Переменная уровня данных: Версия 1 vs Версия 2
Продолжаем разбираться в тонкостях работы dataLayer. Из этой статьи вы узнаете в чем принципиальное отличие переменной уровня данных версии 1 от версии 2.
Другие материалы про уровень данных:
- Что такое dataLayer?
- Способы формирования dataLayer
- Извлечение данных из dataLayer
- Переменные с точечной нотацией
- Отслеживание кликов с помощью dataLayer
Когда вы работаете с диспетчером тегов Google и хотите извлечь некоторое значение из уровня данных, вы используете пользовательскую переменную Переменная уровня данных, в которой помимо указания имени переменной уровня данных вы можете выбрать еще и версию - 1 или 2:
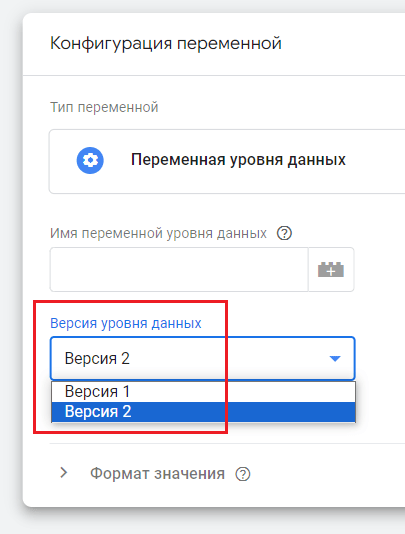
Версия уровня данных
Что же такое Версия 1 и Версия 2? И как ее выбор влияет на итоговые данные?
Уровень данных представляет собой объект JavaScript, который хранит и передает информацию с вашего сайта в Google Tag Manager. Он состоит, как правило, из ряда других простых объектов, помещенных в него:
dataLayer - объект, состоящих из других простых объектов
С помощью переменной уровня данных вы можете извлекать из dataLayer определенные значения и передавать их в другие системы вместе с тегом, например, в Google Analytics 4. А от выбора версии будет зависеть то, как Google Tag Manager будет обрабатывать эти значения.
В качестве примера давайте рассмотрим несколько событий электронной торговли. Например, в представленном ниже событии view_item_list (показ нескольких товаров в списке) в уровне данных присутствует объект ecommerce, в котором передается массив items с несколькими товарами:
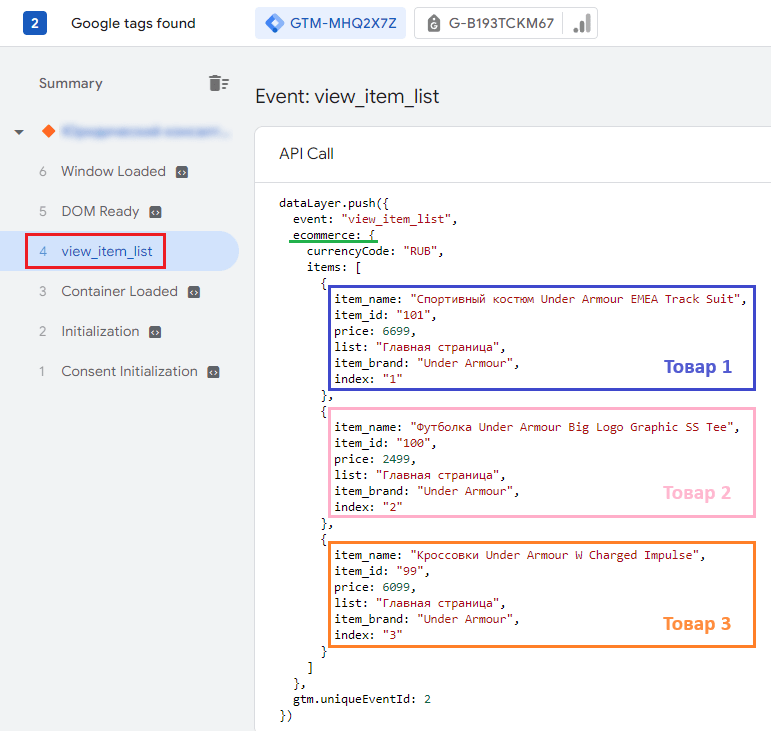
