Регулярные выражения в Google Analytics
О, регулярные выражения! Как много мы о тебе наслышаны, но до сегодняшнего дня до конца толком не понимали где и как тебя применять. Настало время познакомиться с тобой - одной из самых полезных и в тоже время недооцененных функций в Google Analytics.
Начнем с предыстории. Регулярные выражения – не разработка команды Google и не отдельный язык программирования. Их истоки лежат далеко за пределами какой-то одной области. Изначально регулярные выражения стали применять в теории автоматов и теории формальных языков. А для описания этих моделей научные деятели создали собственную систему обозначений, впоследствии названную регулярными множествами (выражениями).
Широкую известность регулярные выражения получили благодаря Кену Томпсону (Kenneth Thompson) и Деннису Ритчи (Dennis Ritchie), пионерам компьютерной науки, создателям языка программирования C и операционной системы UNIX. Кен встроил их в стандартный текстовой редактор ed, тем самым внес значительный вклад в популярность регулярных выражений, ранее считавшихся инструментом для математиков и логиков.

Кен Томпсон (Kenneth Thompson) и Деннис Ритчи (Dennis Ritchie)
В 1997 году программист Филип Хейзел (Philip Hazel) создал библиотеку PCRE (Perl Compatible Regular Expressions), реализующую работу регулярных выражений на языке программирования Perl. Синтаксис регулярных выражений PCRE оказался более мощным и гибким, чем стандартных регулярных выражений POSIX. Поэтому сейчас библиотека PCRE используется во многих современных языках программирования. Самые распространенные среди них: Perl, Java, PHP, JavaScript, языки платформы .NET Framework, Python, C++, Delphi и другие.
В Google Analytics используется частичная реализация библиотеки PCRE, поскольку версия без ограничений в умелых руках может использоваться в целях нахождения уязвимостей и последующего взлома веб-сайта. Она называется RE2 и на данный момент является более предсказуемой по времени выполнения операций и требует меньше ресурсов памяти, нежели PCRE.
Так что же такое регулярные выражения?
Регулярные выражения (regular expressions, RegExp) – инструмент для поиска текстовых строк и их проверки на соответствие какому-либо шаблону, символу или слову. Результатом применения регулярного выражения является подмножество данных, отобранное согласно логике, заложенной в выражении.
