Расчет сеансов Google Analytics 4 в Google BigQuery
В предыдущем материале мы подробно разобрали сеансы (sessions) в Google Analytics 4 для веб-потоков. В этом руководстве я покажу как можно запрашивать необработанные данные и рассчитывать сеансы в Google BigQuery.
После того, как вы установите связь вашего ресурса Google Analytics 4 с Google BigQuery, вы можете переходить к выполнению SQL-запросов.
Определение сеансов в Google Analytics 4:
Сеанс в Google Analytics 4 - это период времени, в течение которого пользователь взаимодействует с вашим сайтом или приложением. Сеанс начинается, когда пользователь просматривает страницу при отсутствии активного сеанса (это может происходить, например, когда превышено время ожидания предыдущего сеанса). По умолчанию сеанс завершается через 30 минут бездействия. Длительность сеанса при этом не ограничена.
Примечание:
- если вы будете копировать примеры SQL-запросов из этого руководства, пожалуйста, не забудьте менять путь к проекту, набору данных и таблице BigQuery на свои;
- если в вашем ресурсе Google Analytics 4 переопределен уникальный идентификатор пользователя Client ID на User ID, то вместо поля user_pseudo_id в BigQuery вам нужно использовать в запросах user_id.
Запрос №1. Количество сеансов за конкретный день
Когда пользователь переходит на сайт и у него начинается сессия, Google автоматически регистрирует событие session_start. Поэтому первый запрос, который мы выполним, будет подсчитывать количество сеансов на основе событий session_start.
Это событие хранится в поле event_name таблицы данных Google Analytics 4.
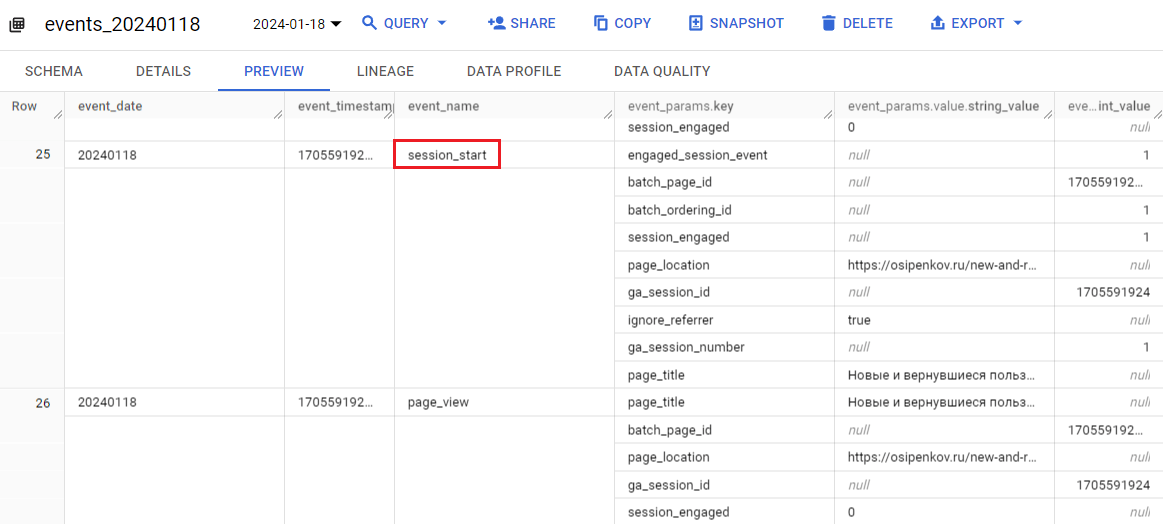
Событие session_start в поле event_name
Чтобы подсчитать количество сеансов на основе события session_start за конкретный день, используйте нижеприведенный запрос:
|
1 2 3 4 |
SELECT COUNTIF(event_name = "session_start") AS sessions FROM `osipenkovru-373609.analytics_206854065.events_20240118` |
, где:
- osipenkovru-373609 - ваш проект в Google Cloud;
- analytics_206854065 - ваш набор данных (датасет);
- events_20240118 - название таблицы с данными за конкретный день (в моем примере - 18 января 2024 года).
В Google BigQuery это будет выглядеть так:
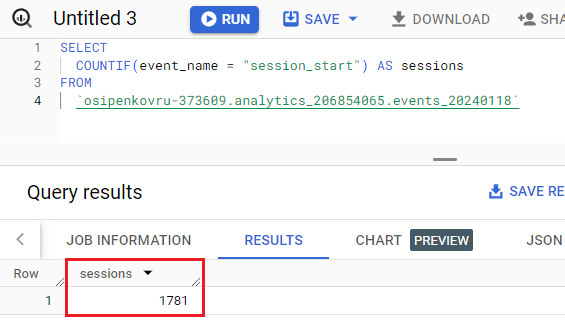
Запрос в Google BigQuery для конкретного дня
Вы также можете использовать чуть другой SQL-запрос:
|
1 2 3 4 5 |
SELECT COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_20240118` WHERE event_name = 'session_start' |
Результат его выполнения будет таким же.
Таким образом, уже даже на этом шаге, сопоставив данные из результата BigQuery с интерфейсными данными Google Analytics 4, вы можете сказать, что количество событий session_start за выбранный день +/- сходится.
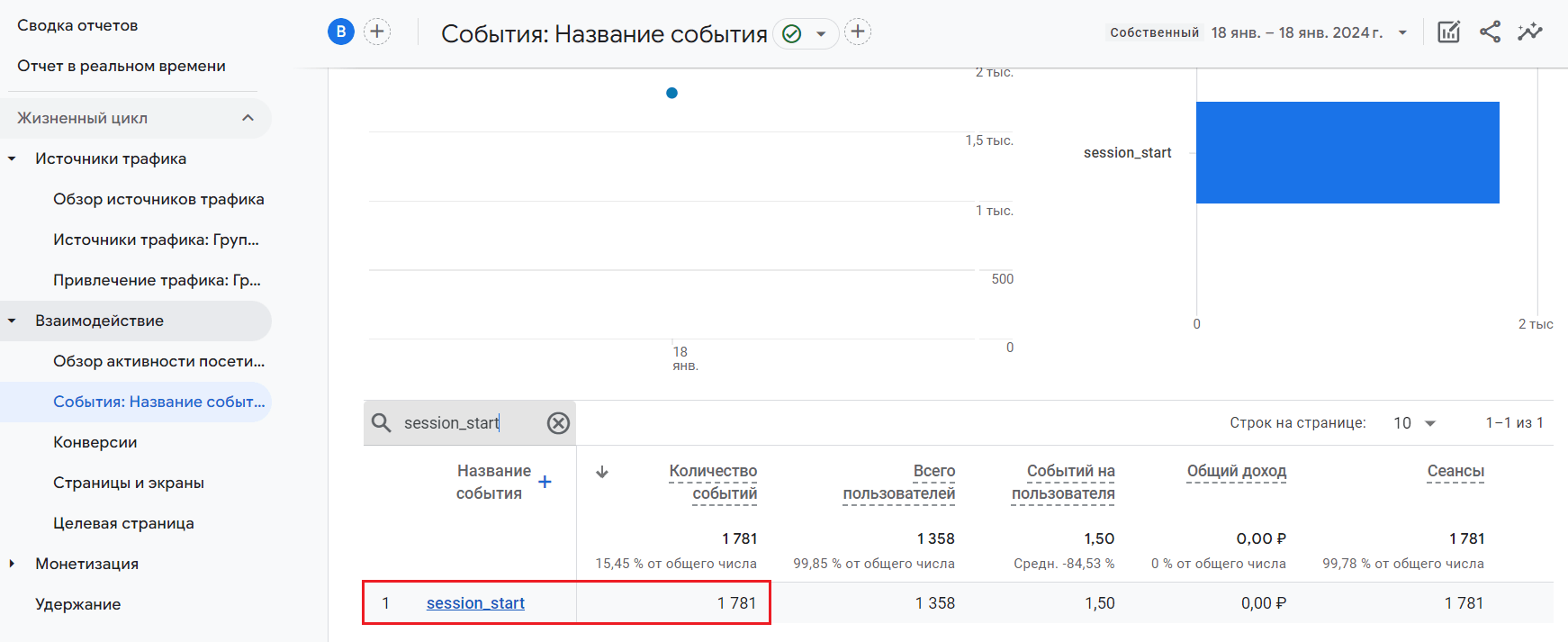
Отчет по событию session_start
Примечание: Google сам допускает расхождения между общим количеством событий в Google Analytics 4 и BigQuery, но оно, как правило, не превышает 2-5%.
Запрос №2. Количество сеансов за статический диапазон дат
В первом запросе вы подсчитали количество сеансов за конкретный день. Но что, если вы хотите подсчитать количество сеансов за несколько дней? Для этого нужно выполнить запрос, используя диапазон дат и подстановочный знак *.
Например, используя запрос из первого примера:
|
1 2 3 4 5 |
SELECT COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_20240118` WHERE event_name = 'session_start' |
Вы можете заменить окончание таблицы events_20240118 на events_202401*
|
1 2 3 4 5 |
SELECT COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_202401*` WHERE event_name = 'session_start' |
В данном примере такая запись означает, что запрос вернет количество событий session_start за весь январь 2024 года, поскольку вместо конкретного дня в формате events_ГГГГММДД используется подстановочный знак *, означающий любой день (=все дни) в наборе данных.
Мы можем записать запрос чуть иначе, используя специальную конструкцию _TABLE _ SUFFIX, которая содержит значение, соответствующее подстановочному знаку. Тогда наш SQL-запрос принимает такую форму:
|
1 2 3 4 5 6 |
SELECT COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_202401*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX = '18' |
Сама запись запроса в редакторе BigQuery будет выглядеть так:
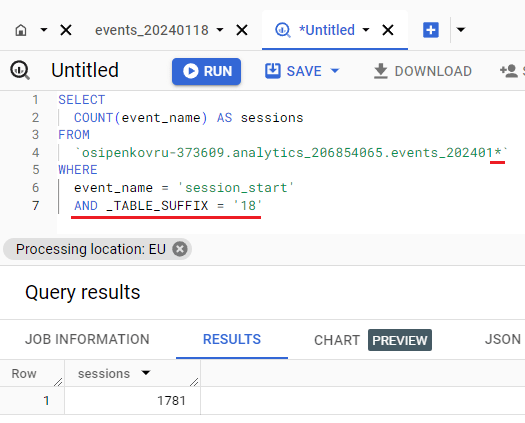
Результат запроса с подстановочным знаком
А результат выполнения запроса будет точно таким же, что и при обычном обращении к конкретной таблице.
Таким образом, используя подстановочный знак * в названии таблицы, изменяя в ней день, месяц или год, вы можете обращаться к нужному диапазону дат. Для этого вместе с подстановочным знаком и _TABLE _ SUFFIX используются операторы BETWEEN (между) и AND (и).
Например, SQL-запрос за 1 января по 15 января 2024 года:
|
1 2 3 4 5 6 7 8 |
SELECT COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' |
Особенность этого запроса именно в подстановочном знаке в конце названия таблицы events_*, который означает выбор всех таблиц, а далее с помощью _TABLE_SUFFIX в следующей строке SQL-запроса вы уже задаете статический интервал дат (от и до) в формате ГГГГММДД.