Событие электронной торговли с массивом items и несколькими товарами
Теперь создадим две переменных уровня данных с именем ecommerce, только одну с версией 1, а другую с версией 2, чтобы визуально увидеть различия:
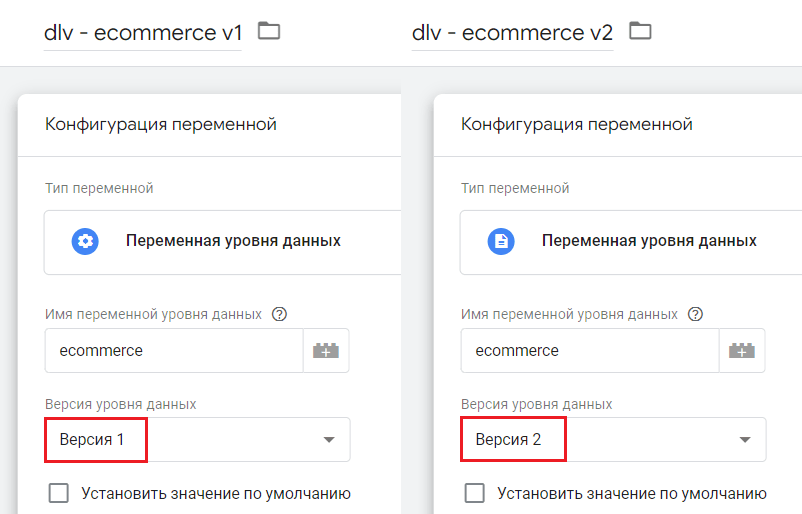
Две переменных уровня данных с разными версиями 1 и 2
Запустив режим предварительного просмотра, на вкладке Variables для данного события вы увидите, как две переменные разных версий возвращают одни и те же значения, которые являются объектом, содержащим массив items со всеми товарами в списке:
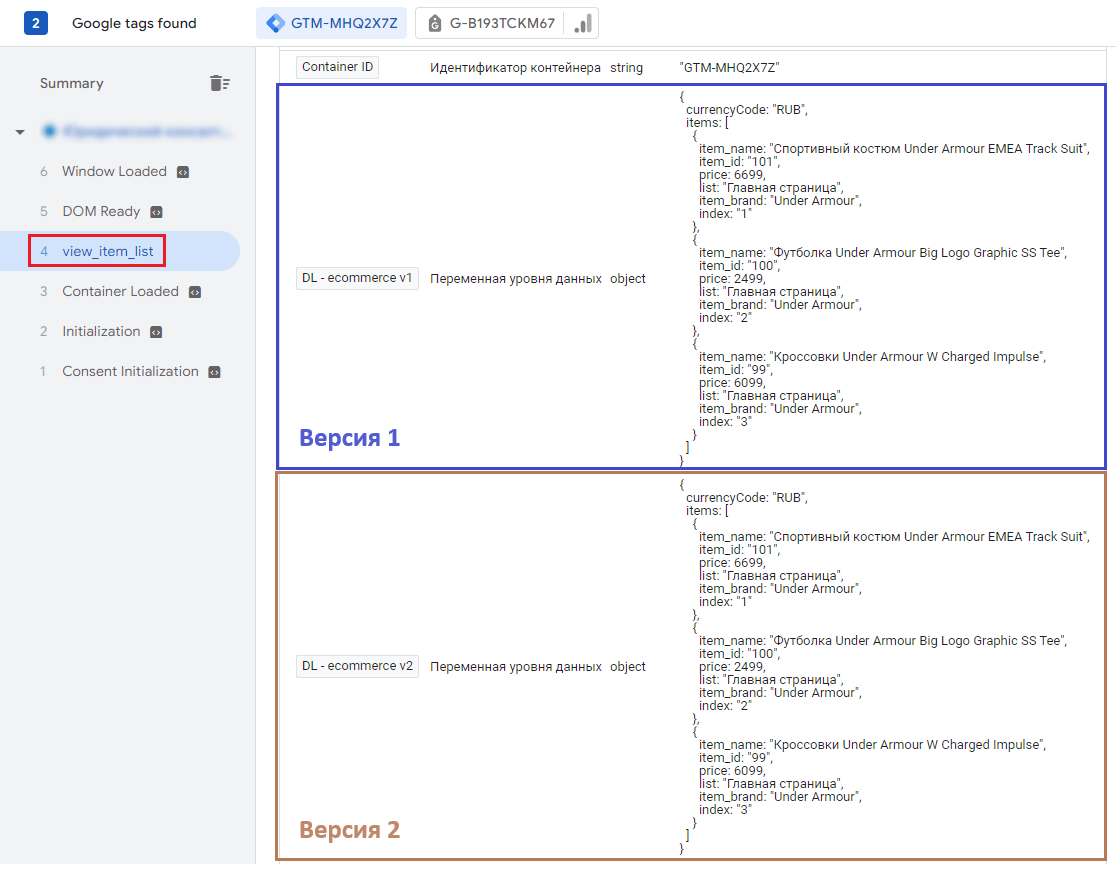
Значения переменных уровня данных для двух версий одинаковы
А теперь давайте на этой же странице отправим еще одно событие электронной торговли, например, view_item (просмотр конкретного товара). На уровне данных будет также присутствовать объект ecommerce, в котором передастся массив items с просмотренным товаром:
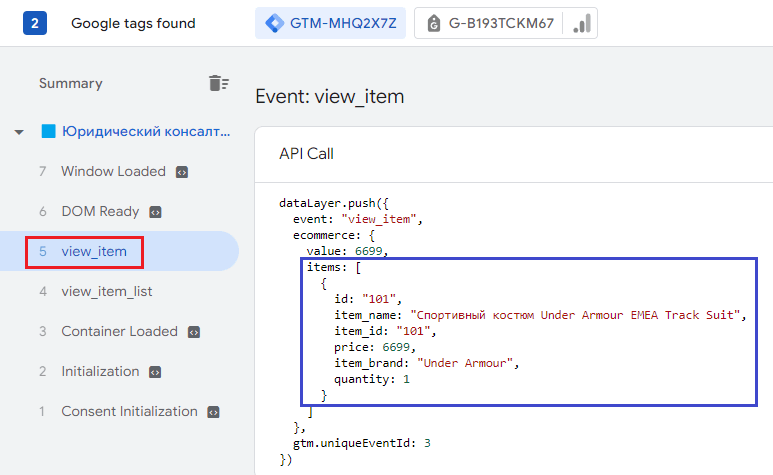
Событие электронной торговли с массивом items и просмотренным товаром
И снова обратимся к вкладке Variables, на которой значения двух версий переменной уровня данных будут отличаться:
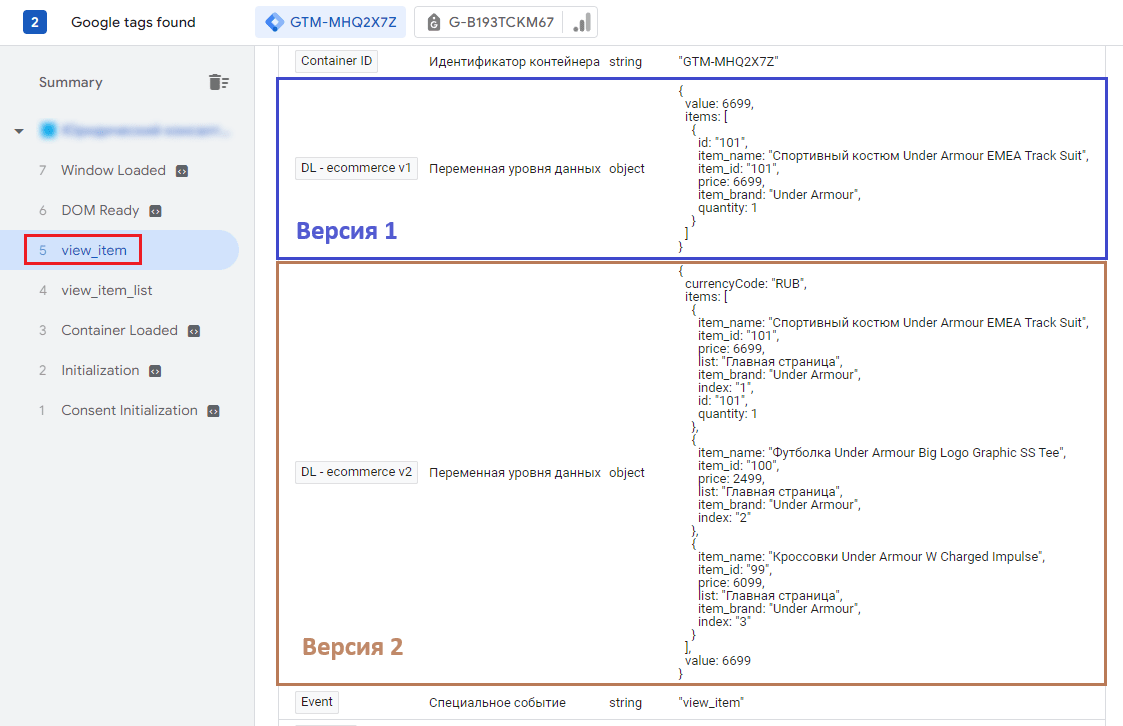
Значения переменных уровня данных для двух версий различны
Переменная уровня данных версии 1 состоит только из одного продукта, в то время как версия 2 возвращает объект электронной торговли с несколькими товарами, объединенными рекурсивно. Под рекурсивностью подразумевается слияние (merge). Это операция над объектами, которая выполняет их объединение. Она появляется там, где необходимо данные одного объекта перенести в другой объект.
