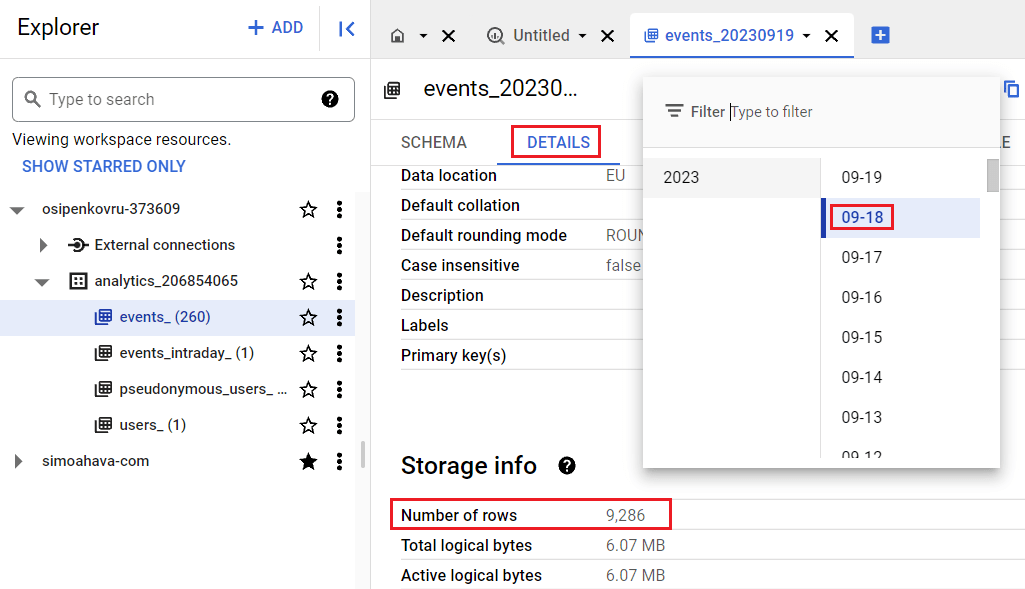
Количество строк в таблице событий BigQuery за выбранный день
Если число строк в BigQuery соответствует общему количеству событий в GA4, значит экспортированные данные точны. Если вы по-прежнему наблюдаете расхождение, когда выполняете запрос, проверьте сам SQL-запрос и убедитесь, что для сравнения используются нужные столбцы из схемы данных.
Примечание: расхождение между общим количеством событий в Google Analytics 4 и BigQuery не должно превышать 2–5 %.
Ограничения
Для интерфейсных отчетов, Исследований, выгрузки данных по API и BigQuery существуют некоторые ограничения:
- Для отчетов - можно создать до 150 специальных отчетов на один ресурс;
- Для Исследований - можно создать до 200 отдельных Исследований на одного пользователя и один ресурс, и до 500 совместных Исследований на один ресурс. Можно импортировать до 10 сегментов на одно Исследование;
- Data API - применяются квоты API
Квоты API Google Analytics 4
- Для BigQuery - для стандартных ресурсов используется ограничение на экспорт в размере 1 000 000 событий в день. Для ресурсов Google Analytics 360 экспорт практически не ограничен.
Экспорт данных в BigQuery
Узнав про принцип работы Google Analytics, его сбор, обработку и представление данных в отчетах и Исследованиях, мы пришли к вполне очевидному и закономерному выводу - Google хочет "подсадить всех нас" на работу с Google Cloud и облачным хранилищем Google BigQuery. Именно в нем вы будете работать с данными без какой-либо выборки, пороговых значений и иметь возможность максимально гибко строить нужные вам табличные срезы и визуализации для своих итоговых дашбордов.
Но и здесь не все так гладко. Несмотря на всю мощь и все большую востребованность необработанных данных для вашего бизнеса, стриминг данных GA4 в Google BigQuery не является пока "идеальным". В нем тоже присутствуют некоторые изъяны и ошибки, которые требуют доработок. В частности, вы можете посмотреть небольшое видео от Ильи Красинского (основатель & CEO rick.ai и heroes.camp), где он кратко рассказывает о найденных их командой багах BigQuery.
К этому относится:
- пустые строки;
- (not set) каналы с продажами;
- источник платной рекламы Google Ads в сырых данных записан и перемешивается с органическим поиском;
- обрезание параметров utm_меток и gclid;
- и другие.
Еще на просторах интернета я нашел интересную Google табличку от команды Tag Manager Italia, в которую различные специалисты записывают найденные в Google Analytics 4 ошибки. Если вы тоже обнаружили какую-либо странность в работе Google Analytics 4, вы можете написать Маттео Замбону (Matteo Zambon) на почту и он добавит вашу ошибку в документ.
Сравнение платформ
Google в своей официальной справке сделал очень наглядную таблицу сравнения различных платформ. Обязательно изучите эту таблицу, чтобы комплексно посмотреть на все отличающиеся данные в отчетах, Исследованиях, Data API и BigQuery.
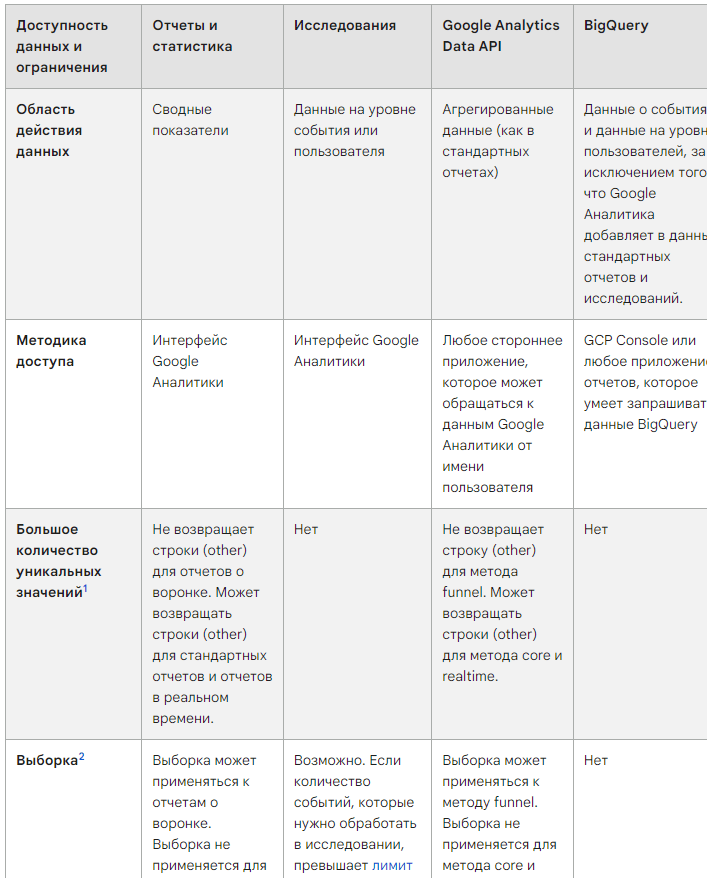
Часть таблицы по сравнению платформ