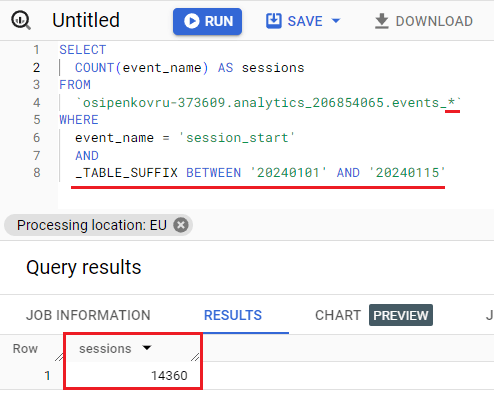
Запрос в Google BigQuery для статического диапазона дат
Если в Google Analytics 4 открыть отчет за аналогичный диапазон дат, то вы заметите, как данные в BigQuery и в интерфейсе отличаются, но незначительно:
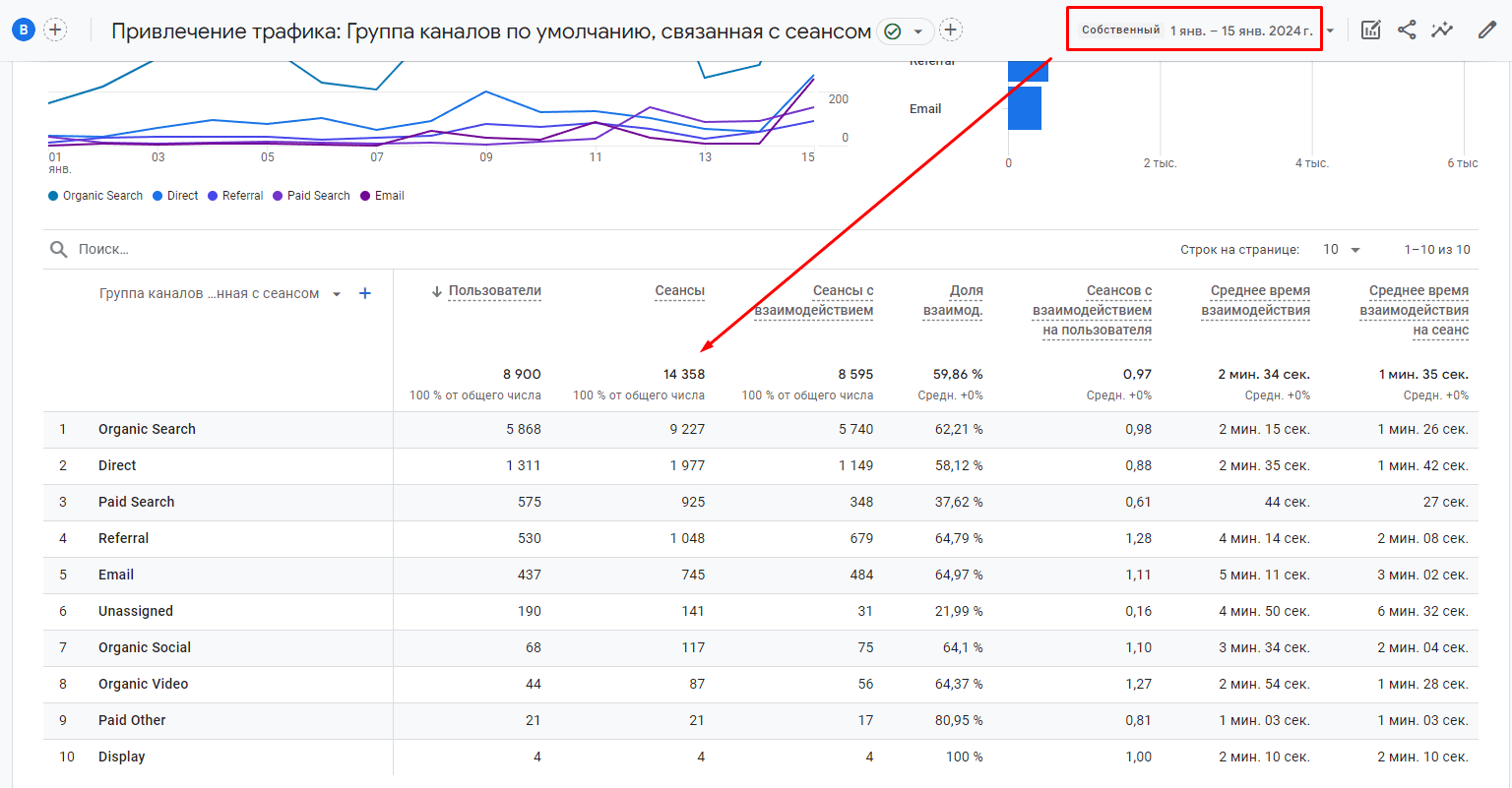
Сравнение интерфейсных значений сеансов с данными BigQuery
Запрос №3. Количество сеансов за динамический диапазон дат
В предыдущем запросе мы с вами использовали диапазон дат, но заданный статически, то есть неизменными датами (датой начала и датой окончания) с помощью конструкции _TABLE_SUFFIX, операторов BETWEEN, AND и подстановочного знака *.
Но что, если вы хотите изменить диапазон дат на динамический, то есть указать не конкретную дату (например, 20231123), а «за вчера»? Да, это можно сделать, используя функции даты и времени.
В Google BigQuery есть много различных функций, заранее предопределенных. Одна из таких – это функция CURRENT_DATE, которая возвращает текущую дату. Если ввести ее в редакторе запросов Google BigQuery, то в результатах вы увидите сегодняшнюю дату.
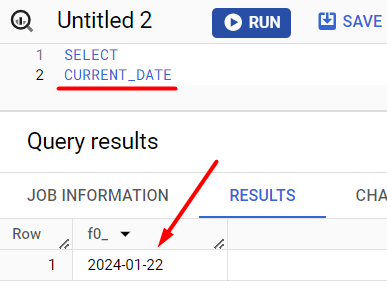
Функция CURRENT_DATE
Причем эта функция не расходует лимиты запросов, поскольку она является встроенной и ей не нужно сканировать данные в ваших таблицах Google Analytics 4.

Функция CURRENT_DATE не расходует лимиты запросов
Результат функции CURRENT_DATE возвращается в виде формата DATE, а не STRING, который используется в схеме данных Google Analytics 4 для поля event_date. Поэтому для того, чтобы использовать ее в динамическом диапазоне дат, ее сначала необходимо преобразовать в строку.
И поскольку мы хотим построить запрос, который извлекал бы для нас результат за вчерашний день, а не за сегодняшний как в CURRENT_DATE, нам необходимо использовать функцию DATE_SUB. Эта функция вычитает указанный интервал времени из DATE.
Таким образом, для вычитания одной даты из другой, вы можете функцию CURRENT_DATE заключить в другую функцию DATE_SUB, и задав еще один аргумент для разницы, посчитать итоговое значение.
Для извлечения вчерашней даты получается такая конструкция:
|
1 2 |
SELECT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY) |
, где:
- CURRENT_DATE – текущая дата в формате DATE;
- DATE_SUB – функция разницы дат;
- INTERVAL 1 DAY - интервал времени, равный одному дню.
Выполнив запрос, вы получите вчерашнюю дату. У меня это 2024-01-21 (21 января 2024 года) на момент написания этого материала:
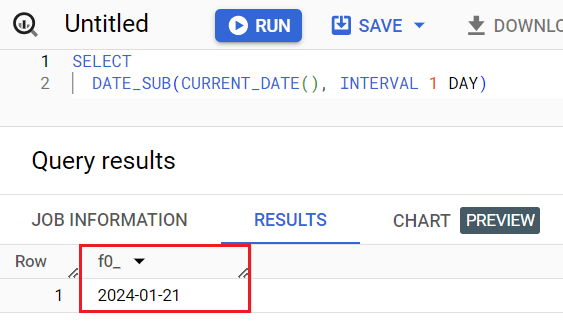
Вчерашняя дата
А поскольку формат возвращенного результата даты отличается от того, который мы задавали в предыдущем запросе, нам необходимо преобразовать тип данных DATE в формат STRING.
Делается это с помощью еще одной функции FORMAT_DATE. Она позволяет преобразовать дату в строку в нужном нам формате. Этот формат задается еще одним аргументом и имеет различные варианты написания. Для данных Google Analytics 4, как правило, используется шаблон %Y%m%d, где:
- %Y - обозначает год в виде четырехзначного числа;
- %m – обозначает месяц в виде двухзначного числа;
- %d – обозначает день в виде в виде двухзначного числа.
Используя такую конструкцию в SQL-запросе:
|
1 2 |
SELECT FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) |
Вы получите вчерашнюю дату в нужном формате:
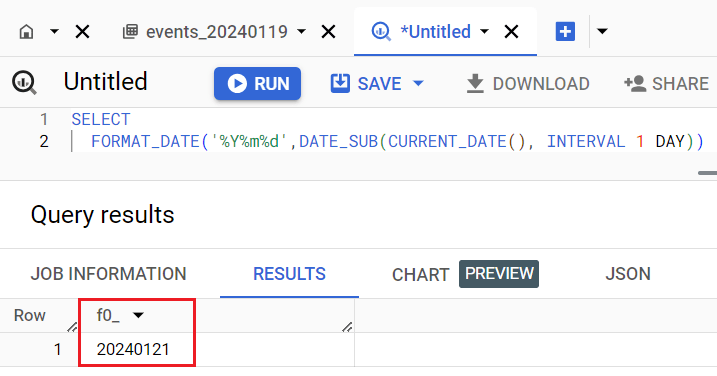
Вчерашняя дата в строковом типе данных (STRING)
Именно эту строку вы можете скопировать и вставить в свой третий запрос для подсчета количества сеансов с динамическим диапазоном дат для даты окончания:
|
1 2 3 4 5 6 7 |
SELECT COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN '20240101' AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) |
После выполнения этого запроса BigQuery отобразит вам результат с данными, запрошенный с 1 января 2024 года и заканчивая вчерашним днем на момент написания этого материала, то есть 21 января 2024 года:
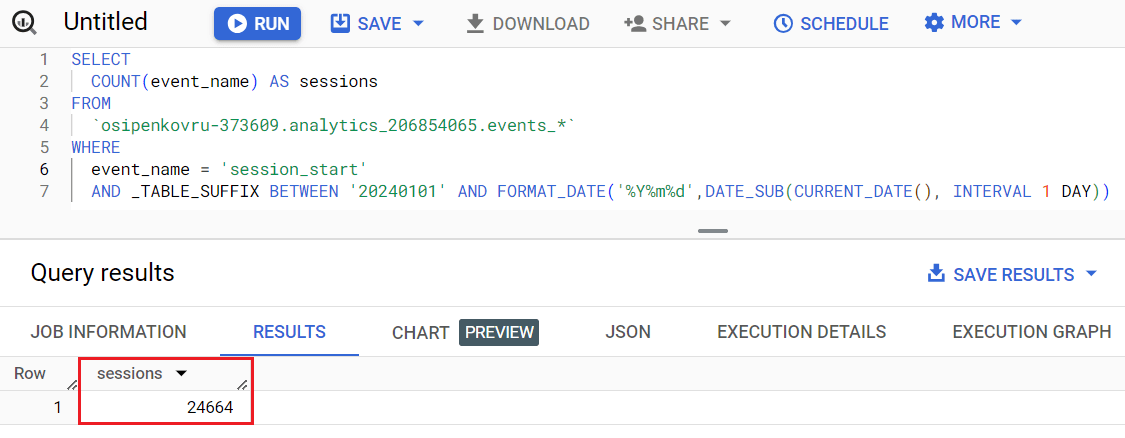
Запрос в Google BigQuery для динамического диапазона дат
Если вы хотите выполнить запрос, который будет извлекать данные за последние 30 дней, то вы можете скопировать вышеприведенную строку и для даты начала, заменив дату начала, идущую после BETWEEN, на INTERVAL 30 DAY:
|
1 2 3 4 5 6 7 8 |
SELECT COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) |
Запрос №4. Количество сеансов с разбивкой по дате
А что, если вы хотите увидеть не общее количество сеансов за выбранный диапазон дат, а еще и с разбивкой по дате? Сделать это очень легко! Нужно просто в операторе SELECT добавить дополнительное поле event_date, а в конце сделать группировку по дате события с использованием оператора GROUP BY:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT event_date, COUNT(event_name) AS sessions, FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY event_date |
Результат запроса будет выглядеть примерно так:
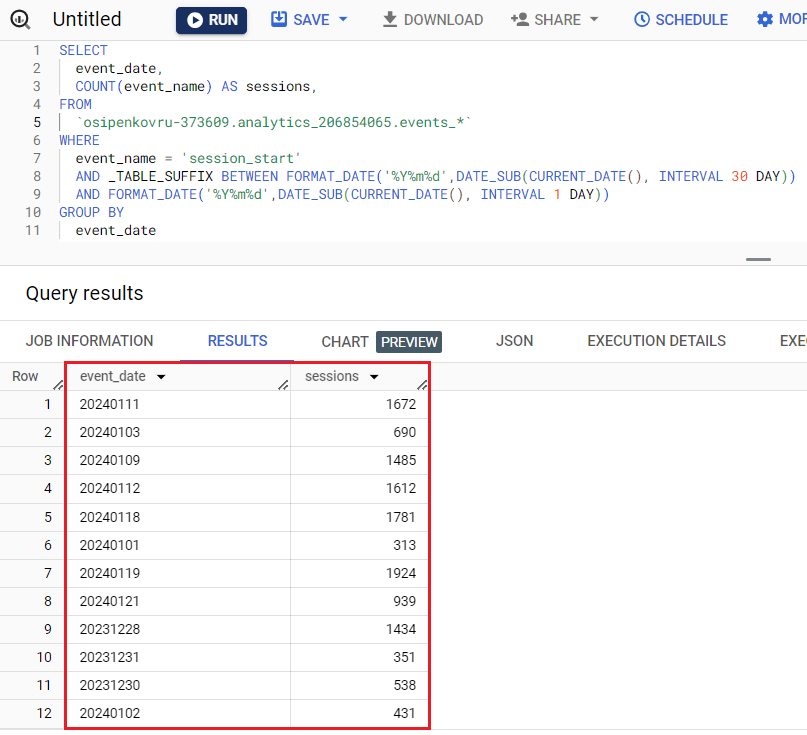
Результат SQL-запроса с разбивкой по дате
Данные, извлеченные с помощью данного SQL-запроса, могут идти не по порядку. Такой результат не очень удобно анализировать. Вы можете отсортировать полученный результат по дате события или по количеству сеансов с помощью оператора ORDER BY с указанием сортировки – по убыванию (DESC) или по возрастанию (ASC).