Например, когда пользователь переходит на страницу с конкретным товаром, мы можем передать событие электронной торговли view_item. В этот момент посетитель просматривает всего один товар, поэтому вместе с событием будет передан параметр quantity = 1:
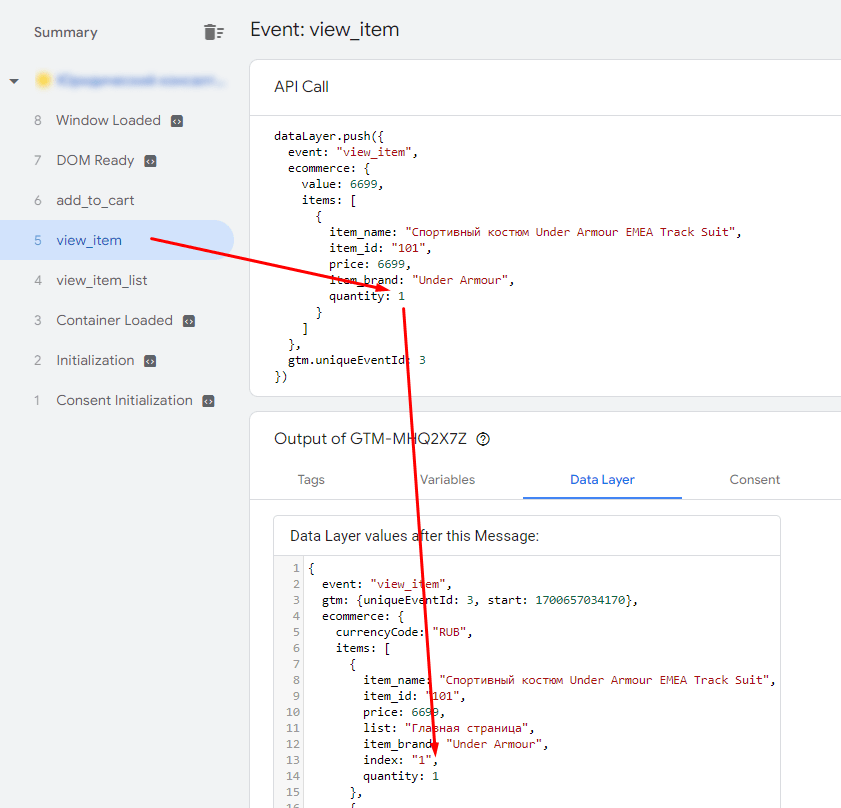
Одно значение параметра на уровне данных
Но пользователь на этой же странице может добавить товар в корзину, тем самым вызвать событие электронной торговли add_to_cart. И добавить он может не один товар, а несколько, например, 3 (quantity = 3). И тогда уровень данных должен будет что-то сделать с этой информаций - перезаписать или объединить с предыдущим значением?
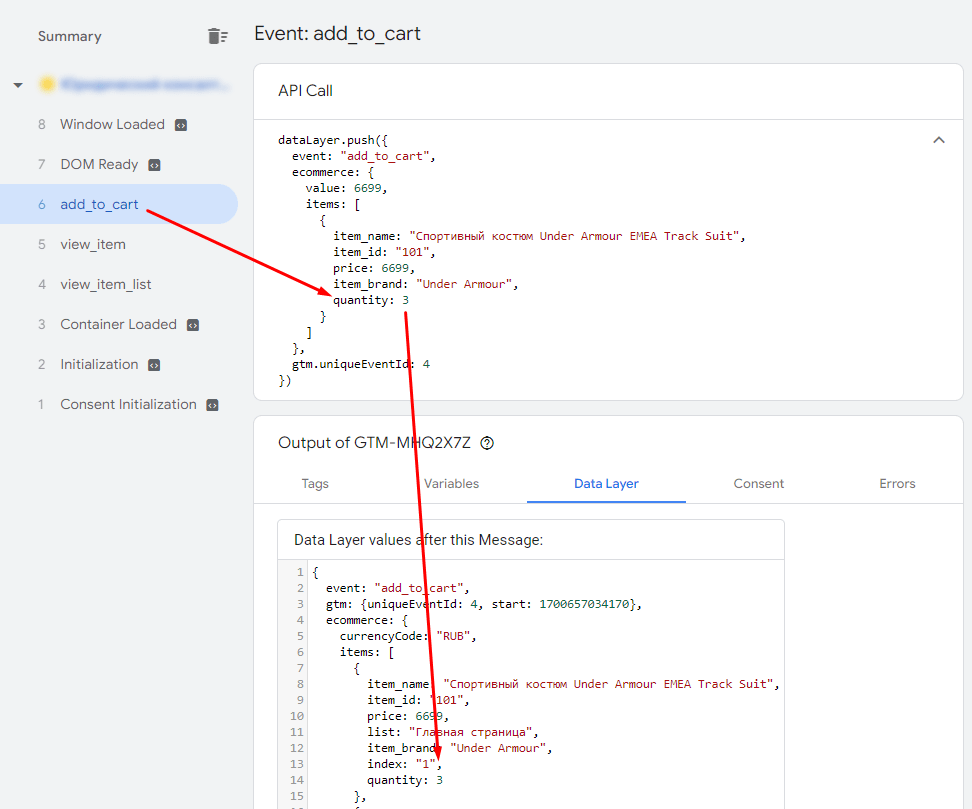
Измененное значение параметра на уровне данных
На самом деле эта не такая простая тема, как кажется на первый взгляд, поскольку уровень данных (dataLayer) тесно связан с таким понятием, как модель данных (data model). И хоть и там и там есть схожие слова, это не одно и то же. Об этом еще в 2014 году подробно описал Симо Ахава (Simo Ahava) в своем блоге.
Модель данных (Data Model) - это представление ключей/значений, которые вы перечисляете в dataLayer. Всякий раз, когда вы вставляете какой-либо ключ в dataLayer, Google Tag Manager захватывает его и обновляет в своей модели данных новым значением или, в случае объектов и массивов, объединяет старое и новое значение вместе. Однако диспетчер тегов Google не имеет прямого доступа к структуре уровня данных, поскольку это поставило бы под угрозу общую и не зависящую от инструмента цель уровня данных. Правильнее говорить, что GTM извлекает информацию из уровня данных, сохраняет ее в своей внутренней "абстрактной" модели данных и использует ее для обработки данных.
Модель данных для каждого инструмента может быть своей (вспомните про eventModel для Google Analytics и библиотеки gtag.js), а вот уровень данных должен быть общим и универсальным для различных сервисов и инструментов, чтобы из него можно было извлекать информацию и передавать в сторонние системы. Именно поэтому Яндекс.Метрика понимает события электронной коммерции, реализованные с помощью dataLayer, или VK Реклама, которая тоже поддерживает слой данных.
Проводя сравнения между уровнем данных и моделью данных, можно воспользоваться простой таблицей самого Симо:
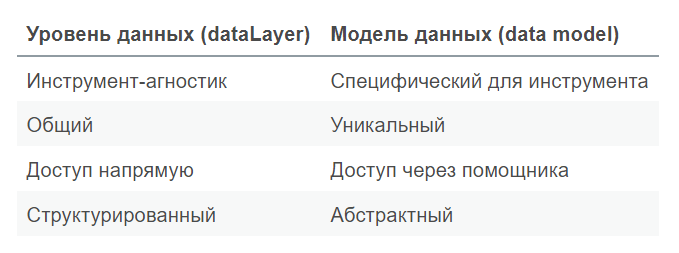
Сравнение модели данных и уровня данных
Некоторым из вас эти различия могут показаться очень незначительными или запутанными, но на самом деле они есть, и именно они гарантируют, что уровень данных остается общедоступным стандартизированным контейнером для ваших данных. Модель данных (data model), с другой стороны, строится в соответствии со спецификациями каждой платформы (сервисом/инструментом), но способ ее взаимодействия с уровнем данных (dataLayer) должен быть ясным и понятным и, возможно, даже стандартизированным, поскольку только так мы можем гарантировать, что один инструмент не испортит уровень данных для всех.