Простыми словами: у нас есть некоторый набор текстовых данных (предположим, в виде таблицы) и нам нужно из всего этого множества найти группу данных, соответствующих некоторым правилам. С помощью специальных конструкций (литерал и метасимволов) мы можем создавать сколь угодно разные условия для фильтрации данных.
Примеры из разных областей:
- чтобы удалить все файлы в каталоге компьютера, которые начинаются на букву z, в командной строке операционной системы можно написать rm z*
- для нахождения всех файлов на компьютере с расширением .pdf необходимо в строке поиска проводника ввести *.pdf
- определить, является ли строка числом, длинной до 66 цифр, на языке программирования php: if (preg_match("/^[0-9]{1,66}$/",$string)) echo "ДА";
Примеров использования регулярных выражений на практике огромное количество, а условий составления сложных конструкций для фильтрации данных бесконечно много.
Нужно вытащить данные, содержащие определенные слова, буквы или цифры? Легко! Хотите отфильтровать по значениям, начинающимся или заканчивающимся на Aa или zZ? Пожалуйста! Или просто хотите выбрать фразы, содержащие определенное количество слов или слогов? Нет проблем! Регулярные выражения - это очень мощный и гибкий инструмент, который значительно упрощает жизнь в самых разнообразных задачах.
Они присутствуют и в Excel, и в текстовых редакторах (Notepad++, EditPlus, PSPad и другие), и в Яндекс.Метрике, и даже в программе KeyCollector, знакомой многим специалистам по интернет-продвижению и применяемую для создания семантического ядра сайта.
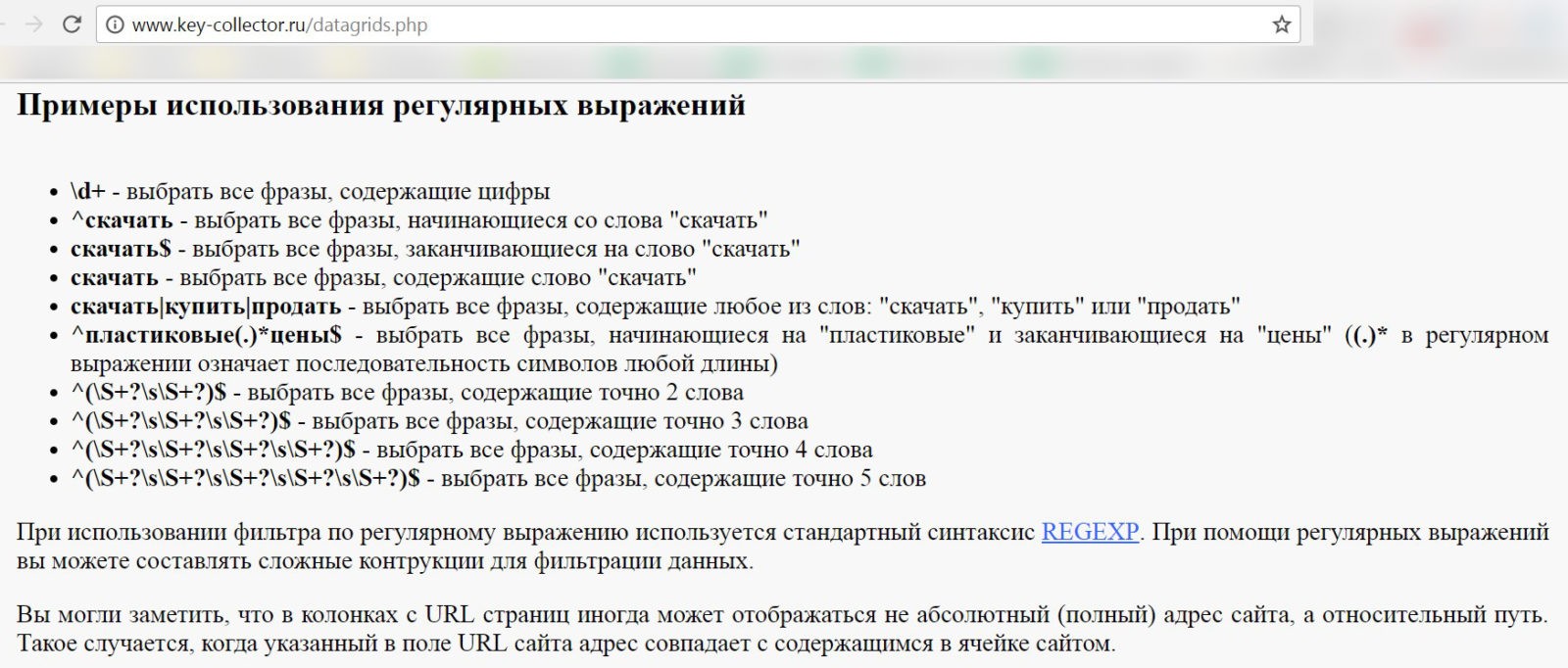
Регулярные выражения в KeyCollector
В Google Analytics регулярные выражения используются:
- при настройке целей;
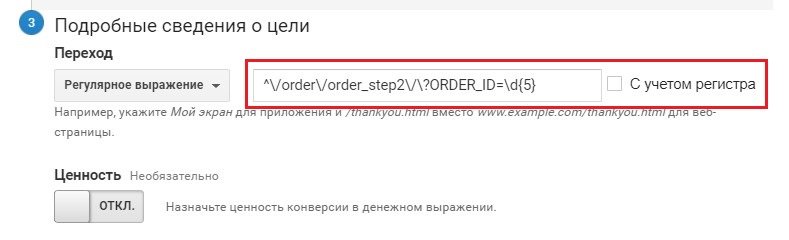
Регулярное выражение при настройке целей
- при использовании расширенного фильтра в отчетах (поиск соответствующего регулярного выражения);
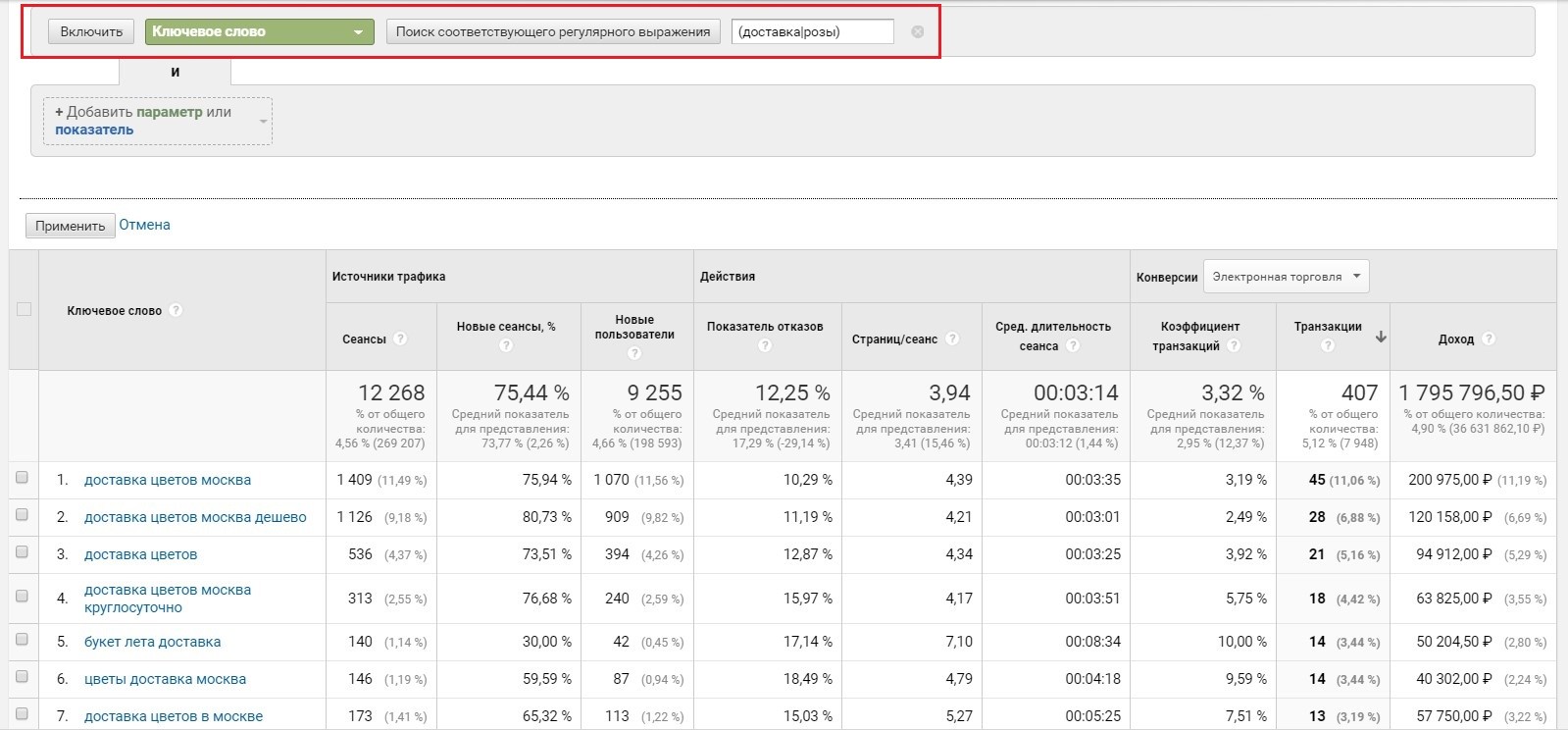
Расширенный фильтр в Google Analytics
- при создании пользовательских сегментов;

Регулярные выражения в пользовательских сегментах
- при настройке фильтров представлений;

Регулярные выражения в фильтре представления
- при использовании API Analytics;
Работая с Google Docs таблицами и делая выгрузки автоматических отчетов в Spreadsheets с помощью Google Analytics Spreadsheet Add-on, регулярные выражения можно использовать в фильтрах.