Если не указать способ сортировки, то по умолчанию BigQuery будет сортировать по возрастанию (от низких значений к высоким, ASC). В случае строковых значений они будут упорядочены от А/A до Я/Z. При работе с типами данных даты с указанием сортировки ASC самая ранняя дата отображается вверху списка, а при добавлении DESC самая поздняя дата отображается вверху списка.
Например, указав ORDER BY по event_date без использования порядки сортировки:
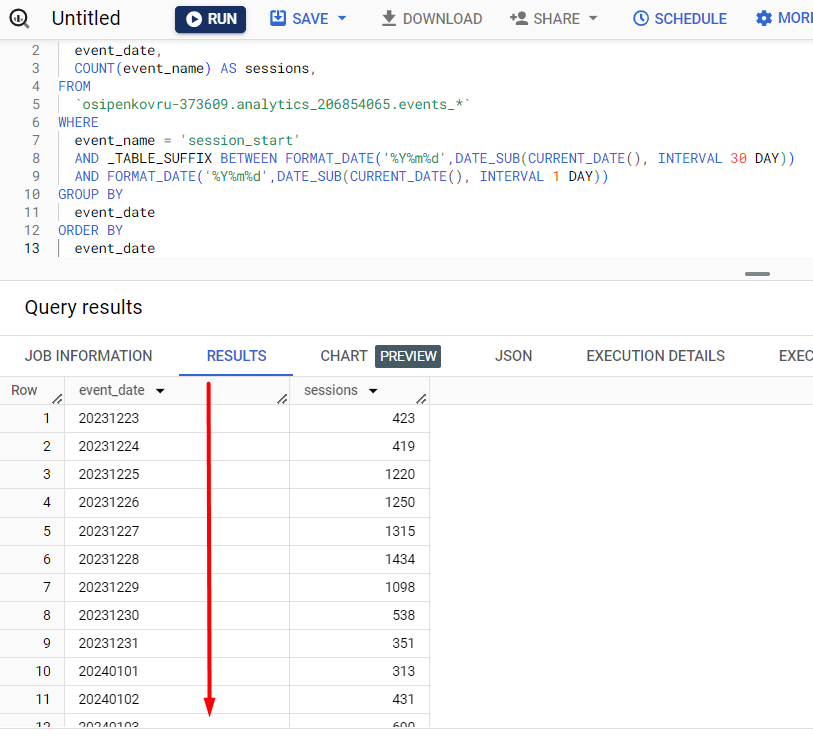
Сортировка по полю event_date
Переключившись на вкладку CHART, вы увидите визуализацию ваших данных:
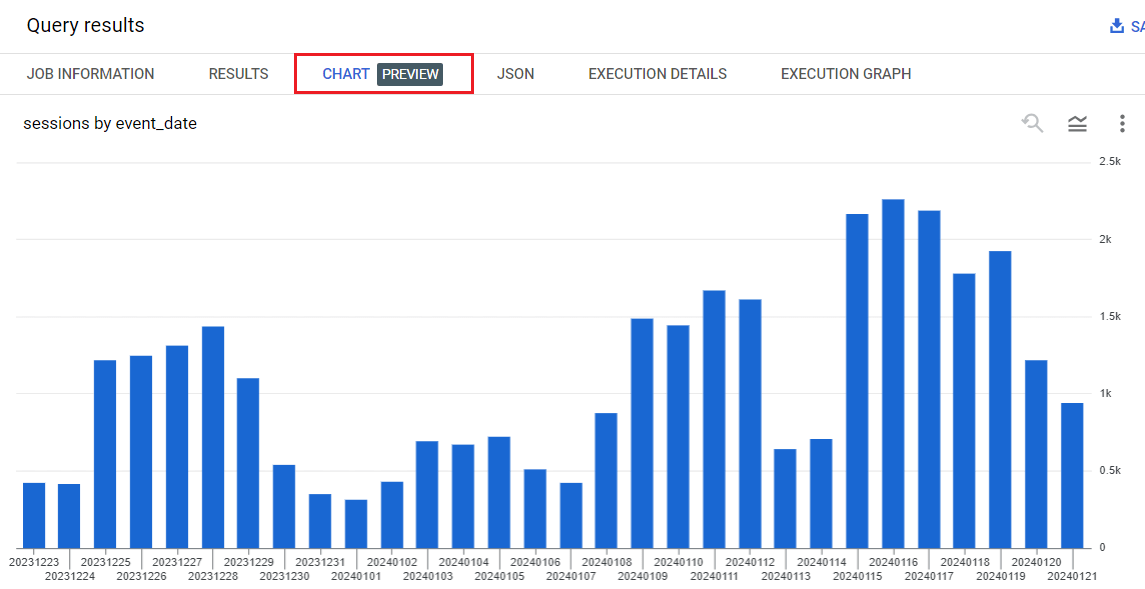
Визуализация результата запроса в BigQuery
А если указать ORDER BY по event_date с DESC, то результат запроса будет представлен с порядком сортировки по убыванию, от 20240124 до 20231223. Изменение сортировки по псевдониму sessions для нашего запроса то же возможно (DESC – по убыванию):
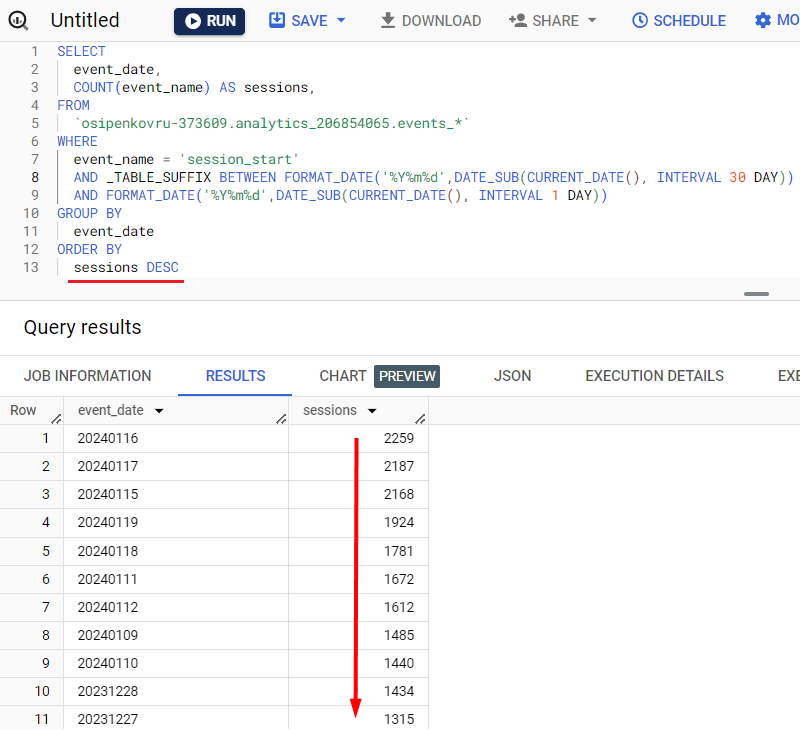
Сортировка по сеансам
Запрос №5. Подсчет количества сеансов по дням недели
Даты – это здорово. Но что, если вы хотите произвести расчет количества сеансов не за выбранный диапазон дат, даже если он является статическим или динамическим, а по дням недели – понедельник, вторник, среда и т.д.?
Что ж, это тоже можно сделать. Но для начала нам необходимо поле event_date, которое в схеме данных является строкой (STRING), преобразовать в тип данных DATE. Для этого в запросе на уровне SELECT вы можете задать два раза поле event_date, только в одном случае оставить его без изменений и добавить псевдоним (например, date), а в другом использовать функцию PARSE_DATE, которая преобразует отформатированную строку YYYYMMDD значения в объект DATE.
В качестве аргумента функции необходимо указать желаемый формат. В нашем примере – это тот же шаблон %Y%m%d. SQL-запрос будет выглядеть так:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT event_date AS date, PARSE_DATE ('%Y%m%d', event_date), COUNT(event_name) AS sessions, FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY event_date |
Результат в Google BigQuery:
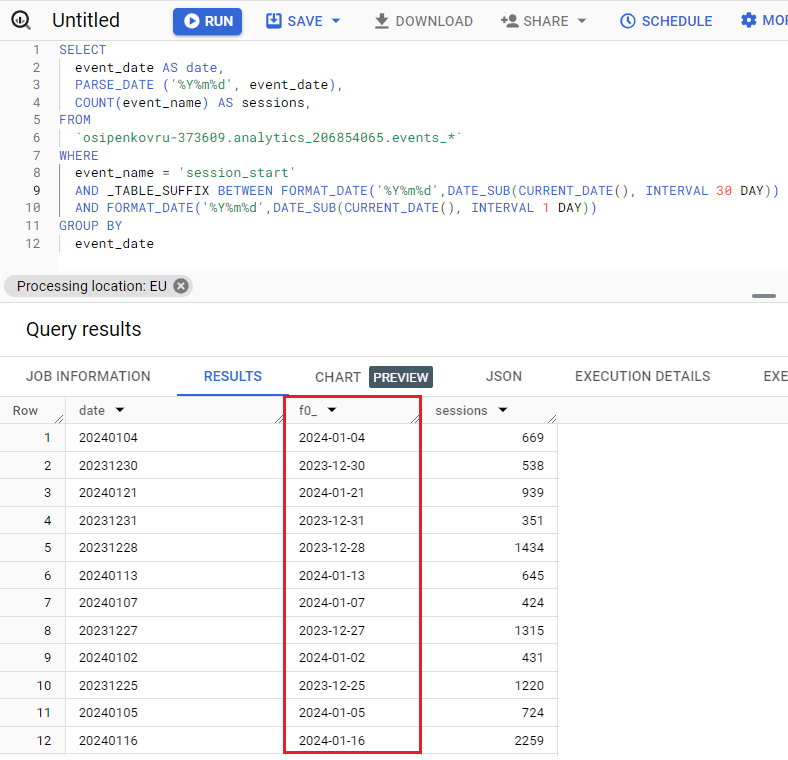
Отдельный столбец с преобразованной датой с помощью функции PARSE_DATE
Как видите, функция PARSE_DATE преобразовала строковые значения поля event_date в формат даты нужного нам вида ГГГГ-ММ-ДД.
Теперь мы можем запросить нужные нам данные. В качестве примера выполним запрос, извлекающий из даты день недели. Для этого используется функция EXTRACT. Она возвращает часть даты или времени из строки. Причем в том виде, в котором вы хотите вернуть эту часть даты или времени, необходимо задать. Есть различные варианты:
- DAYOFWEEK - возвращает значения в диапазоне [1,7], где воскресенье является первым днем недели;
- DAY – возвращает день;
- DAYOFYEAR – возвращает день в году;
- WEEK - возвращает номер недели даты в диапазоне [0, 53]. Недели начинаются с воскресенья, а даты, предшествующие первому воскресенью года, относятся к неделе 0;
- MONTH – возвращает месяц года;
- QUARTER - возвращает значения в диапазоне [1,4];
- YEAR – возвращает год;
- и другие.
В качестве примера давайте вернем результат в формате дня недели (DAYOFWEEK). Для этого добавьте функцию EXTRACT для поля с преобразованным в формат даты значением, а также в качестве аргумента укажите DAYOFWEEK:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT event_date AS date, EXTRACT (DAYOFWEEK FROM PARSE_DATE ('%Y%m%d', event_date)), COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY date ORDER BY date |
Результат запроса – отдельный столбец с днем недели, где 1 – воскресенье, а 7 – суббота:
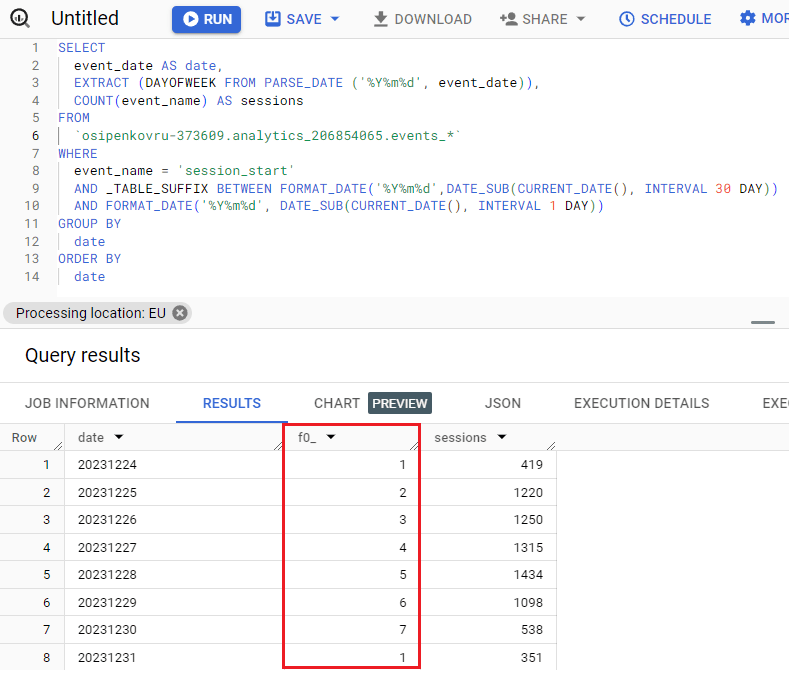
Результат запроса – отдельный столбец с днем недели
Получается, что день недели с 2 до 6 – это будни, а 1 и 7 – это выходные. Можно ли в BigQuery построить запрос, который отдавал бы результат в таком срезе? Выходные/Будни?