Примечание: у каждого инструмента может быть своя специфичная модель данных, но уровень данных, с которым мы работаем в Google Tag Manager - общий и универсальный для различных платформ.
Получается, что Google Tag Manager фактически не обращается к dataLayer, когда вы создаете переменные уровня данных. Вместо этого, когда объект помещается в dataLayer, он становится доступным для модели данных GTM, и любые создаваемые вами переменные уровня данных будут ссылаться на эти экземпляры (ключи и значения) в модели данных, а не напрямую обращаться к самому массиву. Почему? Чтобы отделить массив от внутренних механизмов подключенной платформы, то есть от Google Tag Manager. Это важно, поскольку чем меньше диспетчеру тегов Google нужно полагаться на "абстрактную" модель данных, которой в любой момент можно манипулировать с помощью небрежного кода или другой подключенной платформы, тем лучше.
Как вы уже знаете, Google Tag Manager извлекает информацию из уровня данных, сохраняет ее в своей внутренней "абстрактной" модели данных и использует ее для обработки данных. Это означает, что по мере того, как каждое действие/событие помещается на уровень данных, "абстрактная" модель данных должна обновляться. Что-то на странице произошло, на шкале событий GTM это отобразилось -> модель данных обновилась.
По мере обработки каждого сообщения его пары ключ/значение будут добавляться в "абстрактную" модель данных. Если ключ в настоящее время не существует в модели, эта пара просто добавляется к объекту модели. Но в случае конфликтов ключей нам необходимо указать, как значения будут перезаписаны и/или объединены.
Таким образом, существует два возможных действия при слиянии пары ключ/значение с "абстрактной" моделью данных:
- перезапись существующего значения;
- рекурсивное слияние (объединение) нового значения с существующим значением.
В зависимости от типов данных, над которыми будет производиться перезапись или объединение, возможны различные варианты. Для этого Google на своей официальной странице GitHub приводит следующую градацию возможных типов данных, с которыми, вероятно, вы можете столкнуться:
- массивы JavaScript (arrays);
- "простые" объекты (plain objects);
- все остальное (other).
Массивы JavaScript - это особый тип объекта, предназначенный для работы с упорядоченным набором элементов. В массиве хранятся значения смешанных типов. То есть, массив может содержать в себе числа, строки и объекты других массивов. Пара квадратных скобок [] обозначает массив, элементы разделяются запятыми , Положение элемента в массиве обозначается индексом (отсчет начинается с нуля). Например:
|
1 2 3 4 5 |
var analytics = ["Google Tag Manager", "Google Analytics 4", "Looker Studio"]; analytics[0] // Google Tag Manager analytics[1] // Google Analytics 4 analytics[2] // Looker Studio |
"Простые" объекты - это объекты JavaScript, созданные с помощью литеральной нотации объекта, то есть он описывается внутри блока фигурных скобок {}, как набор разделенных запятой пар ключ/значение. После имени ставится двоеточие. Например:
|
1 2 3 4 5 |
var google = { // объект founder1: "Larry", // под ключом "founder1" хранится значение "Larry" founder2: "Sergey", // под ключом "founder2" хранится значение "Sergey" age: 1998 // под ключом "age" хранится значение 1998 }; |
- Первое свойство с именем "founder1" и значением "Larry";
- Второе свойство с именем "founder2" и значением "Sergey";
- Третье свойство с именем "age" и значением 1998.
Свойство – это пара ключ:значение, где ключ – это строка или символ (также называемая именем свойства), а значение может быть любого типа данных. Свойства объекта также иногда называют полями объекта.
Подробнее про различные типы данных, которые поддерживает Google Tag Manager, читайте в этой статье.
Null, Date, RegExp, Window, DOM Elements не являются простыми. Они попадают в категорию Все остальное (0ther) вместе с string, number, boolean, undefined и т.д.
После того, как тип новых и существующих значений будет определен, мы можем воспользоваться нижеприведенной таблицей, чтобы описать, какое действие произойдет для этой пары ключ/значение:
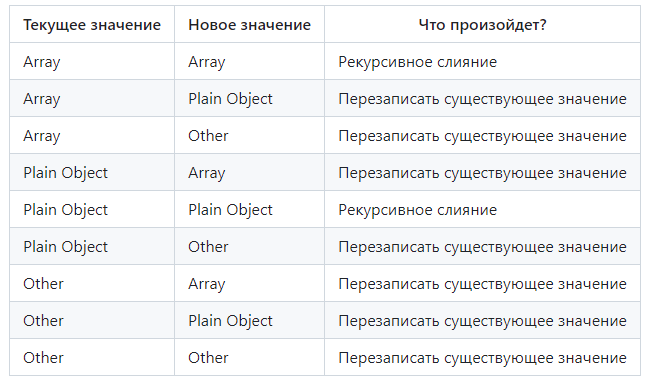
Таблица сопоставления данных, которые будут объединены
Примечание: в таблице Array - массив, Plain Object - простой объект, Other - все остальное.
Когда действием является перезапись существующего значения (overwriting existing values), результат операции очень прост - существующее значение будет полностью отброшено, а новое значение займет свое место в абстрактной модели данных. В следующей таблице приведены некоторые примеры:
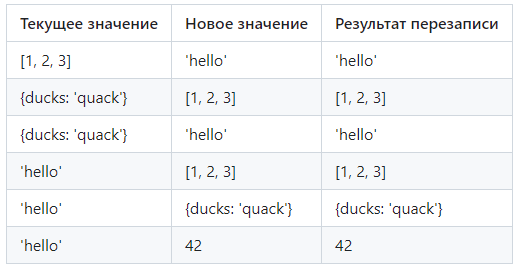
Результат перезаписи
Если действием объединения является рекурсивное слияние (recursively merging), результатом операции будет являться перебор каждого свойства в новом значении и для каждого свойства будет приниматься решение о том, как скопировать этот подключ/значение в абстрактную модель данных. Если ключа для существующего значения не существует, новое значение просто присваивается абстрактной модели.
Следующие примеры с массивами и объектами демонстрируют это:
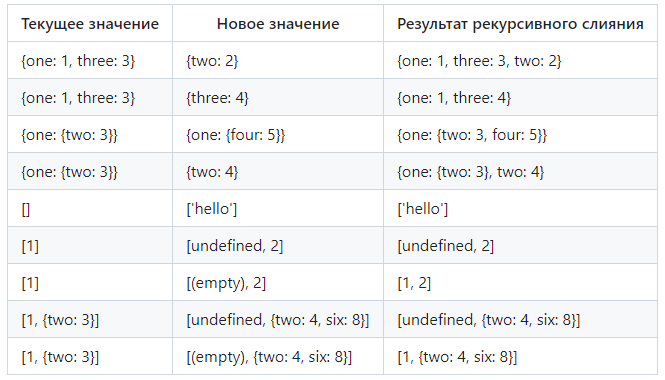
Результат рекурсивного слияния
Вполне вероятно, что все вышеприведенное может показаться сложным, избыточным и не иметь никакого|прямого отношения к переменной уровня данных GTM версии 1 и версии 2. Но это не так. Именно пример рекурсивного слияния для двух объектов даст нам конечное понимание того, как данные извлекаются из уровня данных и сохраняются в переменной для двух разных версий. Это нужно, чтобы раз и навсегда разобраться в вопросе, связанным с выбором версии для переменной уровня данных.