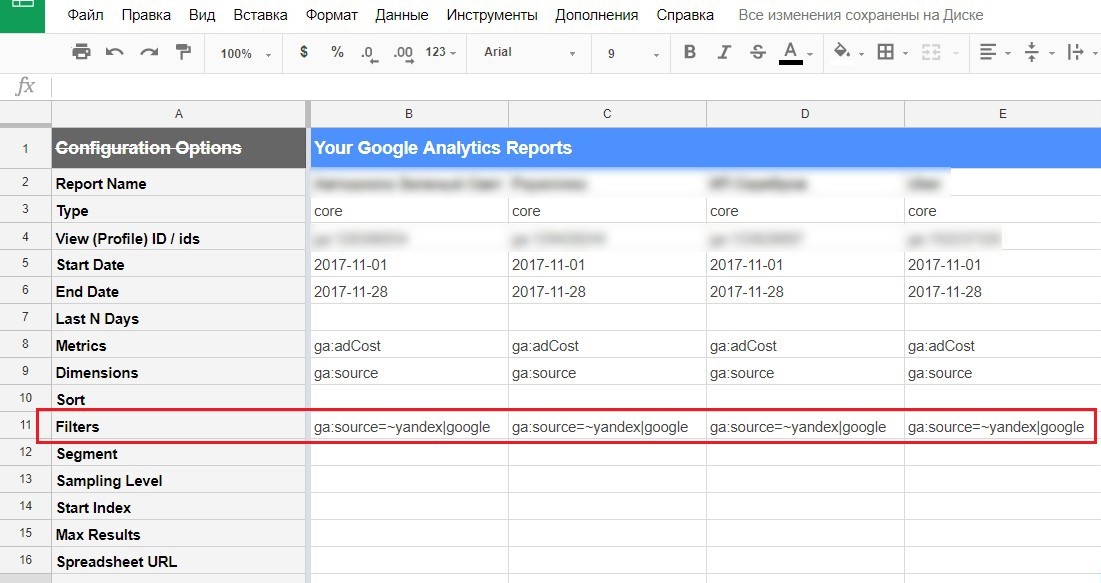
Регулярные выражения в фильтрах Google Docs
- в работе с Google Tag Manager.
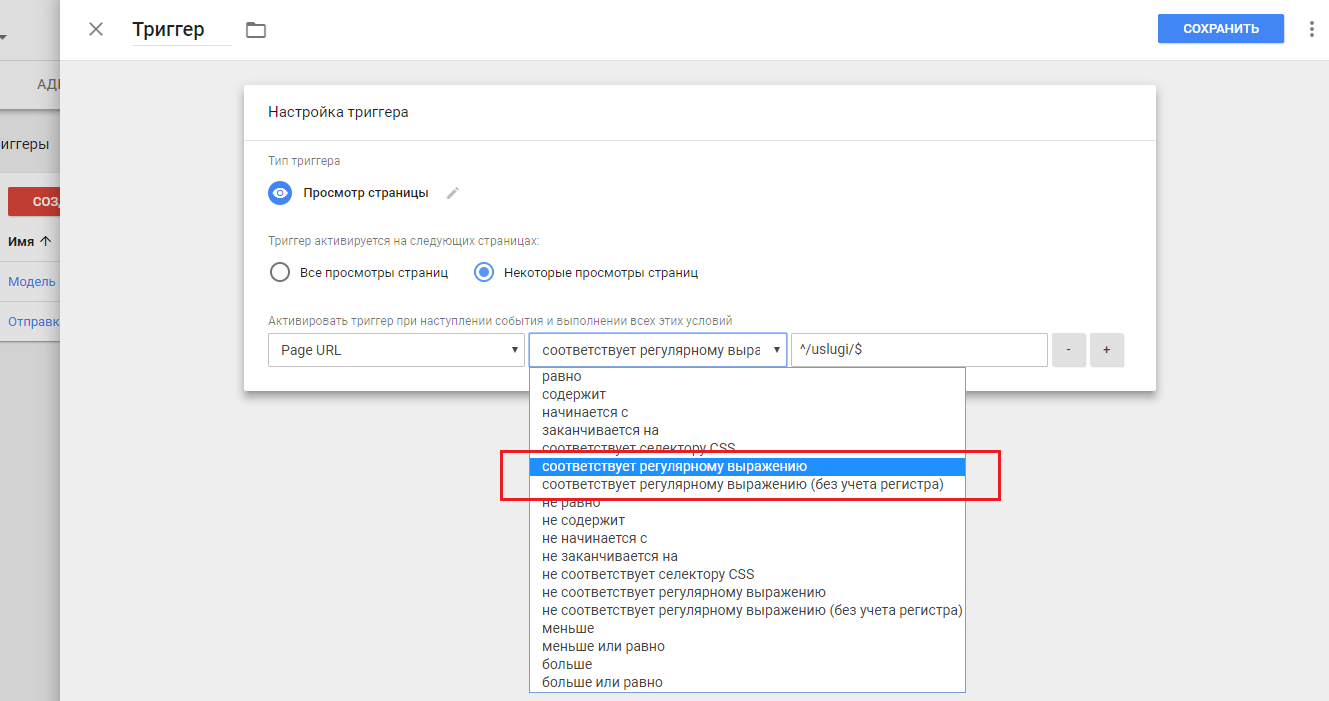
Регулярные выражения в Google Tag Manager
Синтаксис регулярных выражений
Символы бывают двух видов: литералы (обычные) и метасимволы (специальные). Большинство символов в регулярном выражении представляют сами себя за исключением специальных символов:
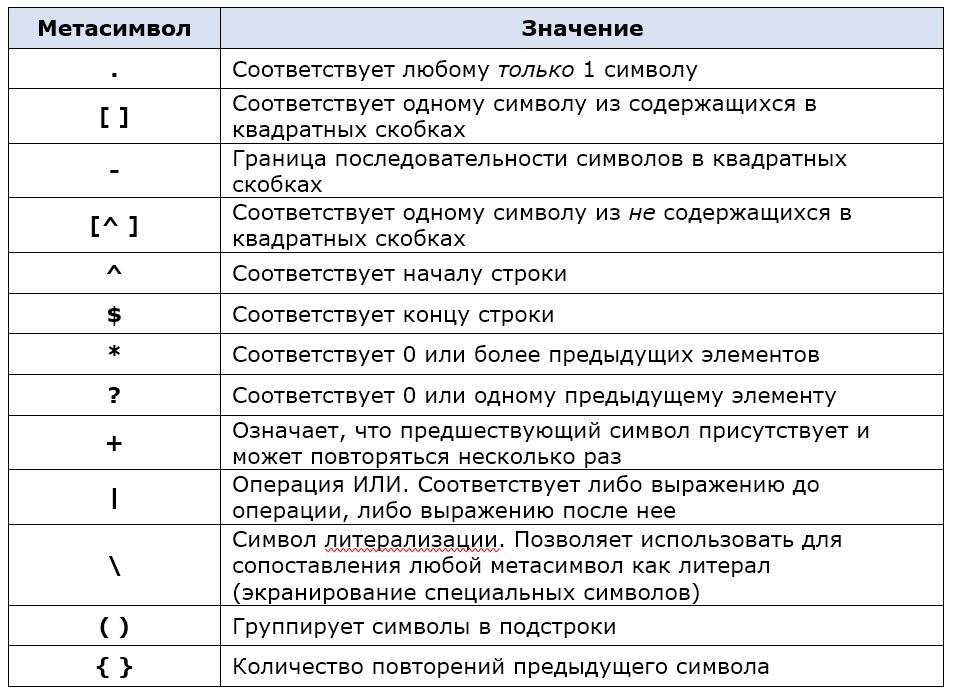
Таблица метасимволов регулярных выражений
Можно создавать регулярные выражения используя только литералы. Однако сочетание литералов с метасимволами дает более широкие возможности.
Метасимвол * (звездочка)
Звездочка * означает, что предыдущий символ может присутствовать, отсутствовать или повторяться несколько раз подряд.
Например, регулярному выражению 10* соответствуют 1, 10, 100, 1000 и т.д. Предшествующий символ 0 присутствует (10), отсутствует (1) или может повторяться несколько раз (100, 1000 и т.д.)
Метасимвол ? (вопросительный знак)
Вопросительный знак ? означает, что предшествующий символ может присутствовать или отсутствовать в строке.
Например, регулярному выражению 10? соответствуют 1, 10. Предшествующий символ 0 присутствует (10) или отсутствует (1). 100 или 1000 уже не подходит.