Да, это возможно сделать с помощью оператора CASEWHEN. Создав нижеприведенную цепочку из нескольких условий, вы сможете получить заветный результат:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT event_date AS date, CASE WHEN EXTRACT (DAYOFWEEK FROM PARSE_DATE ('%Y%m%d', event_date)) IN (1, 7) THEN 'Выходные' ELSE 'Будни' END AS day_of_week, COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY date ORDER BY date |
В данном примере функция EXTRACT осталась прежней, только перед ней мы добавили еще одну функцию CASE WHEN, которая позволяет возвращать разное значение в зависимости от заданного вами условия. Она может использоваться для преобразования данных, вычисления метрик или создания сложных запросов.
В этом запросе используется функция IN с диапазоном (1,7), которая проверяет, входит ли значение в набор значений. И наша задача проверить день недели только на эти два значения. Если день недели 1 или 7, то результатом должно быть Выходные, в противном случае день неделя является Будни.
Результат выполнения SQL-запроса:
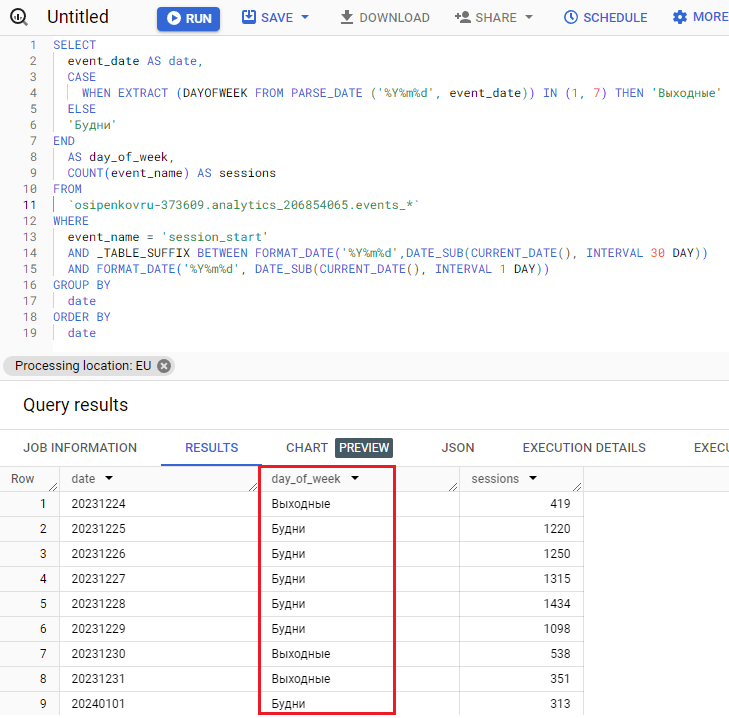
Результат запроса с подсчетом количества сеансов по дням недели
Запрос №6. Подсчет количества сеансов по части дня
Давайте спустимся еще на один уровень ниже и попробуем рассчитать количество сеансов за выбранные дни и в разрезе его части. Например, разбить день на утро, день, вечер и ночь.
Здесь мы предполагаем, что каждый день можно разделить на четыре равные части, каждая из которых состоит из 6 часов:
- утро (от восхода, примерно с 6 до 12 часов);
- день (с 13 до 18 часов);
- вечер (с 19 до 23 часов);
- ночь (с 00 часов до 5 утра).
К сожалению, поле event_date мы использовать не можем, потому что в этом столбце нет конкретных данных по нужным нам срезам. А вот другой столбец event_timestamp с типом данных INTEGER вполне подойдет для этой задачи.
Добавив его в свой SQL-запрос, мы увидим его в результатах:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT event_date AS date, event_timestamp, CASE WHEN EXTRACT (DAYOFWEEK FROM PARSE_DATE ('%Y%m%d', event_date)) IN (1, 7) THEN 'Выходные' ELSE 'Будни' END AS day_of_week, COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY date, event_timestamp ORDER BY date |
Вот так это будет выглядеть:
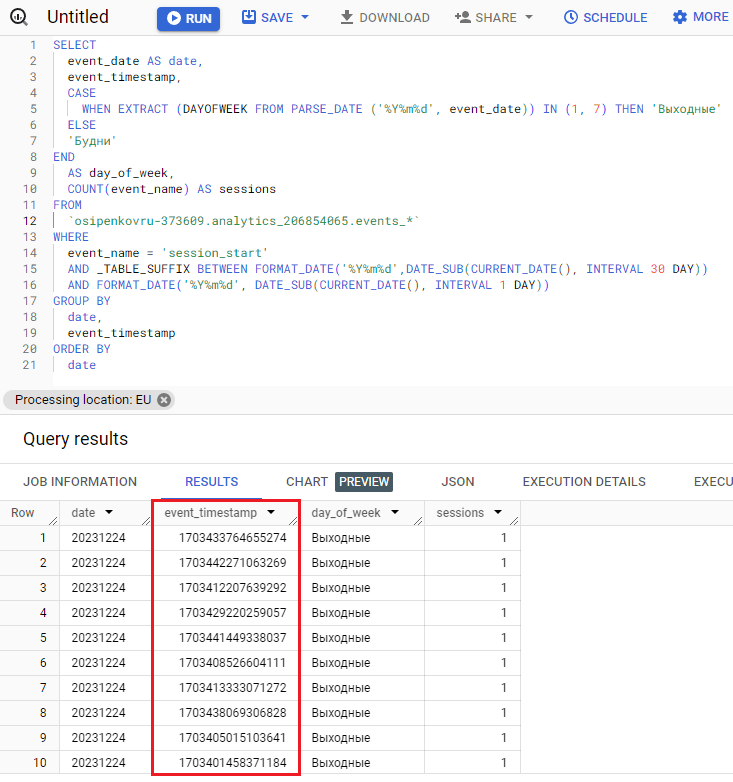
Столбец event_timestamp
Как видите, напротив каждой временной метки отображается только один сеанс, поскольку event_timestamp очень сильно детализирует статистику. event_timestamp – это время, когда было зарегистрировано событие. Оно измеряется в микросекундах. Таким образом, вероятность того, что два посетителя окажутся на вашем сайте в одно и то же время при такой детализации крайне мала (но она есть).
А с помощью функции TIMESTAMP_MICROS мы можем преобразовать временную метку event_timestamp. Она преобразует количество микросекунд с 1 января 1970 г. 00:00:00 в формате UTC и возвращает метку времени.
Добавив ее в запрос:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT event_date AS date, TIMESTAMP_MICROS(event_timestamp), CASE WHEN EXTRACT (DAYOFWEEK FROM PARSE_DATE ('%Y%m%d', event_date)) IN (1, 7) THEN 'Выходные' ELSE 'Будни' END AS day_of_week, COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY date, event_timestamp ORDER BY date |
Результат отображения уже будет другим:
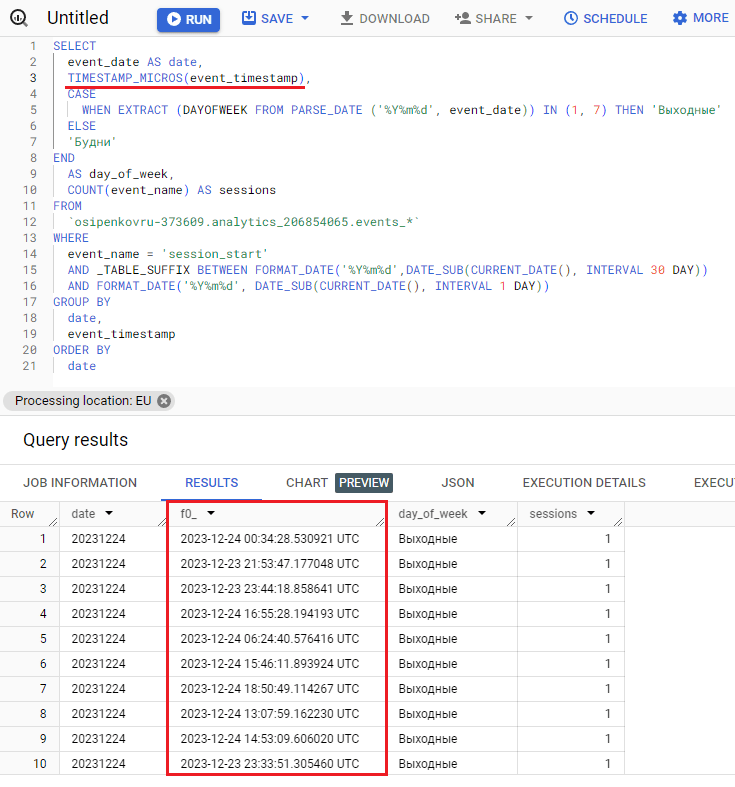
Преобразование event_timestamp с помощью функции TIMESTAMP_MICROS
Как видите, в таком формате уже присутствует понятная дата и время совершения события. Теперь с помощью все той же функции EXTRACT мы можем извлечь не день недели, а час.
Тогда вышеприведенный запрос будет преобразован в этот:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT event_date AS date, EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)), CASE WHEN EXTRACT (DAYOFWEEK FROM PARSE_DATE ('%Y%m%d', event_date)) IN (1, 7) THEN 'Выходные' ELSE 'Будни' END AS day_of_week, COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY date, event_timestamp ORDER BY date |
И результат в BigQuery:
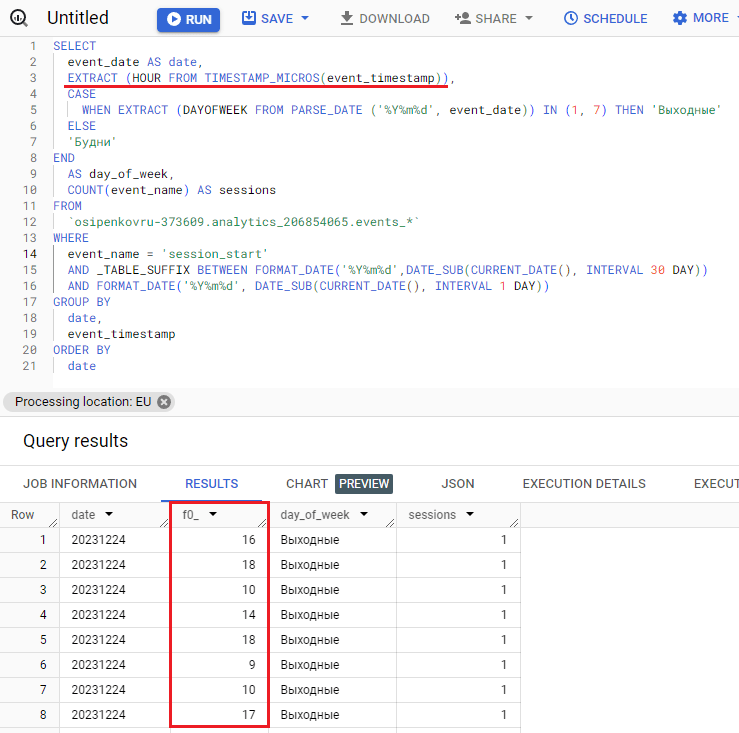
Извлечение значения часа из временной метки
Теперь это значение мы можем использовать в функции CASE WHEN, изначально зная интервалы дня: утро (с 6 часов до 12 часов), день (с 13 до 18 часов), вечер (с 19 до 23 часов) и ночь (с 00 часов до 5 утра).