Давайте на примере одного и того же события электронной торговли произведем рекурсивное слияние двух объектов. За основу возьмем событие все те же два события view_item_list и view_item, что и в руководстве выше поочередно срабатывающее два раза на одной и той же странице. Уровень данных будет такой:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
window.dataLayer = window.dataLayer || []; window.dataLayer.push({ 'event': 'view_item_list', ecommerce: { items: [ { item_name: "Спортивный костюм Under Armour EMEA Track Suit", item_id: "101", price: 6699, list: "Главная страница", item_brand: "Under Armour", index: "1", }, { item_name: "Футболка Under Armour Big Logo Graphic SS Tee", item_id: "100", price: 2499, list: "Главная страница", item_brand: "Under Armour", index: "2", } ] } }) |
Как и в примере в самом начале, статьи в режиме отладки Google Tag Manager две версии переменной уровня данных будут иметь одинаковые значения:
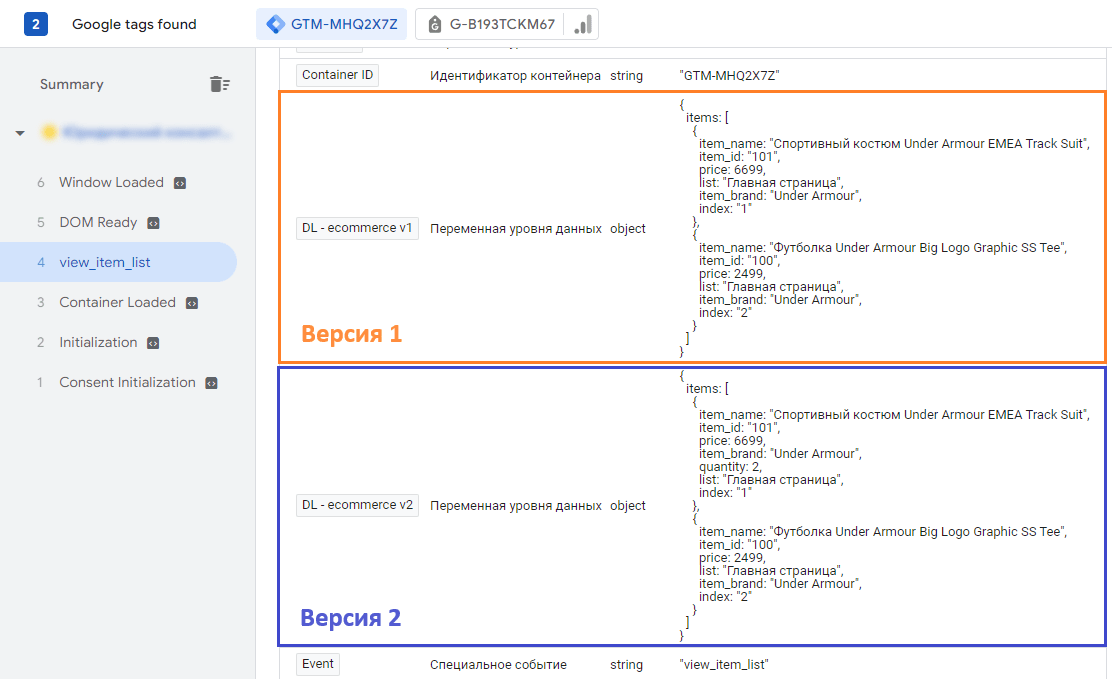
Значения переменных уровня данных для двух версий одинаковы
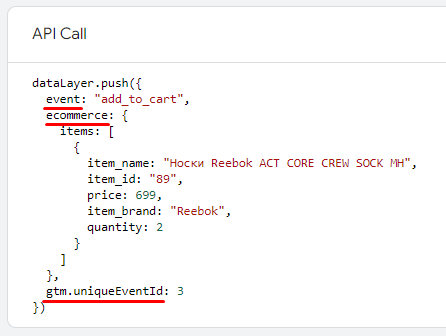
А теперь давайте на этой же странице отправим событие add_to_cart с таким уровнем данных:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
window.dataLayer = window.dataLayer || []; window.dataLayer.push({ 'event':"add_to_cart", ecommerce: { items: [ { item_name: "Носки Reebok ACT CORE CREW SOCK MH", item_id: "89", price: 699, item_brand: "Reebok", quantity: 2, } ] } }) |
Когда мы откроем вкладку Variables, то увидим, что значения в переменных уровня данных для двух версий будут различаться:
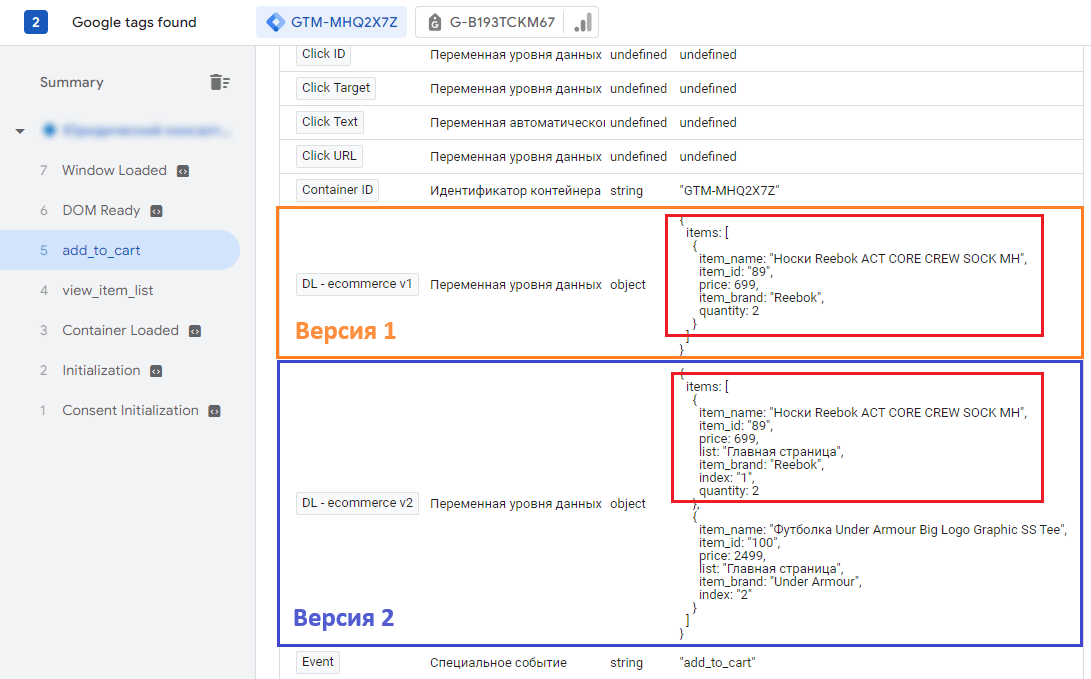
Значения переменных уровня данных для двух версий различны
Первый объект после события view_item_list имел значение:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "items": [ { "item_name": "Спортивный костюм Under Armour EMEA Track Suit", "item_id": "101", "price": 6699, "list": "Главная страница", "item_brand": "Under Armour", "index": "1" }, { "item_name": "Футболка Under Armour Big Logo Graphic SS Tee", "item_id": "100", "price": 2499, "list": "Главная страница", "item_brand": "Under Armour", "index": "2" } ] } |
А второй объект add_to_cart был таким:
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "items": [ { "item_name": "Носки Reebok ACT CORE CREW SOCK MH", "item_id": "89", "price": 699, "item_brand": "Reebok", "quantity": 2 } ] } |
Для версии 1 в переменную уровня данных Google Tag Manager просто записал текущее (последнее) значение массива items из события add_to_cart, а предыдущее значение массива items из события view_item_list стер, в то время как для версии 2 Google Tag Manager рекурсивно объединил новые данные с предыдущим значением из события view_item_list, заменив первый элемент массива на новый из add_to_cart:

Рекурсивное слияние для переменной уровня данных версии 2
В результате переменная уровня данных с версией 2 стала иметь такое значение:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ items: [ { item_name: "Носки Reebok ACT CORE CREW SOCK MH", item_id: "89", price: 699, list: "Главная страница", item_brand: "Reebok", index: "1", quantity: 2 }, { item_name: "Футболка Under Armour Big Logo Graphic SS Tee", item_id: "100", price: 2499, list: "Главная страница", item_brand: "Under Armour", index: "2" } ] } |
Если бы в новом объекте было бы тоже два значения, то Google Tag Manager заменил бы оба элемента массива items на новые. Было бы три -> все три были бы обновлены.