Метасимвол + (плюс)
Плюс + означает, что предшествующий символ присутствует и может повторяться несколько раз.
Например, регулярному выражению 10+ соответствует 10, 100, 1000 и т.д. Предшествующий символ 0 присутствует (10) и может повторяться несколько раз (100, 1000, 10000 и т.д.)
Метасимвол . (точка)
Точка . соответствует любому только 1 символу.
Например, регулярному выражению 1. соответствует 11, 1А, 1Z, 1z и т.д., регулярному выражению 1.1 соответствует 111, 141, 1А1, 1b1, и т.д., а регулярному выражению 11. соответствуют пример 118, 11f, 11U, 11& и т.д.
Метасимвол \ (обратный слэш)
Чтобы в регулярном выражении точка соответствовала только точке (то есть разделителю между компонентами IP-адреса), а не любому символу, необходимо поставить перед точкой обратную косую черту, обратный слэш \
Она означает, что следующий за ней специальный символ должен интерпретироваться как обычный. Эту процедуру еще называют экранированием, то есть преобразованием метасимвола регулярного выражения в обычный символ.
Таким образом, любой IP-адрес с разделителями «.» между цифрами будет записан как 192\.168\.1\.1 , а иначе при традиционном написании адреса вместо точки может быть любой другой символ и получится 192A168B1C1 и т.д.