Ваш SQL-запрос будет выглядеть так:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT event_date AS date, EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)), CASE WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 0 AND 5 THEN 'Ночь' WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 6 AND 12 THEN 'Утро' WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 13 AND 18 THEN 'День' WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 19 AND 23 THEN 'Вечер' END AS part_of_day, CASE WHEN EXTRACT (DAYOFWEEK FROM PARSE_DATE ('%Y%m%d', event_date)) IN (1, 7) THEN 'Выходные' ELSE 'Будни' END AS day_of_week, COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY date, event_timestamp ORDER BY date |
А его результат:
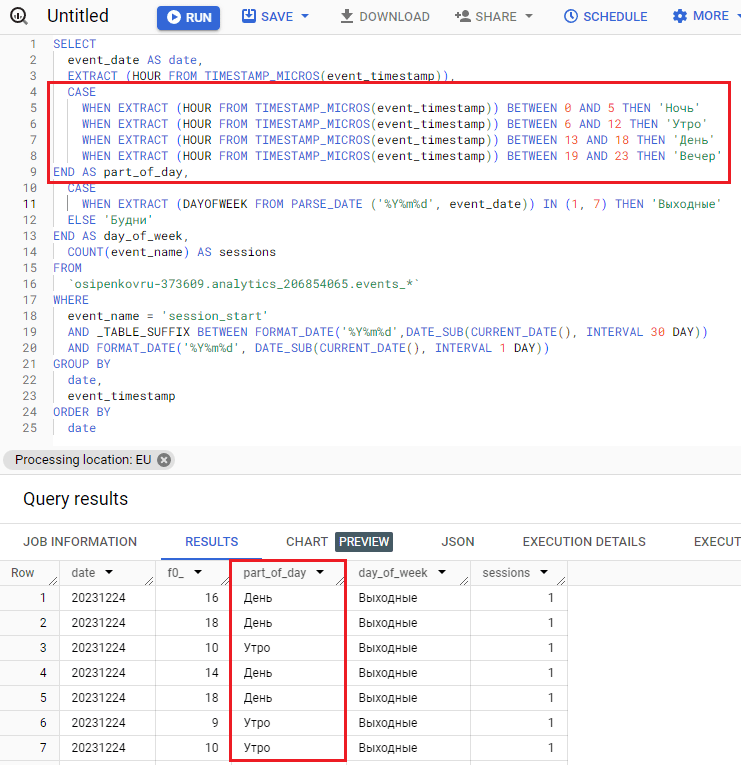
Результат SQL-запроса со столбцом по интервалам дня
Как видите, в нашей таблице есть столбец f0_ с часом дня, а есть новый столбец с частью дня – утро, день, вечер и ночь. Вы можете проверить корректность составления запроса, поочередно сопоставляя часть и итоговое переопределение с помощью функции CASE WHEN. Данные должны отображаться правильно.
Однако в таком результате есть существенный недостаток – большая таблица, где в каждой строке отображается лишь всего один сеанс, а сама таблица имеет очень много записей:
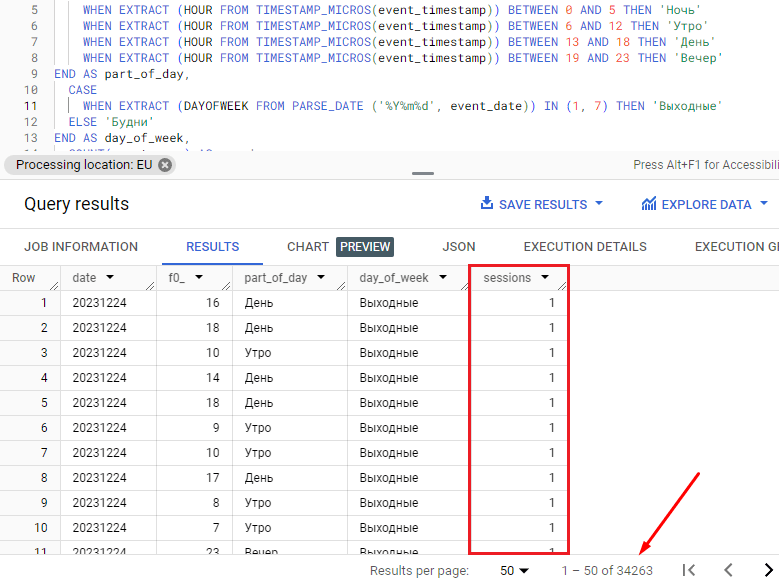
Один сеанс - на одной строке
Чтобы привести ее в формат, возможный для анализа, необходимо данные сгруппировать иным способом. Для этого используйте группировку по полям day_of_week и part_of_day, а сортировку по sessions в порядке убывания (DESC). Тогда самая популярная часть дня и часть недели будут наверху таблицы результатов, а наименее посещаемые части дня и части недели будут внизу таблицы.
SQL-запрос:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT CASE WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 0 AND 5 THEN 'Ночь' WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 6 AND 12 THEN 'Утро' WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 13 AND 18 THEN 'День' WHEN EXTRACT (HOUR FROM TIMESTAMP_MICROS(event_timestamp)) BETWEEN 19 AND 23 THEN 'Вечер' END AS part_of_day, CASE WHEN EXTRACT (DAYOFWEEK FROM PARSE_DATE ('%Y%m%d', event_date)) IN (1, 7) THEN 'Выходные' ELSE 'Будни' END AS day_of_week, COUNT(event_name) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE event_name = 'session_start' AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d',DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)) AND FORMAT_DATE('%Y%m%d', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)) GROUP BY part_of_day, day_of_week ORDER BY sessions DESC |
И результат запроса:
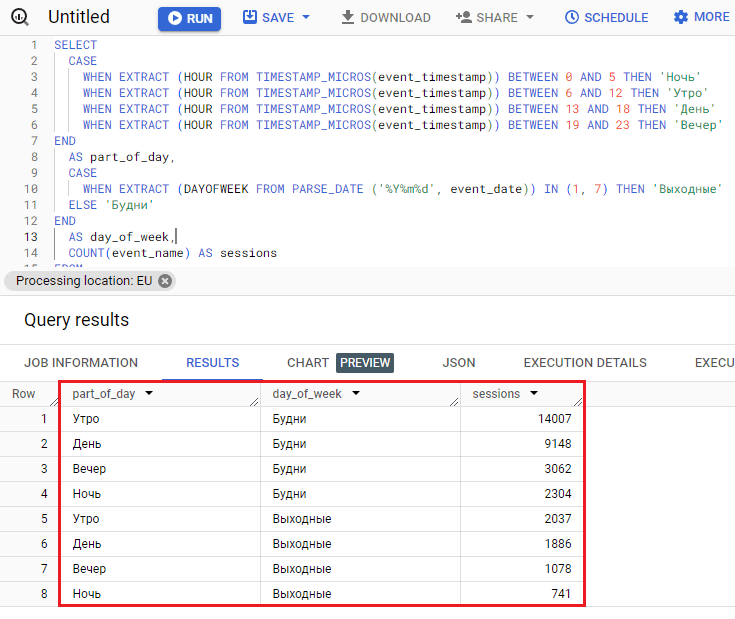
Результат группировки
Исходя из полученных данных, наиболее посещаемым временем моего сайта за выбранный диапазон дат является утреннее время (с 6 до 12 часов) в будни. Наименее посещаемое – ночь (с 0 до 5 утра) в выходные.
Запрос №7. Расчет количества сеансов на основе параметра события ga_session_id
Каждому сеансу в Google Analytics 4 присваивается уникальный идентификатор сеанса (ga_session_id) - это временная метка начала сеанса. Таким образом, теоретически можно иметь несколько сеансов от разных пользователей с одинаковым идентификатором сеанса, потому что с точки зрения GA они могут начинаться в одно и то же время. Номер сеанса определяет количество сеансов, которые пользователь провел до текущего сеанса (например, третий или пятый сеанс пользователя на вашем сайте).
В схеме данных GA4 параметр события ga_session_id является повторяющимся и вложенным полем:
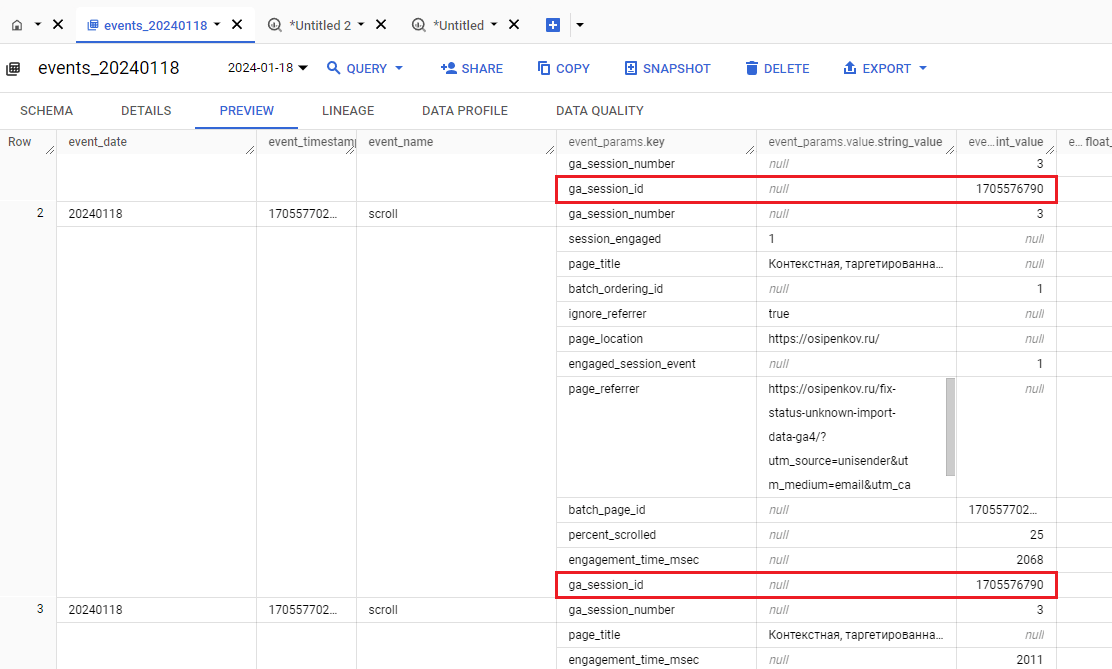
Повторяющийся и вложенный параметр события ga_session_id в BigQuery
Поэтому для его извлечения необходимо использовать более сложную конструкцию с использованием функции UNNEST:
|
1 2 3 4 5 6 |
SELECT (SELECT value.int_value FROM UNNEST (event_params) WHERE KEY = 'ga_session_id') FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' |
Вот так выглядит результат после выполнения запроса:
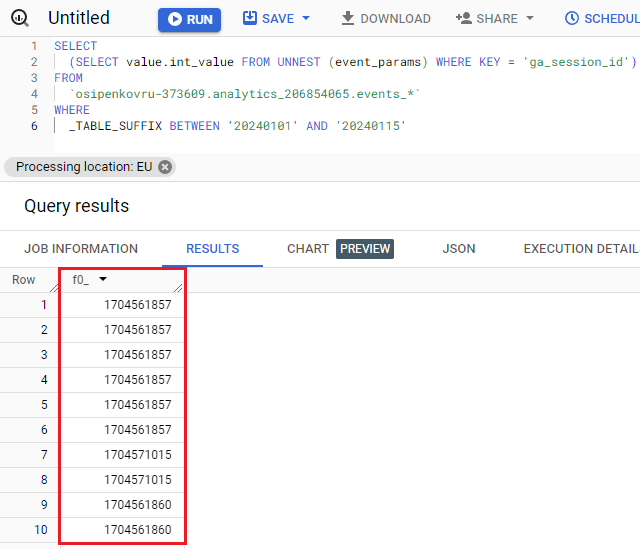
Результат в BigQuery по извлечению идентификаторов сеансов
BigQuery возвращает идентификатор сеанса для каждого события, то есть каждая строка – это событие. Именно поэтому на некоторых строчках присутствуют одни и те же значения ga_session_id.