Вместо перебора существующих ключей в версии 2 GTM сначала проверяет, существует ли уже ключ с таким именем в модели данных. Если это так, он рекурсивно проверяет каждый ключ внутри этого объекта на наличие конфликтов. Сначала он проверил параметр item_name внутри items, и заметил, что данный ключ присутствует в двух объект. Затем он проверяет, является ли item_name также простым объектом или массивом, чтобы увидеть, следует ли ему выполнить еще одно рекурсивное слияние глубже в структуре или нет. Однако значением item_name является строка, что означает, что рекурсивное слияние не выполняется, и новое значение перезаписывает старое. Именно поэтому в новом объекте с версией 2 параметр item_name был перезаписан с Спортивный костюм Under Armour EMEA Track Suit на Носки Reebok ACT CORE CREW SOCK MH.
Затем Google Tag Manager проверяет следующий параметр item_id. Аналогичным образом он производит рекурсивное слияние, перезаписывая старое значение в первом объекте новым из второго. Получается, что 101 заменяется на 89. Далее параметр price - он присутствует в двух объектах, и в результате перезаписывается в выходном третьем объекте для версии 2. Перезаписывается и значение для параметра item_brand. А вот параметров list и index во втором объекте нет (они есть только в первом объекте и отмечены черным), поэтому данные не перезаписываются, а дополнительно добавляется к новому объекту.
В результате для версии 2 в Google Tag Manager вы видите новый объект, рекурсивно объединенный. А в версии 1 весь объект просто перезаписывается.
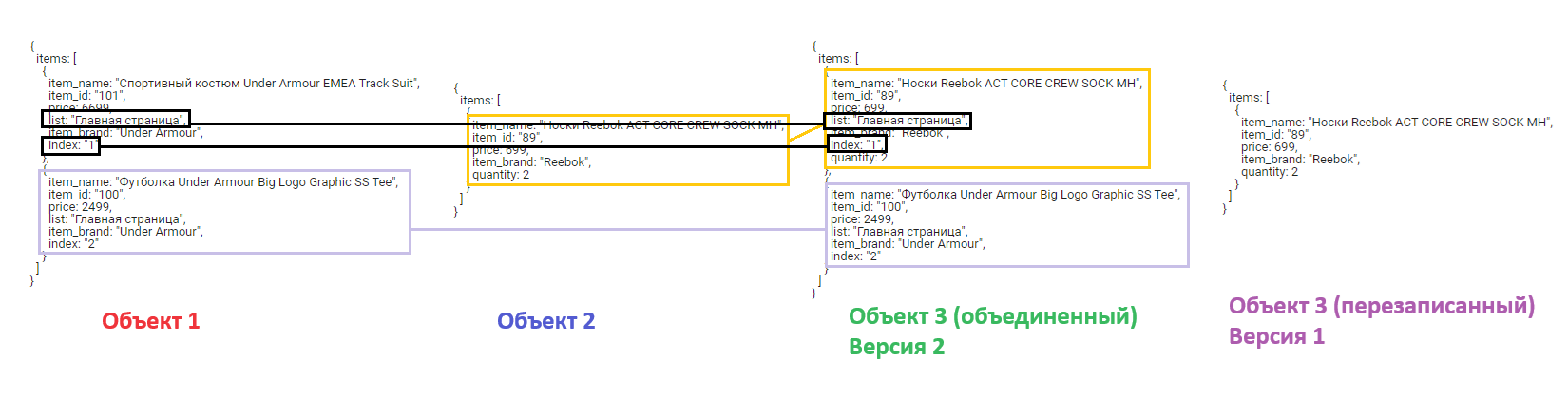
Визуальное представление версии 1 и 2 (объединение и перезаписи)
Таким образом, используя версию 2 переменной уровня данных, разрешение конфликтов в именах ключей объекта сначала предпринимается путем слияния двух объектов. Но если для каких-либо ранее существовавших ключей существуют новые "примитивные" значения, они перезаписываются точно так же, как в версии 1 переменной уровня данных.
Для тех, кто хочет углубиться в объединение нескольких объектов разными способами, я рекомендую посмотреть это видео:
В нем подробно рассказывается, как объединить два объекта в JavaScript с помощью трех вариантов:
- с помощью оператора spread;
- с использованием метода Object.assign();
- простым циклом for.