Если мы хотим найти значения со слэшем, то ставим обратный слэш и обычный \/
Комбинация * и . (звездочка и точка)
Комбинация метасимволов * и . в регулярном выражении соответствует всем строкам, где на месте этого сочетания знаков может находится любая последовательность символов. Как мы уже знаем, точка – любой символ, а звездочка может присутствовать, отсутствовать или повторяться несколько раз подряд.
С помощью данной комбинации можно создать регулярное выражение, которому будут соответствовать все URL-адреса с определенным началом, окончанием и серединой. Например, регулярному выражению /catalog/.*html соответствуют следующие строки:
- /catalog/zveti/rozi.html
- /catalog/zveti/rozi/belie.html
- /catalog/zveti/rozi/belie/vkorzine.html
Метасимвол ^ (крышка, каре)
Крышка ^ означает, что соседние символы находятся в начале строки.
Например, регулярному выражению ^10 соответствуют все значения, которые начинаются c 10. Это могут быть 10, 10abc, 1000 и т.д. Но не будут удовлетворять строки с 20, 70, az и т.д.
Метасимвол $ (доллар)
Доллар $ означает, что соседние символы находятся в конце строки.
Например, регулярному выражению 10$ соответствуют abc10, google10, adwords10. Но не будут удовлетворять строки с 10abc, 10google, 10adwords.
Метасимвол [ ] (квадратные скобки)
Квадратные скобки [ ] соответствуют одному символу из содержащихся в квадратных скобках.
Например, регулярному выражению adwords[123] соответствуют adwords1, adwords, adwords3. Однако оно не соответствует ни одному из следующих вариантов: adwords12, adwords13, adwords123.
Или регулярному выражению [12345] соответствуют строки 1, 2, 3, 4, 5.
Метасимвол [^ ] (крышка в квадратных скобках)
Крышка в квадратных скобках [^ ] определяет список символов, которые не должны присутствовать в тексте.
Например, регулярному выражению [^0-8] будет соответствовать только 9. А выражению [^a-zA-Zа-яА-Я0-9] будут соответствовать все небуквенные и нецифровые символы %, &, (, } и т.д.
Метасимвол – (дефис)
Дефис – используется вместе с квадратными скобками, чтобы задать диапазон символов, с которыми нужно сравнивать значения.
Например, регулярному выражению [0-9] соответствует набор значений 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Но если мы захотим задать интервал [11-15], то у нас ничего не получится, поскольку Google Analytics интерпретирует число 11 как цифру 1 и 1, диапазон от 1 до 1 и число 5. И поэтому все это будет соответствовать только значениям 1 и 5.
И чтобы этого избежать, нам надо вынести одну единицу за пределы скобок, чтобы получилось 1[1-5]. Два промежутка задаются в квадратных скобках подряд без каких-либо знаков между. Например, так: [1-36-9] или [A-Za-z].
Очень часто в практике при создании фильтров представлений встречается задача по исключению трафика с определенного диапазона IP-адресов.
Например, если нам нужно исключить трафик c диапазона от 255.255.255.10 до 255.255.255.29, то регулярное выражение будет иметь следующий вид: 255\.255\.255\.(1[0-9]|2[0-9])
Метасимвол | (прямой слэш)
Вертикальная черта или прямой слэш | как раз означает соответствие ИЛИ для групп символов в круглых скобках.
Например, регулярному выражению (1|10|100) соответствует 1 или 10 или 100.
Метасимвол ( ) (круглые скобки)
Круглые скобки ( ) используются для группировки символов.
Например, регулярному выражению (10)+ соответствуют значения 10, 1010, 101010, поскольку метасимвол + означает, что предшествующий символ (а он у нас сгруппирован в цифру 10) может повторяться несколько раз.
Метасимвол { } (фигурные скобки)
Фигурные скобки { } позволяют указать число повторений предыдущего символа n-ое количество раз.
Например, регулярному выражению 10{3} соответствует 1000, промежутку 10{3,5} соответствует 1000, 10000, 100000. И чтобы не указывать ограничение по числу повторений, а лишь его минимальное количество, можно воспользоваться конструкцией 10{3,} и тогда данному регулярному выражению будут соответствовать строки 1000, 10000, 100000, 1000000 и т.д.
Конструкция \d
Конструкция \d соответствует любому цифровому символу и эквивалентно [0-9].
Например, регулярному выражению ^\d{2}.* будут соответствовать все значения, которые начинаются с двух цифр: 12ab, 34 bc, 09 АЯ и т.д.
Конструкция \D
Конструкция \D соответствует любому символу, кроме цифры и эквивалентно [^0-9].
Например, регулярному выражению ^\D+$ будут соответствовать все строки, содержащие нецифровые последовательности из одного или более символов (поскольку есть +): A, B, cc, ddd, eee_F и т.д.
Конструкция \w
Конструкция \w соответствует любой букве, цифре (любому алфавитно-цифровому знаку) или знаку подчеркивания _
Например, регулярному выражению ^\w+$ будут соответствовать любые последовательности из букв, цифр латинского алфавита и знака подчеркивания одного или более символов (поскольку есть +): XYZ, abc, a_c, _rt, m_095 и т.д.
Конструкция \W
Конструкция \W соответствует любому символу, кроме буквенного (латинского алфавита), цифрового или знака подчеркивания _
Например, регулярному выражению ^\W{3}$ будут соответствовать значения, состоящие из трех символов, не содержащих буквы латинского алфавита, цифры и символы подчеркивания: АБВ, абв, я-а, -%? и т.д.
