Парсер идентификаторов счетчиков аналитики на сайтах и веб-страницах
Пример простого скрипта на Python, который собирает информацию об идентификаторах счетчиков аналитики Google Tag Manager, Universal Analytics, Google Analytics 4, Яндекс.Метрики на сайтах и конкретных веб-страницах в отдельный файл.
Как это работает?
Парсинг - процесс автоматизированного сбора и систематизации данных. Его проводят с помощью программ, которые называются парсерами. Как правило, парсер - сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает результат в нужном вам формате. Парсинг нужен, чтобы ускорить рутинную работу.
Нижеприведенный код позволяет автоматически собирать идентификаторы счетчиков аналитики Google Tag Manager, Universal Analytics, Google Analytics 4, Яндекс.Метрики в отдельный список, который вы зададите в обычном .txt файле, имитируя заходы пользователя на сайты с помощью вашего браузера Google Chrome (его наличие на вашем компьютере обязательно!).
Вот так выглядит результат выполнения программы - отдельный файл, который можно открыть в обычном Microsoft Excel и посмотреть все:
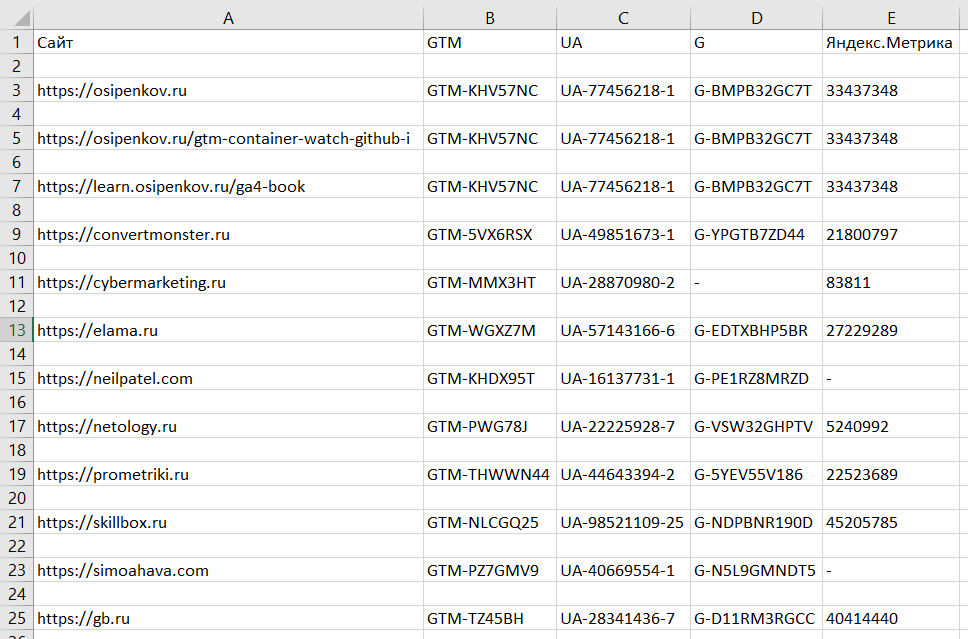
Результат парсинга (пример для собственного списка сайтов)
Это позволит вам быстро проверить наличие указанных счетчиков на нужных страницах и сайтах, включая ваших конкурентов.
Как использовать скрипт?
Для этого вам необходимо выполнить несколько шагов:
- установить программу Visual Studio;
- создать проект;
- установить необходимые библиотеки из файла;
- подготовить список нужных сайтов и веб-страниц;
- скопировать код и вставить его к себе;
- запустить код и получить результат.
Рассмотрим каждый шаг запуска парсера подробнее.
Примечание: если вы разбираетесь в программировании, то вы можете использовать интегрированную среду разработки (IDE), отличную от представленной ниже. Однако в случае возникновения каких-либо проблем с запуском парсинга и последующих ошибок в программе вам придется самостоятельно искать решения.
Установка программы Visual Studio