Однако версия 1 имеет существенный недостаток - она не поддерживает точечную нотацию. Например, если вы хотите извлечь значение какого-нибудь параметра из уровня данных (например, item_brand), а затем передать его в сторонние системы (Яндекс.Метрику, VK Рекламу и другие), то для этого вам в GTM необходимо будет создать переменную уровня данных и использовать точку в качестве разделителя между уровнями:
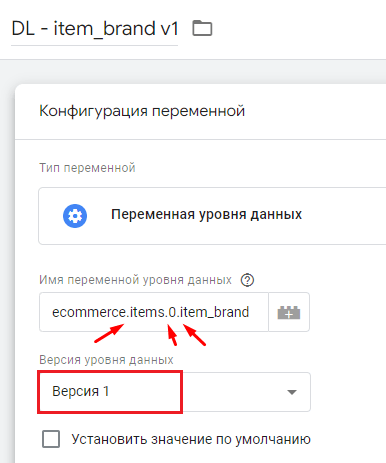
Переменная уровня данных с точечной нотацией (версия 1)
Но когда вы посмотрите в режиме отладки значение этой переменной, то увидите undefined:
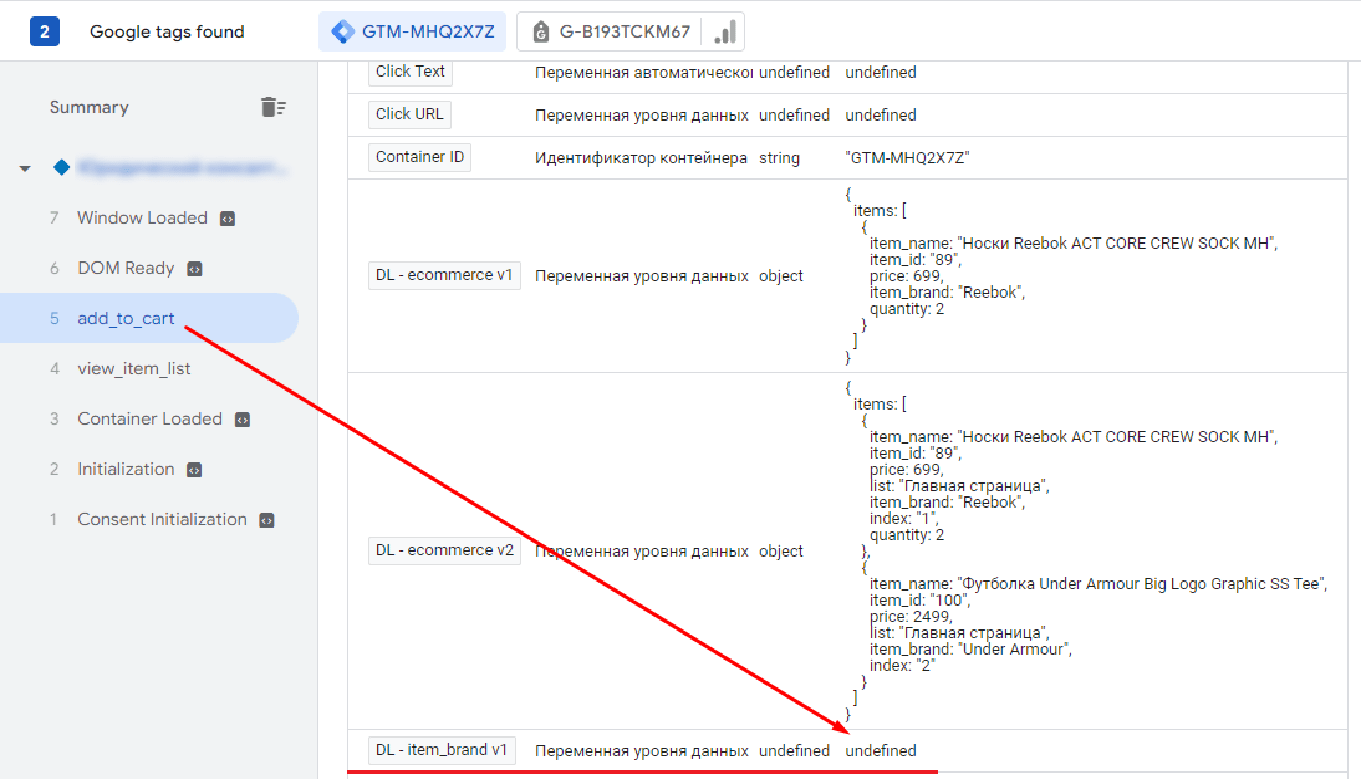
Версия 1 не поддерживает точечную нотацию
Но если вы создадите переменную уровня данных версией 2 с тем же именем:
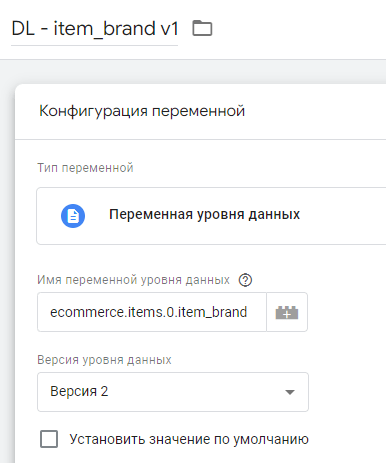
Переменная уровня данных с точечной нотацией (версия 2)
То она сможет извлечь значение из соответствующего ключа:
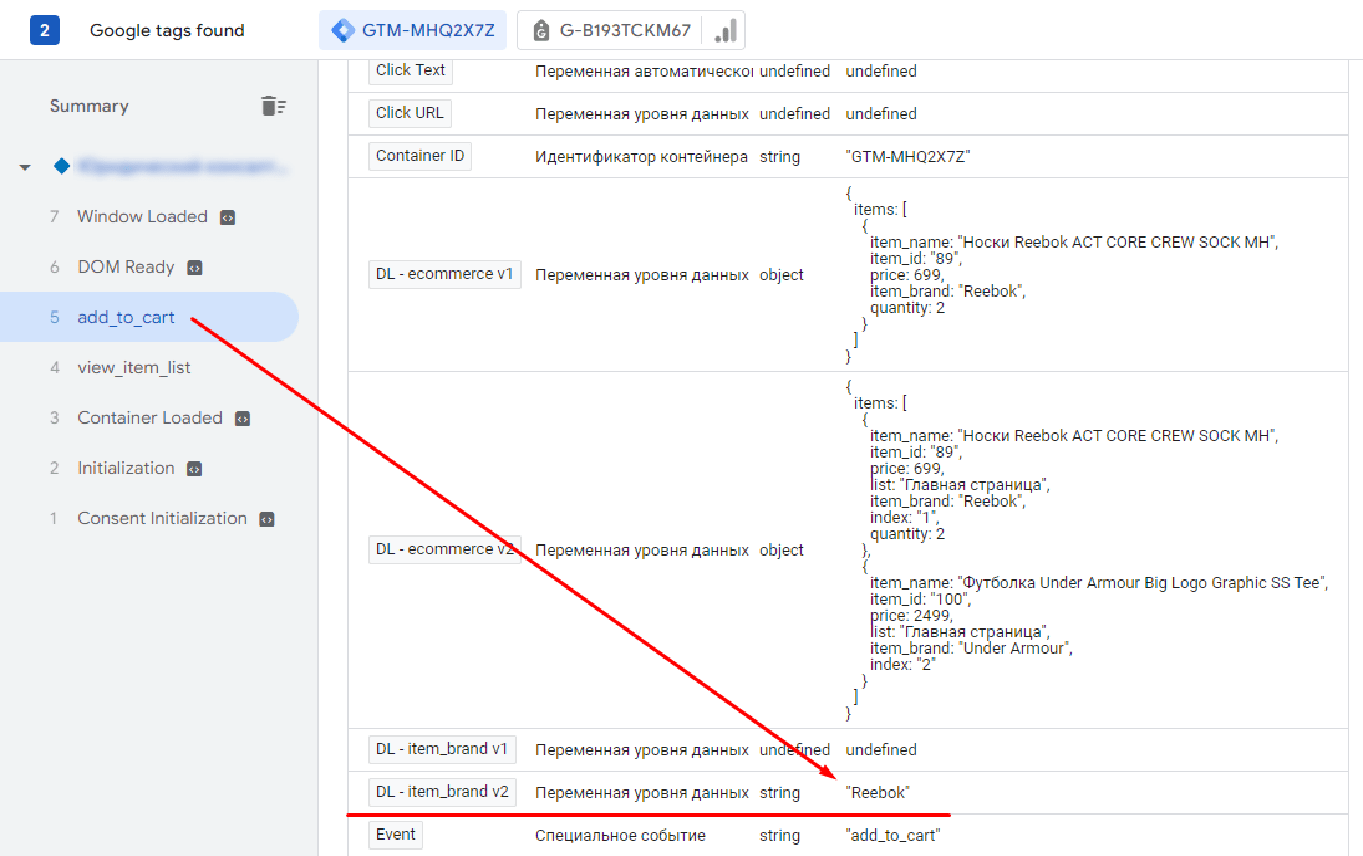
Версия 2 поддерживает точечную нотацию
Версия 1 поддерживает извлечение только на верхнем уровне, без вложенности внутри объекта. Поэтому при создании переменной уровня данных с версией 1 вы можете использовать только ключи на верхнем уровне:
Версия 1 только для ключей верхнего уровня
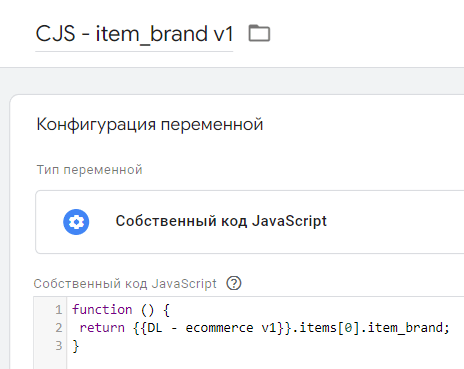
Версия 2 поддерживает точечную нотацию. Однако если вам все-таки нужно использовать переменную уровня данных с версией 1, то вы можете пойти обходным путем и для извлечения вложенных элементов использовать другую пользовательскую переменную - Собственный код JavaScript. В ней вы можете ссылаться на переменную уровня данных версии 1 и указать только тот ключ, значение которого хотите получить. Например, для все того же параметра item_brand код переменной будет таким:
|
1 2 3 |
function () { return {{DL - ecommerce v1}}.items[0].item_brand; } |
, где:
- {{DL - ecommerce v1}} - название вашей переменной уровня данных версии 1, где именем является ecommerce,
- items[0].item_brand - это путь к ключу item_brand;
- [0] - обращение к первому элементу в массиве.
Между уровнями так же используется точечная нотация (точки). В Google Tag Manager переменная будет выглядеть так:
Собственный код JavaScript
Запустив режим отладки диспетчера тегов Google, вы убедитесь, что данная переменная возвращает нужное значение ключа item_brand:
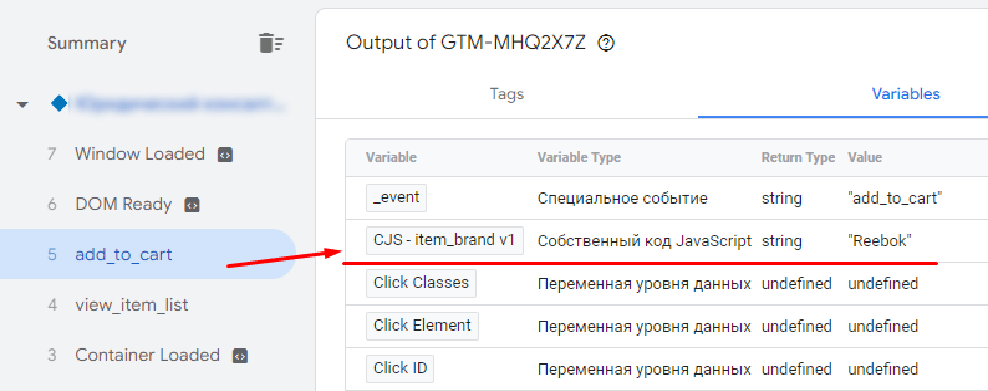
Корректно извлеченное значение с помощью собственного кода JS и переменной уровня данных версии 1
Иногда вам может потребоваться избежать сохранения значений, полученных ранее. Это особенно актуально для одностраничных приложений (SPA-сайтов), где вам не нужна устаревшая информация в модели данных при переходе из одного раздела в другой раздел без перезагрузки страницы. Чтобы предотвратить такое рекурсивное слияние по умолчанию, вам нужно поместить ключ _clear со значением true в тот же объект, куда вы вставляете ключи, которые вы не хотите объединять. Подробнее про предотвращение рекурсивного слияния с помощью _clear вы можете почитать на официальной странице Google в GitHub, а также в этой статье Симо.