Конструкция \s
Конструкция \s соответствует любому пробельному символу.
Например, регулярному выражению \w\s в исходной строке google adwords будет соответствовать значение ‘e ‘
Конструкция \S
Конструкция \S соответствует любому знаку, не являющему пробелом.
Например, регулярному выражению ^\S+$ соответствуют значения, состоящие только из одного слова в строке.
^ означает начало, \S любой символ, не являющийся пробелом, + соответствует предыдущему элементу один или более раз, а $ будут соответствовать только те значения, которые заканчиваются последовательностью символов, указанной перед ним.
Регулярные выражения не обязательно должны содержать метасимволы. Можно создать сегмент для данных из какой-либо страны с условием фильтрации «соответствует регулярному выражению» и указать в нем саму страну, например, Россия.
Разумеется, синтаксис регулярных выражений не ограничивается приведенными выше метасимволами. Их гораздо больше, и они имеют собственную градацию. Но для работы с Google Analytics этого вполне достаточно.
Более подробная информация о регулярных выражениях представлена в официальной справке Google, а также на тематических форумах по программированию, некоторых интернет-изданиях и блогах.
Несколько примеров использования регулярных выражений в Google Analytics
- при настройке цели
В предыдущем материале по настройке целей мы с вами разбирали пример, когда конечная url-ссылка содержит динамический параметр: ID заказа.
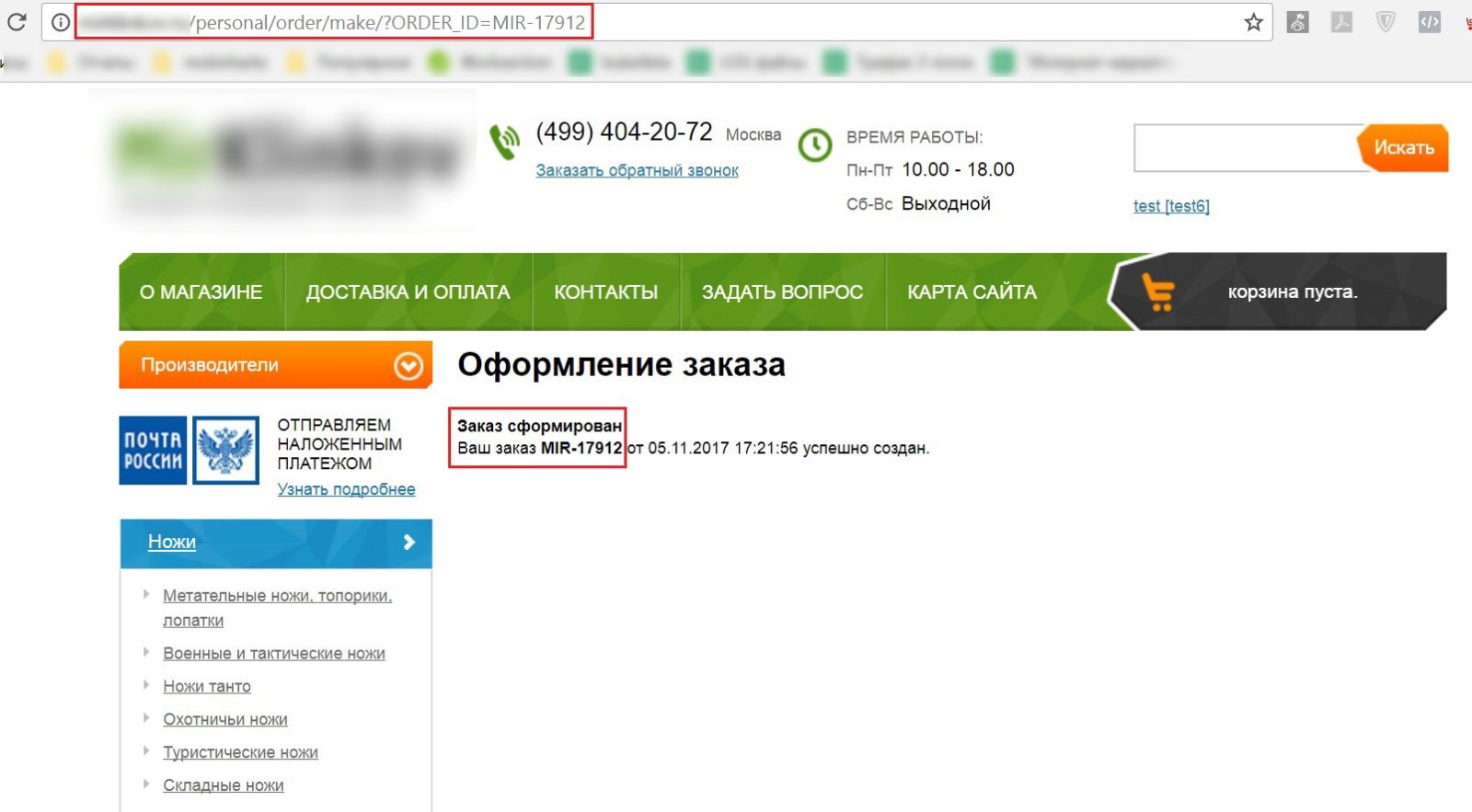
Динамический параметр в ссылке
Тогда мы использовали тип соответствия «начинается с» и добавляли в переход /personal/order/make/?ORDER_ID=

Цель с типом соответствия "Начинается с"
Однако при такой настройке цели мы учитываем и переходы, связанные не только с цифрами, но и буквами. То есть обычный пользователь может неправильно оформить заказ, в результате чего его перенаправит на страницу с ошибкой /personal/order/make/?ORDER_ID=error.