Для этого перейдите по ссылке и скачайте дистрибутив Visual Studio под вашу операционную систему (для Windows или Mac). Скачивайте именно Visual Studio, а не Visual Studio Code. Используйте версию Community:
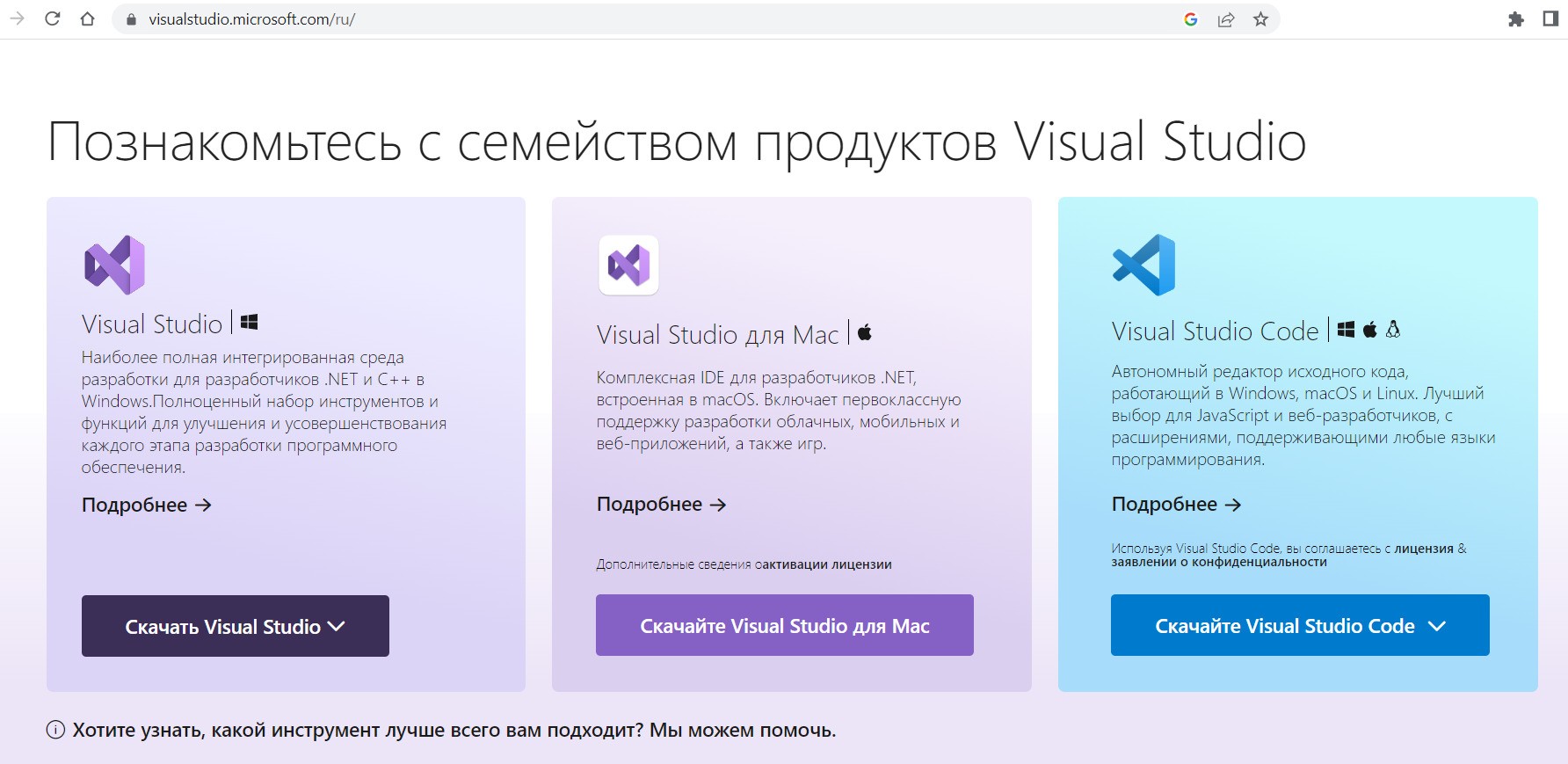
Скачивание программы Visual Studio
Запустив программу, Visual Studio Installer начнет процесс установки. Нажмите кнопку Продолжить:

Visual Studio Installer
Программа начнет устанавливаться:
Скачивание и установка
В открывшемся окне поставьте галочку рядом с Разработка на Python и нажмите Установить:
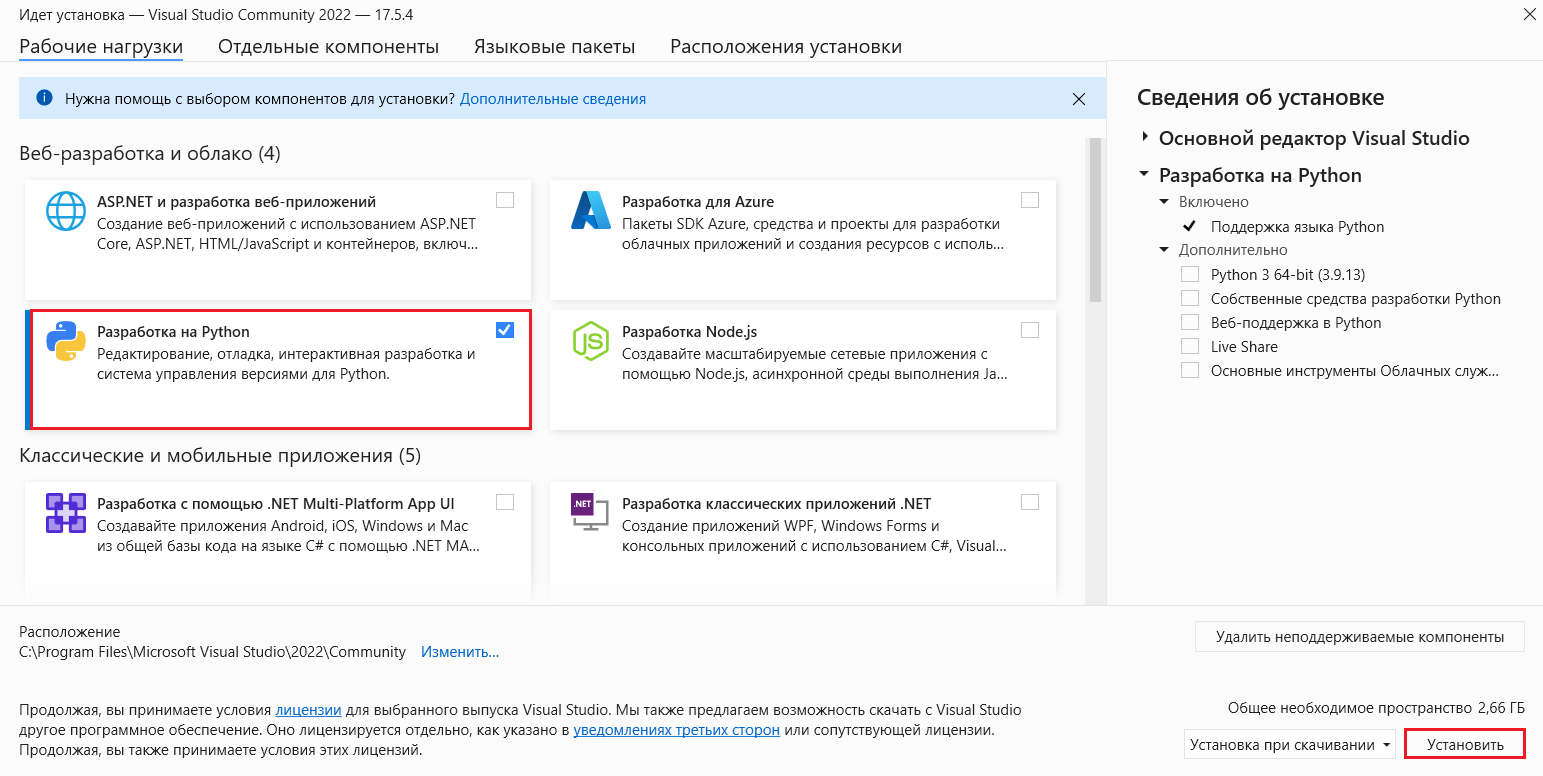
Разработка на Python - Установить
Visual Studio Installer начнет устанавливать выбранные продукты программы и пакеты:
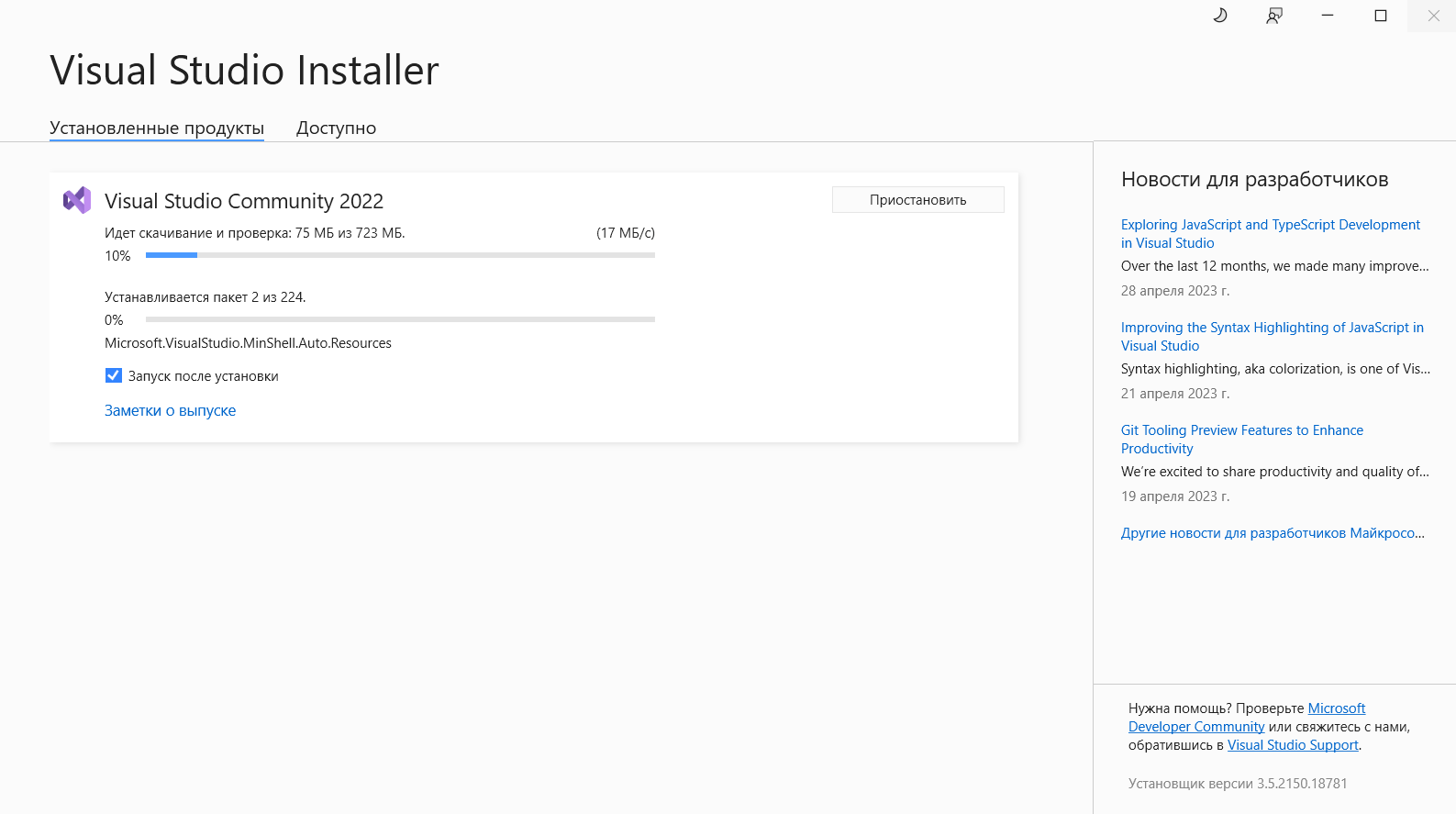
Установка выбранных продуктов
По завершении вам предложат войти в Visual Studio. Создать учетную запись можно потом. Для упрощения запуска программы пропустите этот шаг:
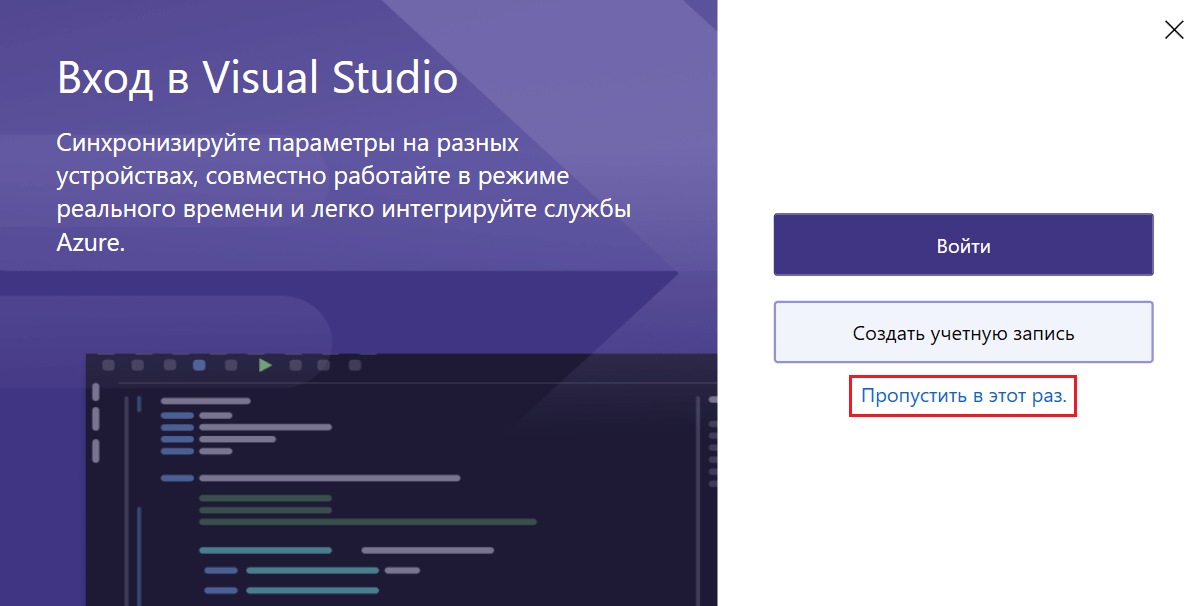
Пропустить в этот раз