Почему существует версия 1 и когда ее использовать? Один из примеров ее использования - расширенная электронная торговля (была в Universal Analytics). Используя переменную Собственный код JavaScript и переменную уровня данных ecommerce с версией 1, вы можете иметь доступ к самому последнему значению в dataLayer. Сработало событие -> значение отобразилось в dataLayer - сохранили его в собственную переменную и передали в какую-нибудь стороннюю систему аналитики или рекламы. С версией 1 вы будете точно уверены, что данные в dataLayer будут иметь самое последнее значение, и сможете избежать проблемы умножения отправляемых данных.
С версией 2, напротив же, из-за рекурсивного слияния часть информации может быть перезаписана, а часть объединена с предыдущим состоянием объекта. Однако оно может быть полезным для:
- обновления объекта по мере раскрытия дополнительной информации, например сбор истории взаимодействий на одной странице;
- обновления объекта по мере поступления дополнительной информации, например обновление объекта пользователя User Object (ввода или изменения персональных данных) по мере завершения определенных вызовов API;
- выполнение допустимого объединения двух объектов уровня данных в рамках одной страницы, например объединение событий электронной торговли view_item и add_to_cart.
Итого
Если кратко, то:
- переменная уровня данных версии 1 всегда перезаписывается, то есть от события к событию она будет меняться;
- переменная уровня данных версии 1 не поддерживает точечную нотацию. То есть вы не сможете извлечь значение какого-то конкретного ключа внутри объекта (например, товара). Для этого нужно использовать либо версию 2, либо же другую пользовательскую переменную типа Собственный код JavaScript, ссылаясь в ней на переменную уровня данных версии 1 и конкретный ключ с точечной нотацией;
- переменная уровня данных версии 1 была полезна в расширенной электронной торговли для передачи последнего значения с конкретным событием, так как оно всегда перезаписывалось и было актуальным на момент совершения event'а;
- переменная уровня данных версии 2 поддерживает точечную нотацию и позволяет обращаться к конкретному ключу внутри объекта;
- в версии 2 из-за рекурсивного слияния часть информации может быть перезаписана, а часть объединена с предыдущим состоянием объекта;
- рекурсивное слияние нескольких объектов в JavaScript возможно с помощью оператора spread, с использованием метода Object.assign() или выполняться простым циклом for;
- для предотвращения рекурсивного слияния по умолчанию вы можете использовать ключ _clear (актуально для одностраничных приложений, SPA-сайтов);
- в 95% проектах используется переменная уровня данных версии 2.