В этом случае нужно настроить цель, которая будет срабатывать, если в url-адресе есть пять цифр (каждый раз разные), и не должна срабатывать, когда цифр нет. Здесь нам и помогут регулярные выражения.
В результате нашу ссылку можно записать следующим образом:
Регулярное выражение в ссылке
-
- ^ - строка начинается с;
- \ - метасимвол экранирования, чтобы слэш обрабатывался как обычный символ;
- \d{1,5} – обозначает ровно 5 цифр.
- в отчетах отфильтровать трафик только по двум источникам – yandex и google.
Делается это с помощью простой конструкции ИЛИ регулярного выражения ( | ), а именно (google|yandex). Результат операции – все строки с этими значениями.
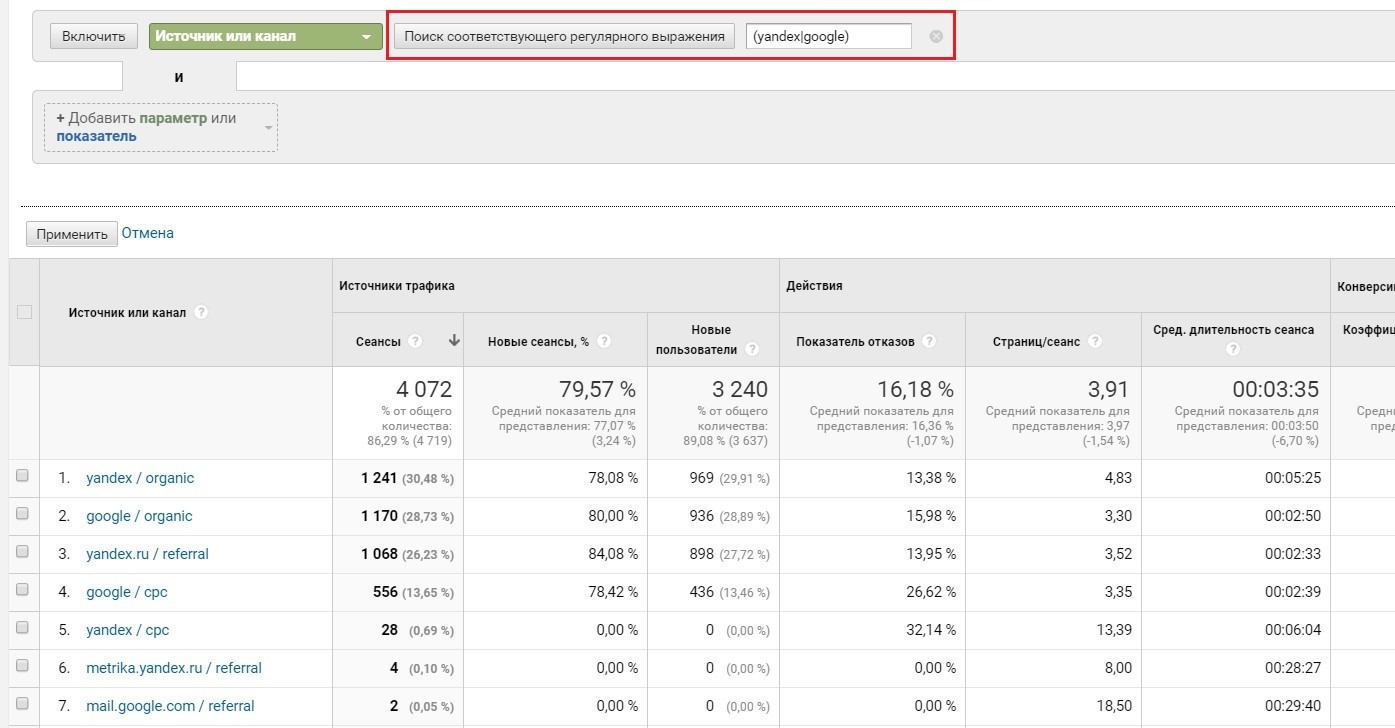
Регулярные выражения в расширенном фильтре
Если мы хотим сделать фильтр, оставив только рекламный трафик (cpc) с двух рекламных источников, то регулярное выражение будет выглядеть так: (google|yandex)\s\/\scpc

Регулярные выражения в расширенном фильтре
Аналогично можно фильтровать любые поисковые запросы по параметру ключевого слова, выделять не брендовый трафик, выбирать определенные категории страниц на сайте.