Параметры разработки оставьте без изменений (Общие), а цветовую схему программы можете поменять в зависимости от собственных предпочтений. Нажмите Запустить Visual Studio:

Запуск Visual Studio
Создание проекта
В открывшемся окне программы выберите вариант Создание проекта:
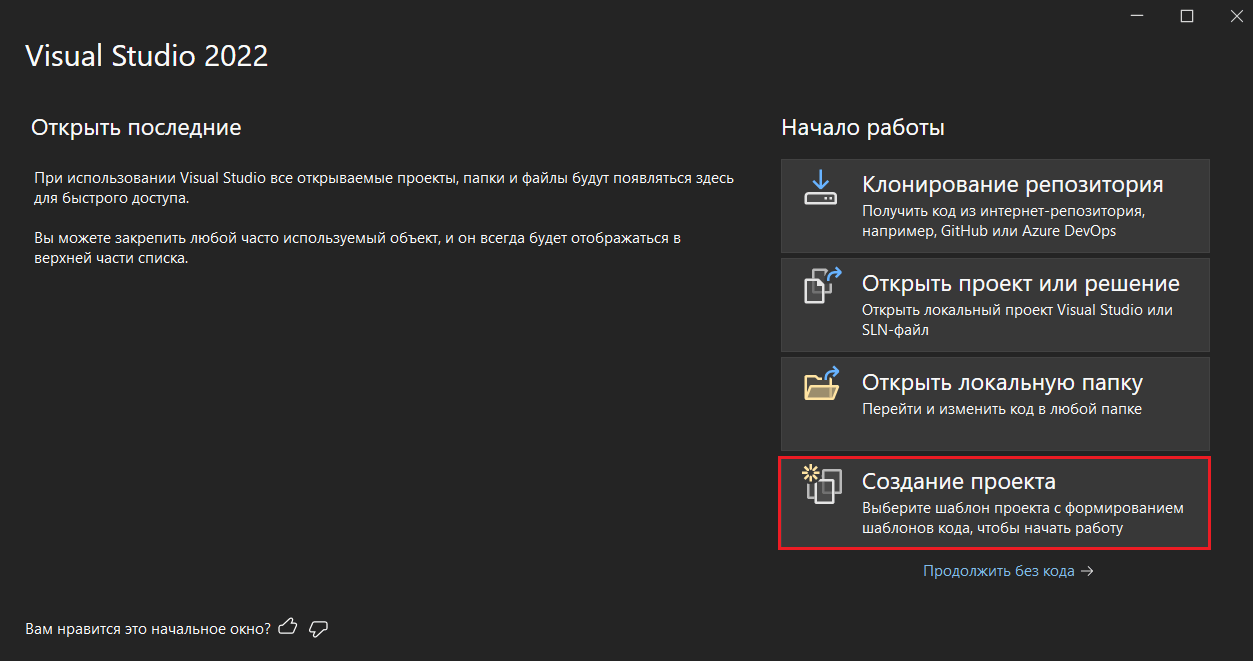
Создание нового проекта в Visual Studio
На следующем этапе выберите Приложение Python и нажмите Далее:
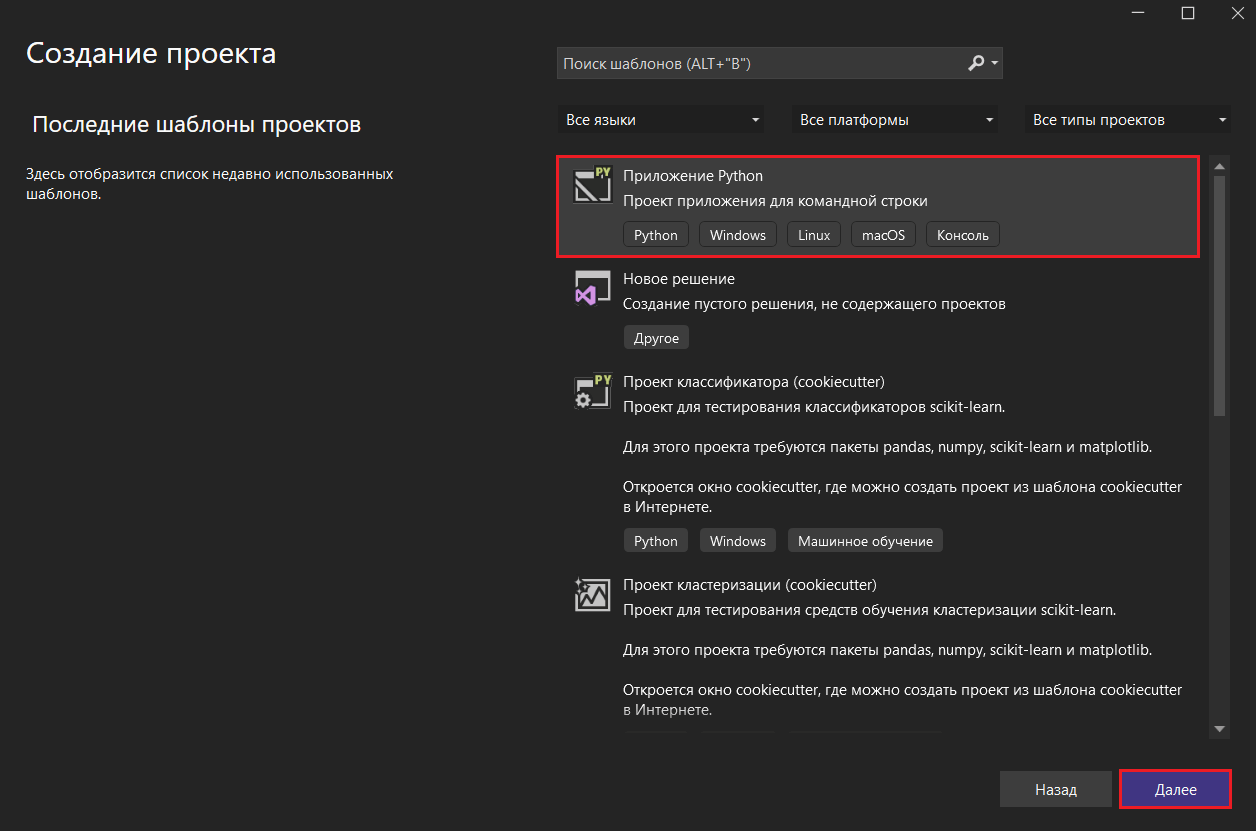
Приложение Python
В настройках проекта укажите его имя (например, IDTracker) и расположение (измените путь или оставьте по умолчанию), и в завершение нажмите Создать:

Имя проекта и расположение
После создания нового проекта в указанной директории вам откроется программа Visual Studio:

Интерфейс программы Visual Studio с выбранном темой
На этом установка Visual Studio и создание проекта завершены.
Установка необходимых библиотек из файла