Подсчет количества уникальных идентификаторов сеанса даст нам количество сеансов, так как ga_session_id привязывается именно к сессии. Чтобы их подсчитать, используйте уже известную функцию COUNT (DISTINCT):
|
1 2 3 4 5 6 |
SELECT COUNT (DISTINCT(SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id')) AS ga_session_id FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' |
Это даст нам количество уникальных идентификаторов сеансов за выбранный диапазон дат:
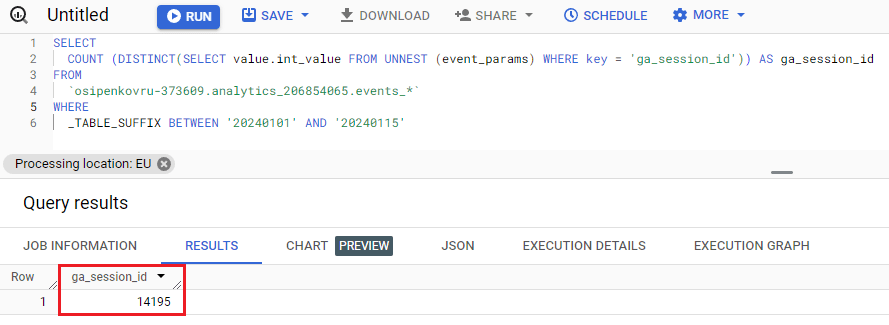
Количество уникальных идентификаторов сеансов за выбранный диапазон дат
Запрос №8. Расчет количества сеансов на основе ga_session_id и user_pseudo_id
Вышеприведенный SQL-запрос позволяет нам ответить на вопрос «Сколько было сеансов с 1 января по 15 января 2024 года»? Нет, потому что идентификатор сеанса ga_session_id может быть одинаковым для двух разных пользователей. А такое возможно? Да, так как несколько пользователей могут зайти на ваш веб-сайт в одно и то же время. В результате у них будет одинаковый идентификатор сеанса ga_session_id, но разные значения user_pseudo_id.
Чтобы избежать таких сценариев, нам необходимо использовать функцию CONCAT, объединяющую несколько строк. Она принимает в качестве аргументов одну или несколько строк и возвращает одну строку, содержащую все исходные строки, соединенные вместе. Таким образом, наш SQL-запрос преобразится и станет выглядеть так:
|
1 2 3 4 5 6 |
SELECT COUNT (DISTINCT CONCAT(user_pseudo_id, (SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id'))) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' |
Результат в Google BigQuery:
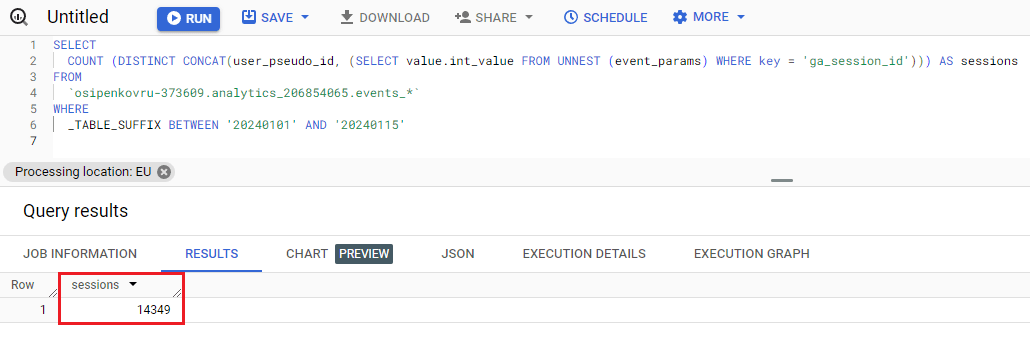
Расчет количества сеансов на основе ga_session_id и user_pseudo_id
Вы также можете сравнить полученные значения в BigQuery с интерфейсной статистикой Google Analytics 4:
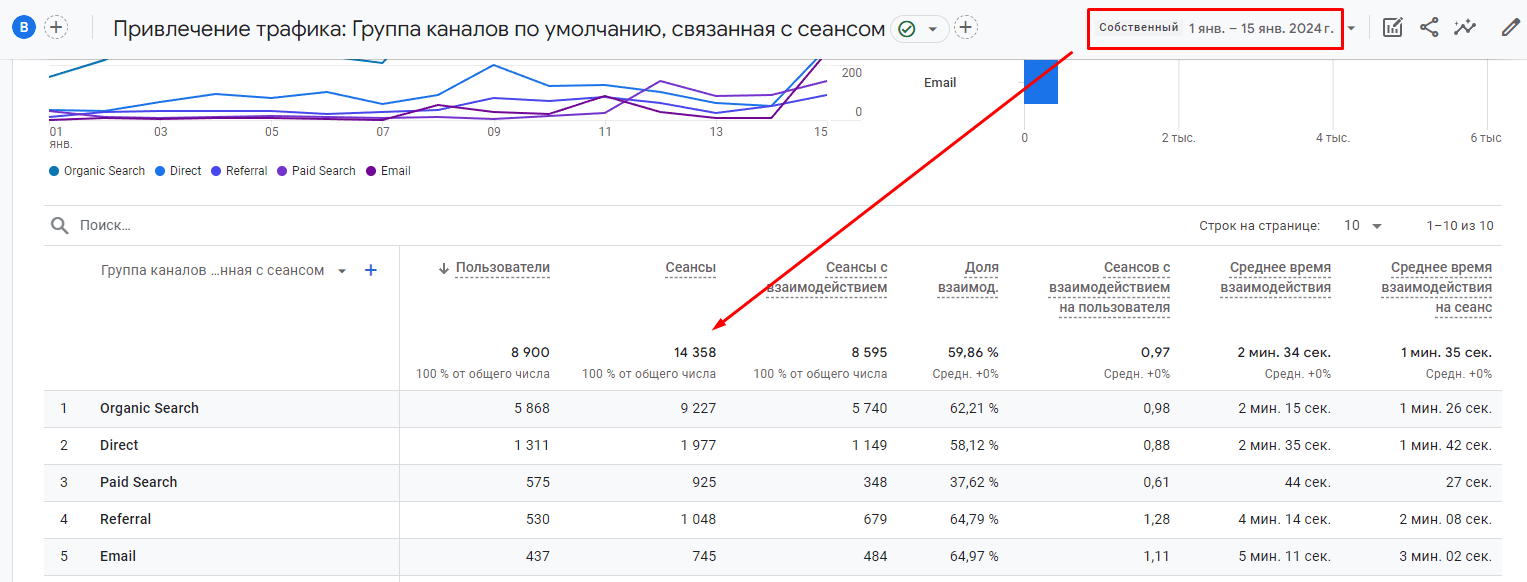
Сравнение интерфейсной статистики Google Analytics 4 с данными в Google BigQuery
Как видите, значения практически сошлись (14349 в BigQuery vs 14358 в GA4).
Запрос №9. Запрос с двумя комбинациями: по ga_session_id, ga_session_id и user_pseudo_id
Объединив запросы №7 и №8, вы можете получить новый запрос, в котором будет наглядно видно различие между двумя способами расчета сеансов:
- только по уникальным идентификаторам сеанса ga_session_id за выбранный диапазон дат;
- по уникальным идентификаторам сеанса ga_session_id и уникальным идентификаторам пользователей user_pseudo_id за выбранный диапазон дат.
Пример такого SQL:
|
1 2 3 4 5 6 7 |
SELECT COUNT (DISTINCT(SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id')) AS only_ga_session_id, COUNT (DISTINCT CONCAT(user_pseudo_id, (SELECT value.int_value FROM UNNEST (event_params) WHERE key = 'ga_session_id'))) AS ga_session_id_and_users FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' |
Здесь мы добавили псевдонимы для двух полей, где only_ga_session_id – подсчет уникального количества значений по полю ga_session_id, а ga_session_id_and_users – подзапрос, в котором используется функция объединения строк CONCAT, где в качестве одного аргумента принимается поле user_pseudo_id, а в качестве другого – все тот же подзапрос с подсчетом уникального количества значений по полю ga_session_id.
Результатом выполнения этого SQL-запроса будет такая таблица:
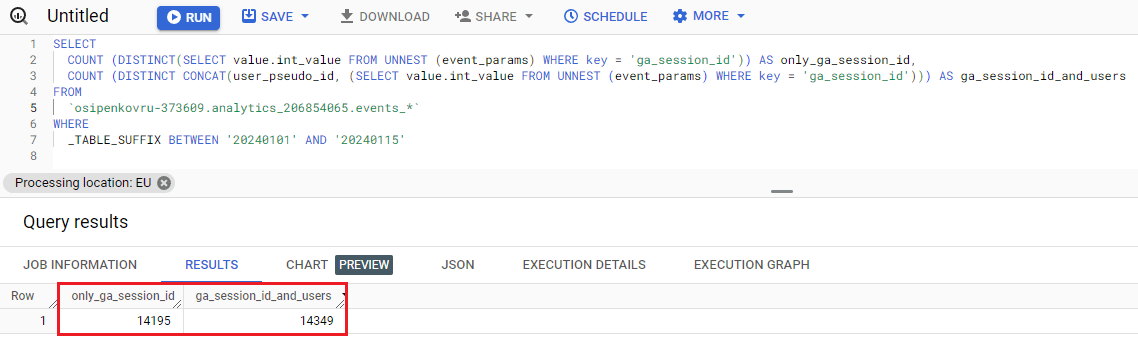
Объединение двух методов подсчета в одном SQL-запросе
- Подсчет уникального количества значений по полю ga_session_id – 14195;
- Подсчет уникального количества значений по полю ga_session_id и по user_pseudo_id – 14349.
Полученные цифры свидетельствуют о том, что при подсчете уникального количества значений по полю ga_session_id получилось меньше уникальных записей, чем при подсчете комбинации ga_session_id и user_pseudo_id. А это подтверждает наше предположение о том, что несколько пользователей могут зайти на веб-сайт в одно и то же время. В результате у них будет одинаковый идентификатор сеанса ga_session_id, но разные значения user_pseudo_id.
Запрос №10. Расчет количества сеансов с учетом ga_session_id, user_pseudo_id и session_start
Однако расчет количества сеансов с использованием уникального идентификатора сеанса не будет точно соответствовать данным в интерфейсе GA4. Это связано с тем, что Google Analytics 4 для расчета сеанса использует событие session_start.
И еще в GA4 есть свои особенности, которые сложно/невозможно объяснить. Во-первых, он может фактически записывать более одного события session_start для одного события. Это случается не очень часто, но может вызвать некоторые различия при детальном анализе, основанном на предположении, что в сеансе всегда есть одно событие session_start. Во-вторых, один и тот же идентификатор сеанса может быть назначен двум сеансам разных пользователей. Ну и, конечно же, в-третьих - это то, что сеансы могут вообще быть без события session_start.
Как это возможно? Все дело в том, что в Google Analytics 4 сеансы могут длиться несколько дней и при этом считаться одним и тем же сеансом, они не будут перезапускаться в полночь, как это было в Universal Analytics. Поэтому у вас может возникнуть такая ситуация, когда событие session_start должно произойти в пятницу вечером, но некоторые просмотры страниц и события user_engagement происходят рано утром в субботу. Если вы создаете отчет только по субботе, вы увидите взаимодействия пользователей в сеансе, в котором нет события session_start.
Поэтому я хотел бы поделиться с вами еще одним интересным решением, которое я нашел в этой статье.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT CONCAT(user_pseudo_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE KEY = 'ga_session_id' ) ) AS unique_session_id, SUM(IF(event_name = 'session_start', 1, 0)) AS session_start_events FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' GROUP BY unique_session_id ORDER BY session_start_events DESC |
Вышеприведенный SQL-запрос используется для расчета количества сеансов на основе события session_start для каждого уникального пользователя и его идентификатора сеанса. Это делается путем объединения user_pseudo_id и ga_session_id с помощью функции CONCAT для создания комбинации уникального идентификатора сеанса и уникального идентификатора пользователя. Затем он суммирует количество событий, где event_name равно session_start, а затем упорядочивает результаты по количеству событий начала сеанса в порядке убывания.
Результат выполнения команды в BigQuery:
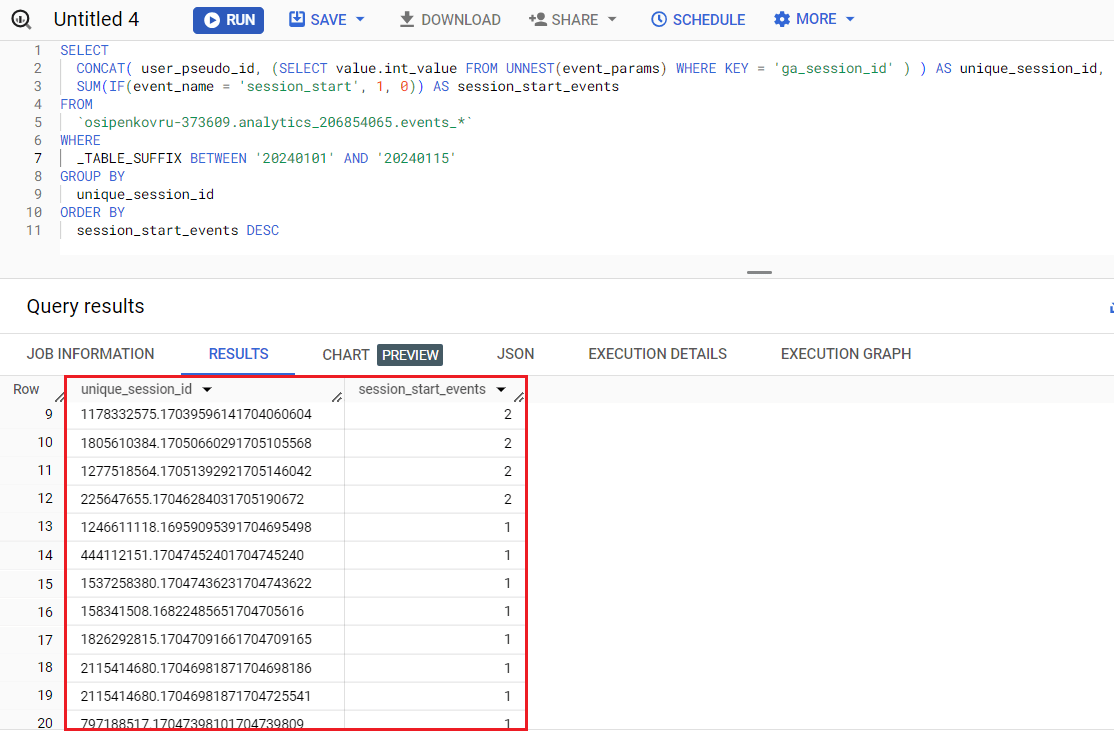
Расчет количества сеансов с учетом ga_session_id, user_pseudo_id и session_start
Если выгрузить эти данные в Microsoft Excel/Google Таблицы или тот же Looker Studio и просуммировать все значения по полю session_start_events, то они будут несколько отличаться от всех вышеприведенных запросов.