- ключевые слова, состоящие из n-ого количества слов
Регулярное выражение для одного слова ^[^\s]+$
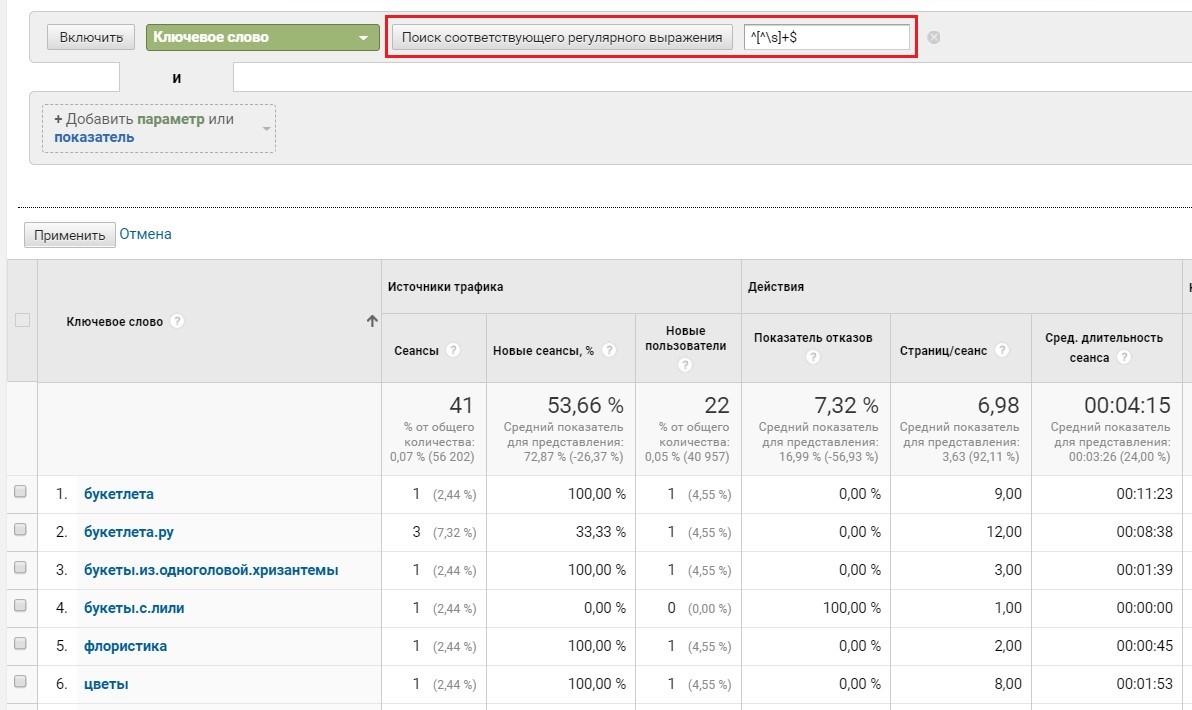
Все фразы, содержащие одно слово
Для фраз из двух слов ^[^\s]+(\s+[^\s]+){1}$ , трех ^[^\s]+(\s+[^\s]+){2}$ , четырех ^[^\s]+(\s+[^\s]+){3}$ и т.д.

Все фразы, содержащие три слова
- найти все страницы, которые содержат слово catalog
Используем регулярное выражение .*catalog.* (не имеет значения, что идет до и после нужного слова)
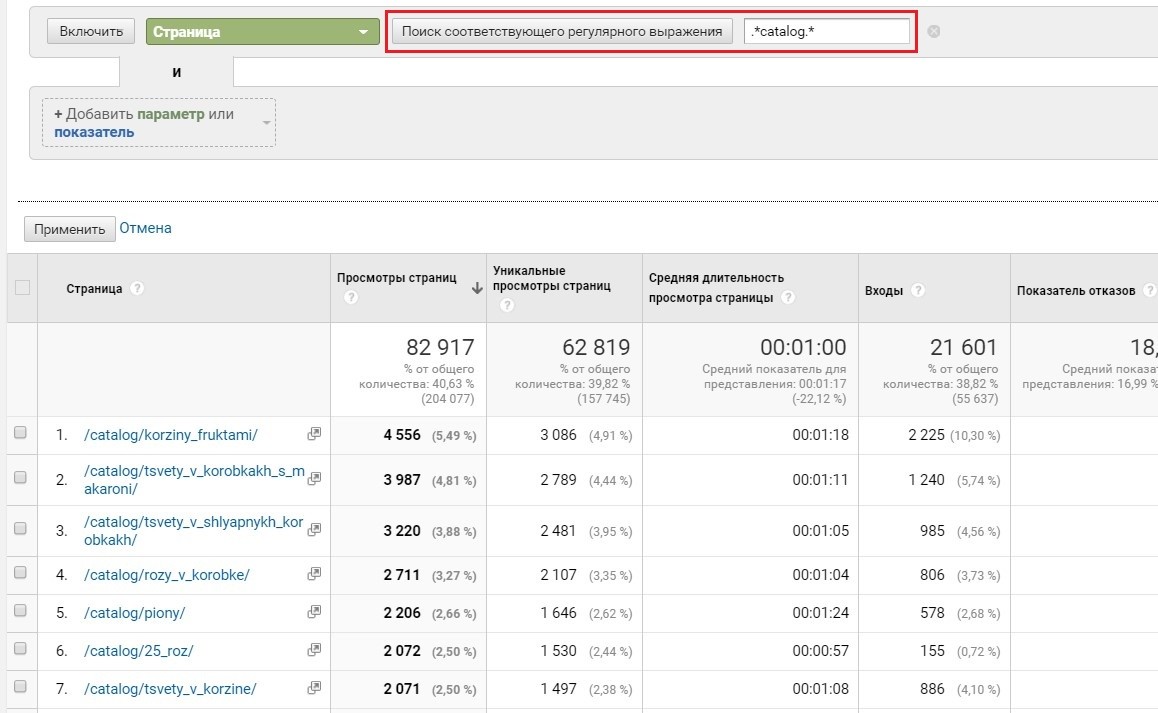
Все страницы, которые содержат слово catalog
Самый простой способ протестировать регулярное выражение в Google Analytics – это создать фильтр в любом стандартном отчете (как в примере выше). Также в интернете есть большое количество сервисов и расширений для браузеров:
- regex101.com
- regexr.com
- regextester.com
- Regular Expression Checker of javascript от Google
- RegExp Tester - дополнение для браузера Google Chrome