Скрипт-парсер писался на конкретных версиях библиотек Python (не последних!), поэтому вам нужно установить определенный набор пакет с нужными версиями. Для этого скачайте файл .txt по ссылке и добавьте его в свой проект по тому пути, который вы указали на предыдущем шаге при создании проекта. Для моего примера это путь C:\...\source\repos\IDTracker\IDTracker:
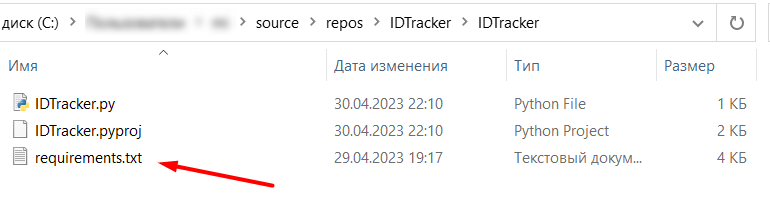
Файл requirements.txt в папке проекта
Перезапустите программу Visual Studio, открыв свой проект. Вы должны увидеть строку такого типа: В проекте "ваш_проект" обнаружен файл спецификации пакета Python "requirements.txt", а рядом будет ссылка на создание виртуальное среды. Нажмите на нее:
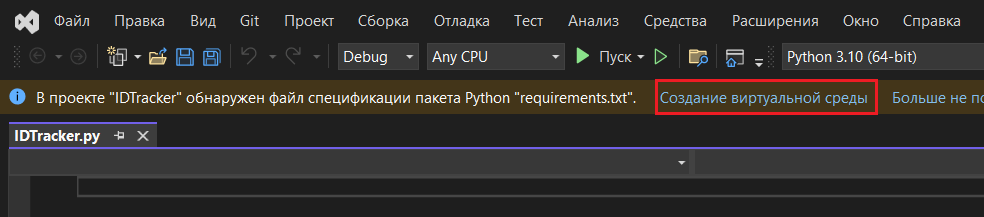
Создание виртуальной среды
Проверьте, чтобы по пути установки пакетов из файла был указан именно тот путь, куда вы поместили скачанный файл requirements.txt. Затем нажмите кнопку Создать:
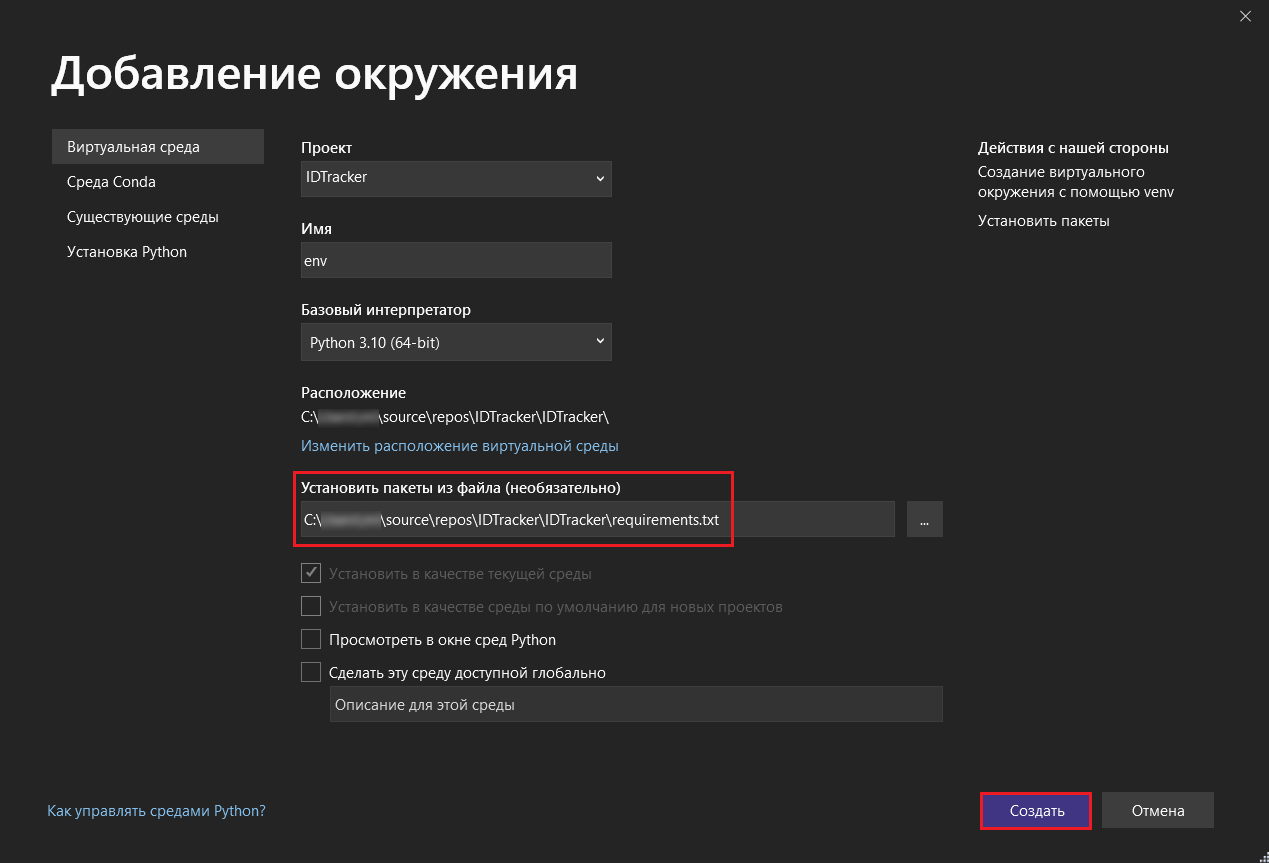
Добавление окружения
В обозревателе решений (справа) в вашем проекте вы увидите новое окружение Python - env (виртуальную среду):