Запрос №11. Расчет количества сеансов с учетом user_pseudo_id, event_timestamp и session_start
Альтернативный вариант - SQL-запрос с объединением полей user_pseudo_id и event_timestamp и использованием все того же события session_start:
|
1 2 3 4 5 6 |
SELECT COUNT(DISTINCT CASE WHEN event_name = "session_start" THEN CONCAT(user_pseudo_id,event_timestamp) END) AS sessions FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' |
Результат в BigQuery:
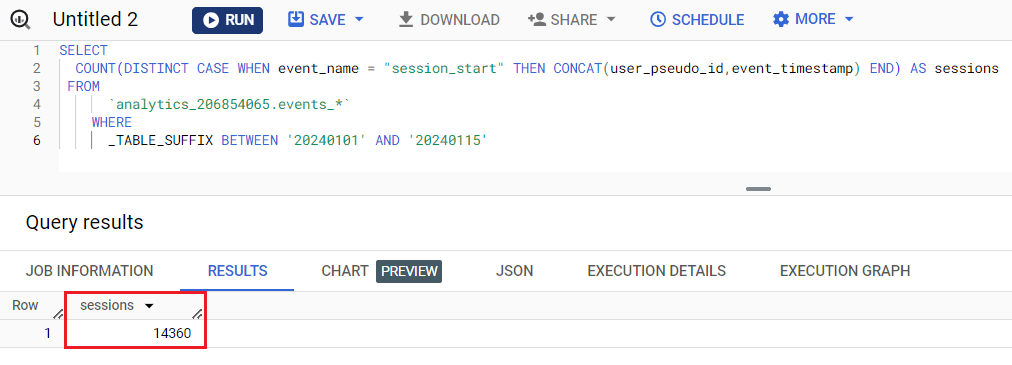
Расчет количества сеансов с учетом user_pseudo_id, event_timestamp и session_start
Запрос №12. Определение сеанса с взаимодействием с помощью session_engaged
Помимо сеансов, немаловажной метрикой в Google Analytics 4 являются Сеансы с взаимодействием (Engaged sessions). Чтобы сеанс считался как сеанс с взаимодействием, пользователь должен выполнить хотя бы одно из следующих действий:
- активно взаимодействовать с вашим сайтом или приложением не менее 10 секунд (такая настройка задана по умолчанию);
- выполнить событие-конверсию;
- просмотреть 2 или более страниц.
Таким образом, если сеанс длится дольше определенного времени, он становится сеансом с взаимодействием.
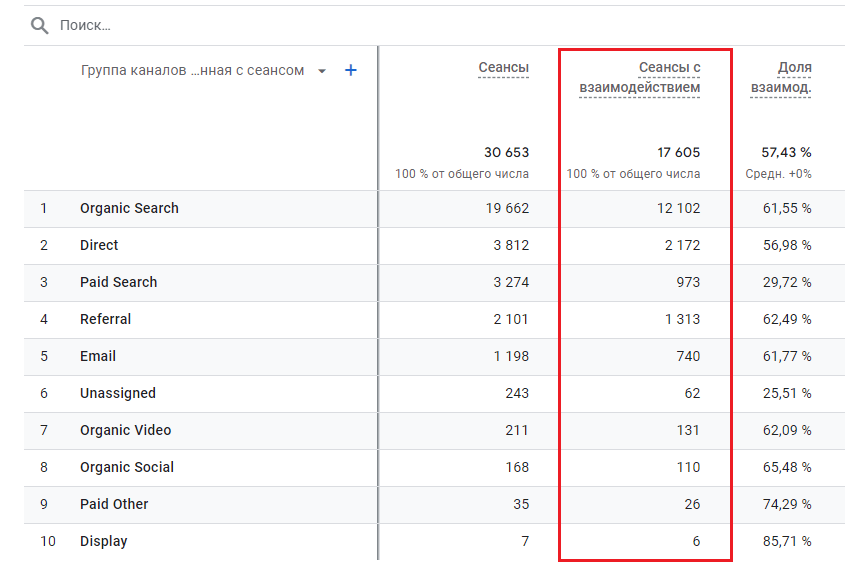
Сеансы с взаимодействием
Условие взаимодействовать не менее 10 секунд вы можете переопределить в интерфейсе Google Analytics 4, настроив время ожидания сеанса. Подробнее об этом читайте в этой статье.
Таймер для сеансов с взаимодействием
И чтобы соответствовать этому определению, вы можете использовать параметр события session_engaged в Google BigQuery. Например, его можно найти в событии user_engagement или в first_visit:
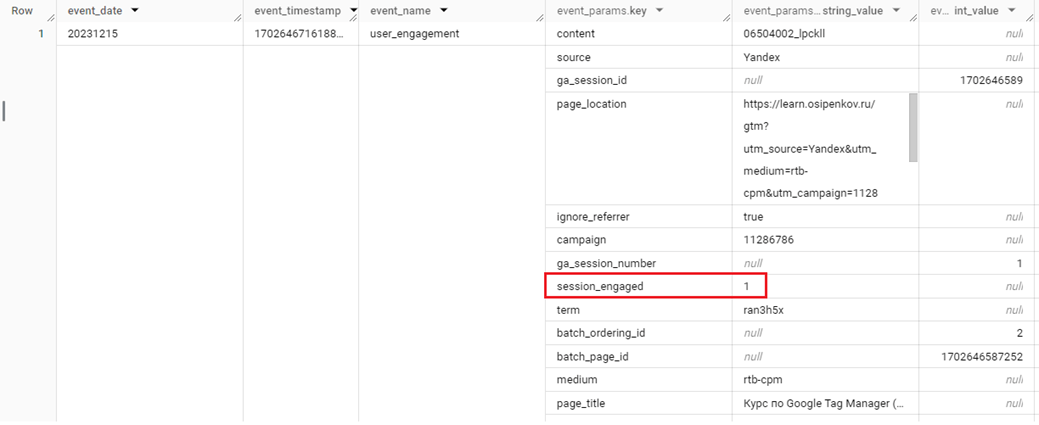
Параметр события session_engaged
Он принимает для события строковое значение (string_value) 1 в случае, когда сеанс является сеансом с взаимодействием и 0, когда не является. Это выглядит немного странным, поскольку 1 и 0 – это целые числа и должны храниться в поле с типом INTEGER. Но самое интересное, что session_engaged также может быть и числовым значением (int_value). Я встречал в своих данных вот такие события и значения session_engaged:
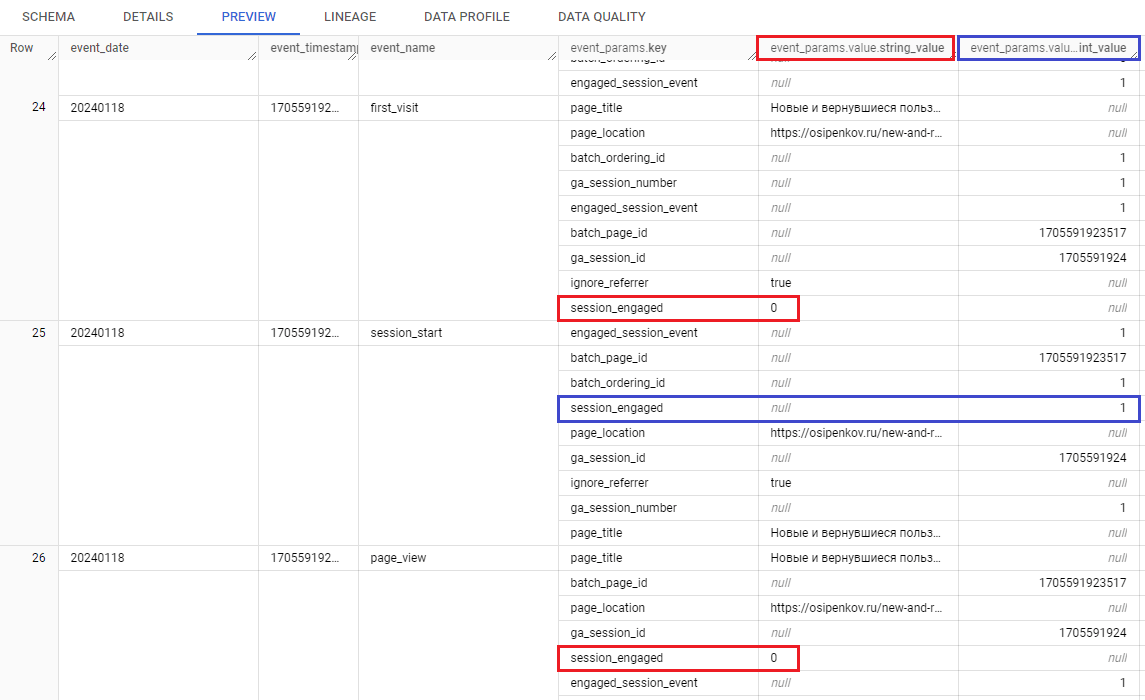
Значение session_engaged может принимать как строковое значение, так и целочисленное.
В одном событии значение session_engaged - string, а в другом - integer. У меня есть предположение, но оно не является подтвержденным. Google добавляет сохраняет числовое значение int_value только для событий session_start, чтобы по ним рассчитывать сеансы с взаимодействием. Для всех остальных событий значение 1 и 0 записывается в string_value.
Почему я так думаю? Попробуйте добавить показатель Сеансы с взаимодействием в отчет по событиям. Вы увидите очень интересную картину - общее количество сеансов в строке Итого рассчитывается именно по событию session_start, а все остальные игнорируются:
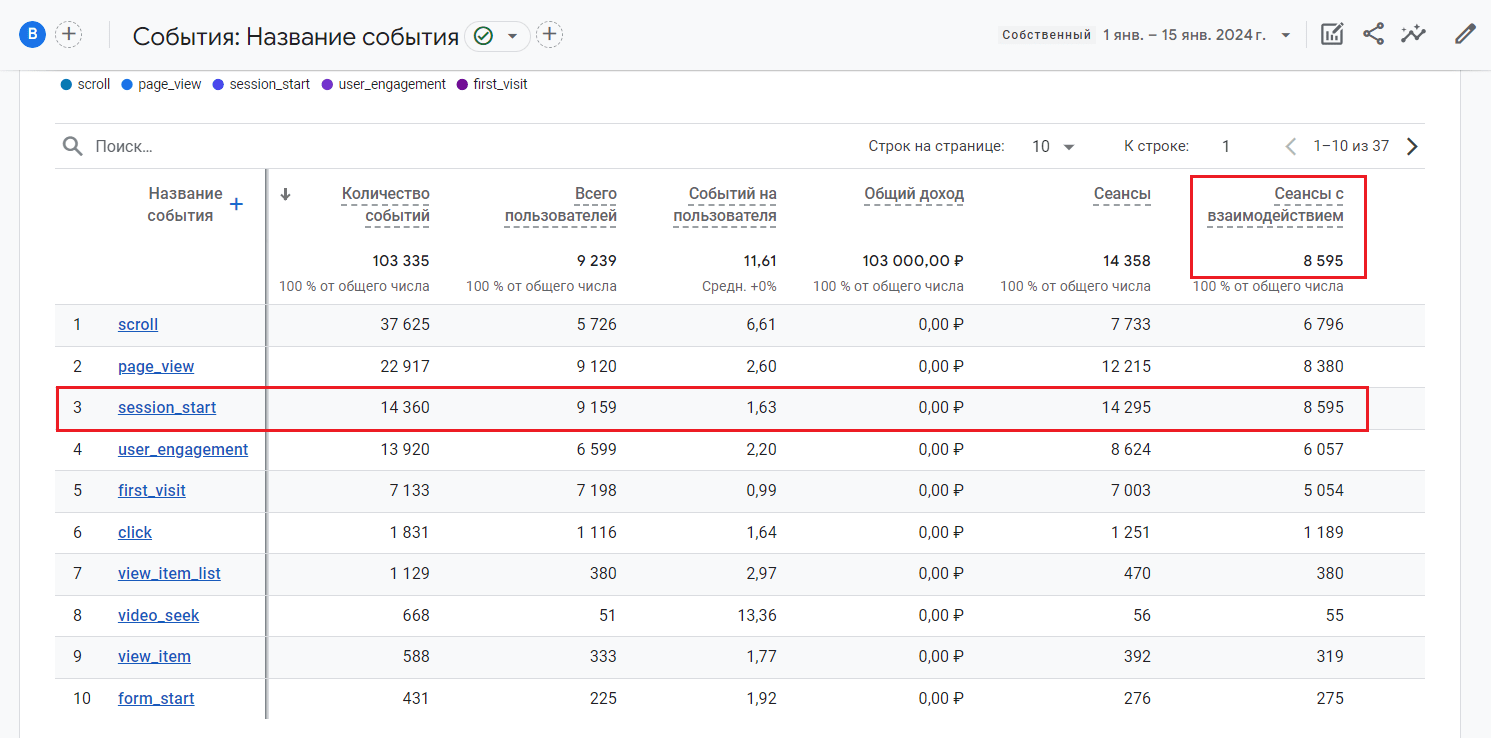
Расчет сеансов с взаимодействием основан на событии session_start
Таким образом, можно сделать вывод, что расчет сеансов с взаимодействием основан на событии session_start. И поэтому в таблицах с событиями в BigQuery напротив события session_start параметр session_engaged хранит свое значение именно в int_value, а не как у всех других событий в string_value.
Помимо параметра session_engaged вы можете встречать очень схожий по написанию параметр события engaged_session_event, являющийся целочисленным значением:
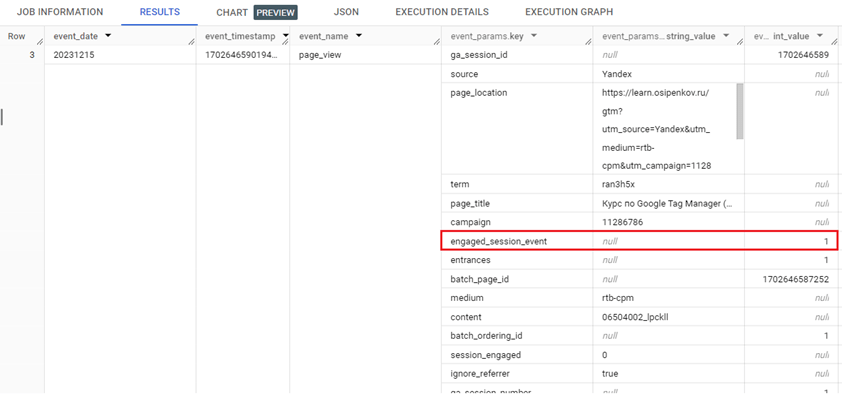
Параметр события engaged_session_event
Он включает в себя количество сеансов, в которых участвует пользователь и может использоваться для отслеживания уровня вовлеченности/взаимодействия. Однако нас сейчас интересует именно session_engaged.
Выполним вот такой SQL-запрос, чтобы учесть оба варианта значений:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT user_pseudo_id, ( SELECT value.int_value FROM UNNEST(event_params) WHERE KEY = 'ga_session_id') AS session_id, COALESCE( (SELECT value.string_value FROM UNNEST(event_params) WHERE KEY = 'session_engaged'), CAST( (SELECT value.int_value FROM UNNEST(event_params) WHERE KEY = 'session_engaged') AS string) ) AS session_engaged FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' |
Сначала нам нужно составить список всех идентификаторов сеанса и выяснить, являются ли они сеансы с взаимодействиями или нет. Затем мы должны подсчитать количество сеансов с взаимодействием. Для идентификатора сеанса ga_session_id используется тип данных INTEGER, поэтому в запросе мы извлекаем это значение из поля value.int_value, в то время как параметр session_engaged имеет два типа данных STRING и INTEGER, поэтому здесь мы используем функцию COALESCE, которая вычисляет по порядку каждый из своих аргументов и на выходе возвращает значение первого аргумента, который был не NULL. А еще используется функция CAST, которая преобразует заданное выражение в заданный тип. В нашем случае - в string.
Добавив к каждому подзапросу псевдоним, выполним сам запрос:
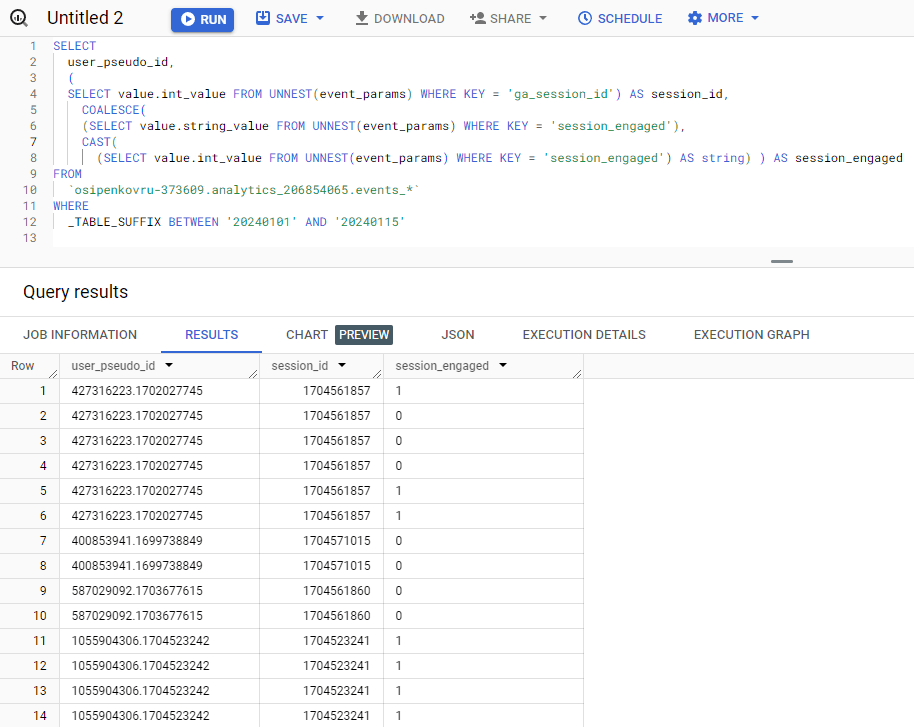
Query results
Результат запроса вернет все строки таблицы с выбранными полями, потому что мы работаем с записями событий. В таблице присутствует множество повторяющихся строк с одним и тем же идентификатором сеанса ga_session_id. Например, даже у одного пользователя может быть такое, что изначально для какого-то конкретного события поле session_engaged в сеансе имеет значение 0, а еще через некоторое время оно принимает значение 1. То есть начиная с определенного события, сеанс пользователя становится сеансом с взаимодействием.
Поскольку наша задача – это подсчитать количество сеансов с взаимодействием, то мы можем прибегнуть к функции MAX, которая вернет в таблице большее значение из представленных для session_engaged, то есть 1. Таким образом, мы сможем подсчитать общее количество сеансов с взаимодействием за выбранный период для уникальных пользователей.
Скорректируем запрос, добавив функцию MAX, а также сгруппируем результаты по выбранным полям:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT user_pseudo_id, ( SELECT value.int_value FROM UNNEST(event_params) WHERE KEY = 'ga_session_id') AS session_id, MAX (COALESCE( (SELECT value.string_value FROM UNNEST(event_params) WHERE KEY = 'session_engaged'), CAST( (SELECT value.int_value FROM UNNEST(event_params) WHERE KEY = 'session_engaged') AS string))) AS session_engaged FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' GROUP BY user_pseudo_id, session_id |
Вы получите таблицу, в которой каждая строка будет представлять уникальную комбинацию user_pseudo_id, session_id и session_engaged. Там, где 1 – у пользователя сеанс с взаимодействием, где 0 – нет.
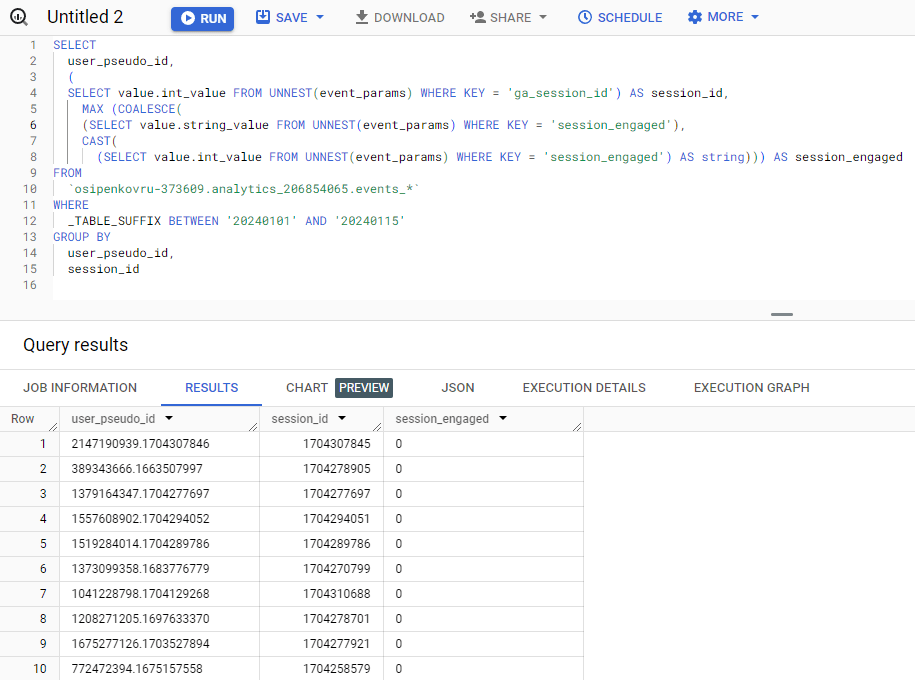
Результат выполнения запроса
Запрос №13. Расчет сеансов с взаимодействием
Несмотря на то, что значение 1 или 0 хранится в параметре session_engaged для int_value и string_value, по моим наблюдениям наиболее близкие результаты с интерфейсными данными Google Analytics 4 вы получите тогда, когда будете использовать именно int_value и событие session_start, а не оба поля и функцию COALESCE.
Поэтому запрос, который вы можете использовать для расчета количества сеансов с взаимодействием, будет выглядеть так:
|
1 2 3 4 5 6 7 8 |
SELECT COUNT(DISTINCT CONCAT(user_pseudo_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id'))) AS session_engaged FROM `osipenkovru-373609.analytics_206854065.events_*` WHERE _TABLE_SUFFIX BETWEEN '20240101' AND '20240115' AND event_name = 'session_start' AND (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'session_engaged') = 1 |
В Google BigQuery результат запроса будет иметь такой вид:
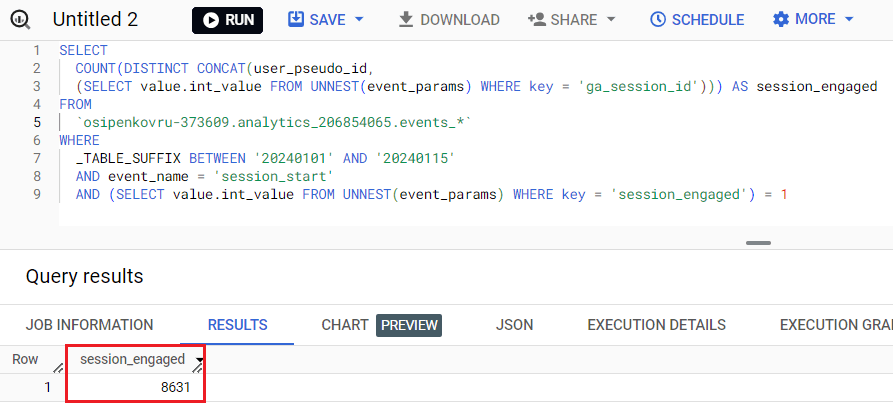
Расчет сеансов с взаимодействием
Если сравнить текущее значение с интерфейсными данными, то окажется, что процент расхождения составляет менее 1%. 8631 сеанс с взаимодействием в Google BigQuery и 8595 сеансов с взаимодействием в моем ресурсе Google Analytics 4 за выбранный диапазон дат.