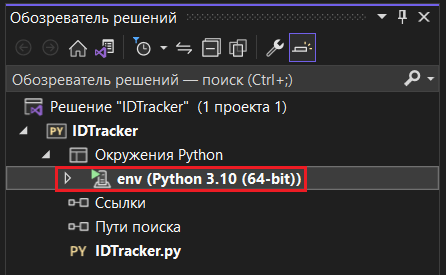
Новая виртуальная среда
У вас должна начаться автоматическая загрузка всех пакетов, включая тех, что указаны в файле requirements.txt, с нужными версиями. Когда это действие будет завершено, в своем обозревателе решений для созданной виртуальной среды вы увидите все установленные библиотеки:
Установленные библиотеки (часть)
Если автоматическая установка не началась, вы можете запустить ее вручную, нажав на виртуальную среду правой кнопкой мыши, а затем выбрав меню Установить из requirements.txt:
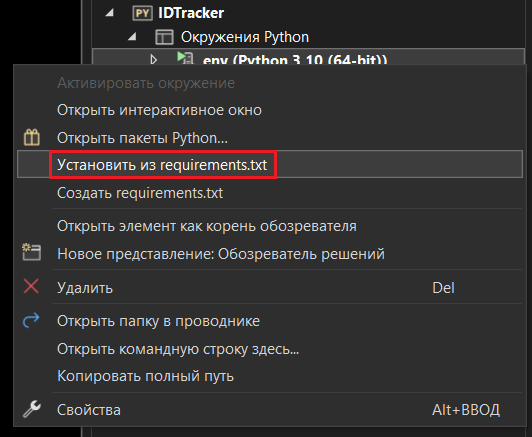
Установить из requirements.txt
Как я писал выше, парсер писался на конкретных версиях библиотек Python, поэтому вам нужно установить определенный набор пакет с нужными версиями. Если вы используете глобальную среду и в ней уже установлены схожие библиотеки, только других версий, вам нужно использовать отдельную виртуальную среду и установить в нее библиотеки с версиями из requirements.txt. Иначе вы не сможете запустить данный код.
Подготовка списка нужных сайтов и веб-страниц
Теперь создайте обычный файл .txt и добавьте в него список нужных сайтов и веб-страниц, с которых вы хотите парсить информацию об идентификаторах счетчиков аналитики. Каждая ссылка или домен сайта задается на отдельной строке, протокол https или http можно не использовать. Например, ваш файл может выглядеть так:
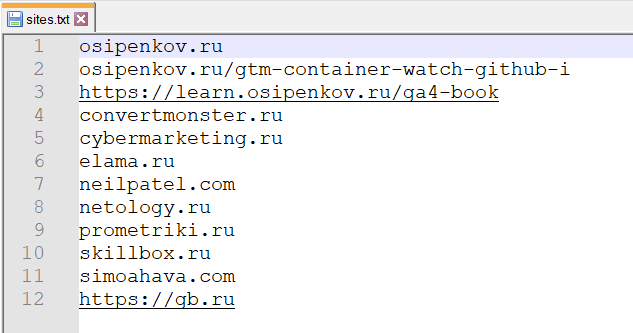
Пример списка сайтов и веб-страниц для парсинга
Сохраните ваш файл, задав ему имя (например, sites.txt), и поместите в ту же папку проекта, что и файл requirements.txt:
Файл со списком сайтов в папке проекта
В Visual Studio вы увидите этот файл в папке проекта, переключившись между решениями и доступными представлениям (отображение папок):
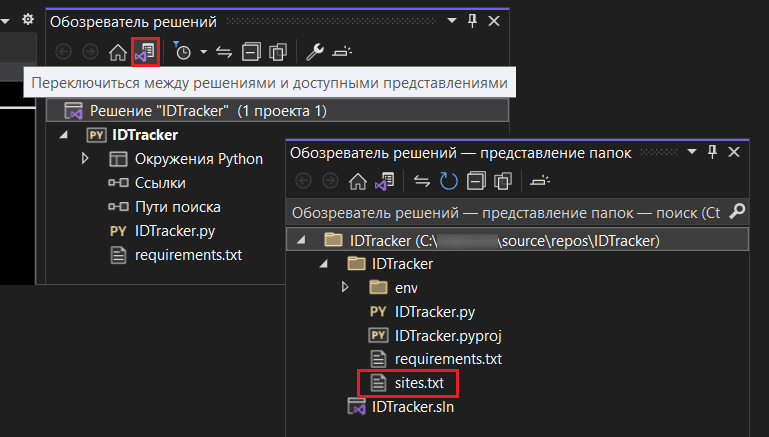
Обозреватель решений - представление папок
На этом подготовительные работы для парсинга закончены. Теперь переходим к самой программе!
Копирование кода программы
Скачайте файл программы по ссылке, откройте любым текстовым редактором (блокнотом или Notepad++) и скопируйте все его содержимое:
Копирование кода программы
Вернитесь в свой проект Visual Studio и откройте ваш файл .py. Вставьте в него весь скопированный код:

Копирование кода в файл проекта Visual Studio
В этой программе вам нужно изменить несколько строчек кода. Во-первых, найдите код:
|
1 2 |
userData="--user-data-dir=C:\\Users\\mi\\AppData\\Local\\Google\\Chrome\\User Data"; #Прописать путь к UserData Chrome, например "--user-data-dir=C:\\Users\\UserName\\AppData\\Local\\Google\\Chrome\\User Data" |
и в userData= добавьте путь к вашей папке User Data для браузера Google Chrome. Как правило, это директория со скрытой папкой App Data и путь для Windows имеет вид C:\Users\Имя_польхователя\AppData\Local\Google\Chrome\User Data\. Для пользователей Mac OS X и других операционных систем воспользуйтесь этой инструкцией.
Формат написания должен быть именно такой, какой указан в примере, вместе с --user-data-dir и двумя косыми чертами вместо одной + кавычки с обеих сторон.

Путь к папке User Data (браузер Google Chrome)
А во-вторых, найдите в коде такие строки:
|
1 2 |
#Загрузка ссылок/сайтов из текстового файла fileHandler=open("sites.txt","r"); |
И проверьте, чтобы в скобках было написано точно такое же название файла со списком сайтов и веб-страниц, которое вы указали на предыдущем шаге.
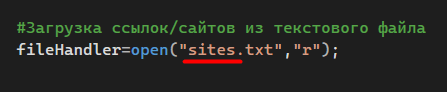
Название файла со списком сайтов и веб-страниц
Если оно отличается от sites.txt - поменяйте его на свое.
В завершение сохраните свою программу в кодировке UTF-8. Для этого в левом верхнем углу Visual Studio нажмите Файл - Сохранить проект как...
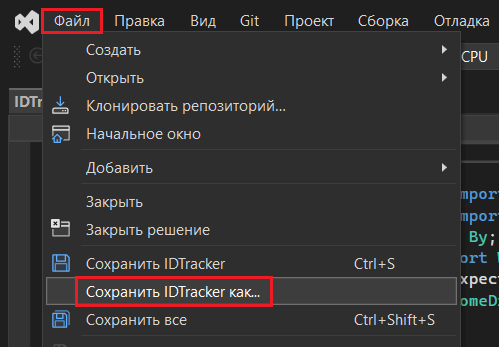
Файл - Сохранить проект как...
Рядом с кнопкой Сохранить нажмите на иконку со стрелочкой и выберите Сохранить с кодировкой:
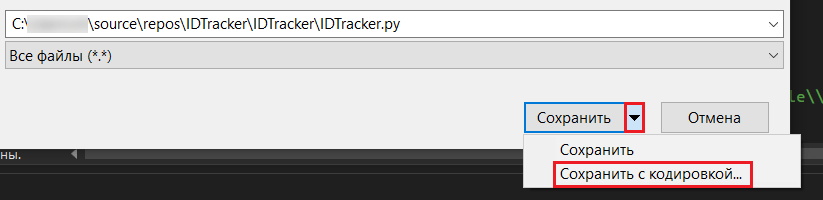
Сохранить с кодировкой
В дополнительных параметрах выберите кодировку Юникод (UTF-8, с сигнатурой), кодовая страница 65001, а затем сохраните свою программу:
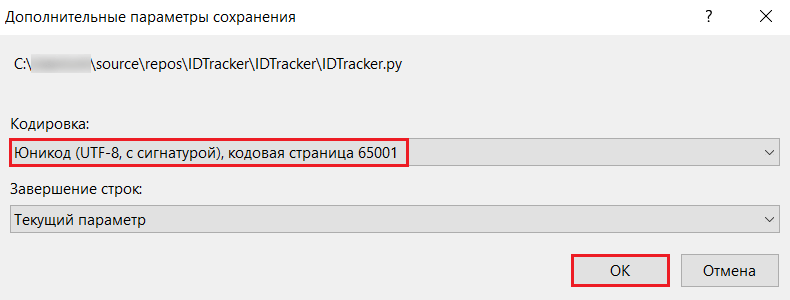
Юникод (UTF-8, с сигнатурой), кодовая страница 65001
После этого вы можете полностью закрыть Visual Studio, а затем повторно открыть свой проект.
Запуск парсера
После всех вышеописанных настроек вам осталось только запустить выполнение программы. Для этого в самом верху программы нажмите на кнопку Пуск:

Запуск парсера
Перед запуском скрипта-парсера закройте ваш браузер Google Chrome. Небольшое видео по тому, как работает парсер (ускорено):
После запуска программы парсер автоматически откроет ваш браузер Google Chrome и начнет самостоятельно посещать сайты и веб-страницы из заданного списка. Как только значения идентификаторов счетчиков будут найдены, парсер сохранит их у себя и перейдет к следующему сайту из списка, потом к следующему, и так далее, пока не дойдет до конца. Скорость парсинга можно регулировать с помощью переменных, заданных в самом начале скрипта:
- maxTries - максимальное количество попыток, которое плагин должен предпринять при отправке события на целевой URL-адрес;
- longSearch - (False - быстро, True - медленно);
Чем больше у вас список сайтов и веб-страниц, тем дольше программа будет парсить идентификаторы. Среднее время обхода одной страницы сайта ~ 30 секунд, однако в некоторых случаях это время может быть больше. Поэтому парсинг лучше запускать в свободное от работы время, когда вы не находитесь за компьютером или же выполняете простые задачи (читаете новости, сидите в социальных сетях и т.д.). Просто запустите код в фоновом режиме и смело идите пить чай/кофе!
Результат парсинга
После прохода по всем ссылкам браузер автоматически закроется, а в папке с проектом появится новый файл с названием table.csv:

Файл с результатами парсинга
Открыв его в Excel, вы можете разбить текст по столбцам, указав в качестве разделителя запятую:
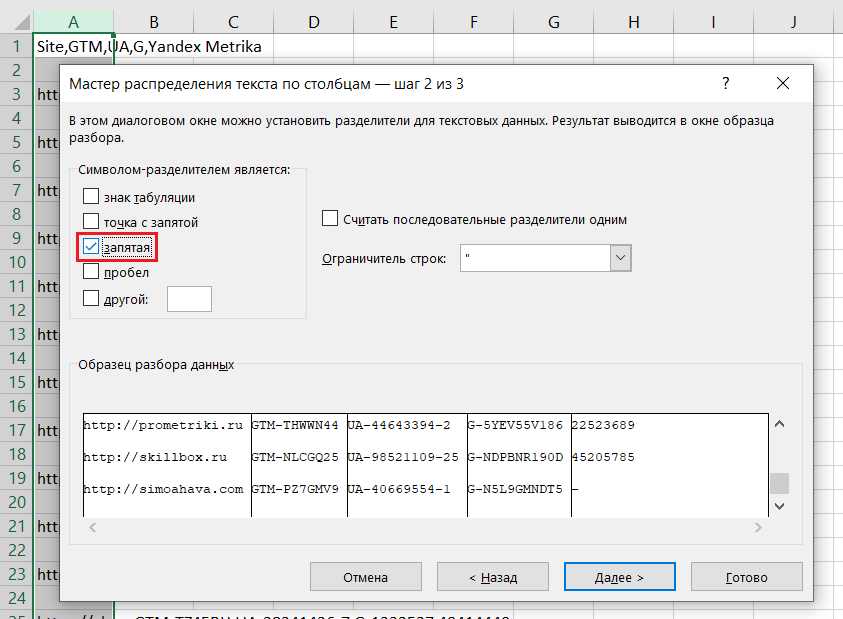
Текст по столбцам с разделителем "запятая"
Выполнив данную функцию, вы получите результат в виде таблице с данными по каждой ссылке и идентификатору:
Таблица с данными парсинга
Не забудьте, что парсинг - это автоматический процесс, но даже для него нужны определенные условия. В одном случае вы можете запустить программу и увидите идентификаторы для всех счетчиков, а при повторном запуске скрипта где-то чего-то не будет хватать, даже для тех же самых сайтов и веб-страниц. В этом случае я рекомендую менять переменные maxTries (задать большее значение, например 5-7) и longSearch (True). Скорость парсинга снизится, но результат будет лучше!


