Стандартная электронная торговля (Google Tag Manager + Web Scraping)
Видео настройки стандартной электронной торговли с использованием Google Tag Manager и технологии веб-скрапинга (Web Scraping), позволяющей получить доступ к информации на странице веб-сайта из DOM-дерева.
Вступление
Перед тем, как вы начнете читать данный материал, я предполагаю, что у вас есть общее представление о браузерах, HTTP-запросах, DOM (объектной модели документа), HTML, селекторах CSS и асинхронном коде JavaScript. Именно такие знания вам понадобятся, если вы планируете извлекать нужную вам информацию со страницы веб-сайта для последующей ее передачи в инструменты веб-аналитики. Я надеюсь, что вы также предварительно познакомились с моим руководством по настройке стандартной электронной торговли с помощью диспетчера тегов Google для лучшего понимания приведенной ниже информации.
Начнем с самого простого. Как вы используете Google Tag Manager в своей работе? Я уверен, что большинство интернет-маркетологов выполняют стандартные настройки путем использования уже существующих переменных, триггеров и тегов, которые уже есть в интерфейсе системы. Меньшая часть пользователей GTM применяет в работе собственные коды JavaScript или формирует уровень данных (dataLayer) для решения более сложных задач.
Использование dataLayer значительно расширяет способы отслеживания. Однако не всегда есть возможность своими собственными силами сформировать уровень данных с необходимым набором параметров. В этом случае мы, как правило, обращаемся за помощью к разработчику. Например, для формирования уровня данных расширенной электронной торговли, или отслеживания динамического ремаркетинга, функции User ID и т.д. Использование готовых плагинов для популярных CMS-систем тоже является хорошим вариантом решения. Но и это не всегда возможно. Программист может быть занят своими делами, и в ближайшее время не приступит к выполнению вашей задачи, или его в команде может вообще не быть, и тогда придется искать кого-то на стороне. А в случае с готовыми решениями для веб-сайтов - его может не существовать... Что же делать?
Тогда нам нужно формировать уровень данных самостоятельно. Сделать это можно с помощью Google Tag Manager. Технология получения веб-данных путем извлечения их со страниц сайтов по-английски называется DOM Scraping (Web scraping). Это означает, что вы можете извлечь данные из элементов, которые уже существуют на странице - заголовки страниц, классы, идентификаторы, URL-адреса и т.д., и собрать это все в собственный уровень данных, не дожидаясь помощи разработчиков.
Пример отслеживания (GTM + Web Scraping)
Классический пример отслеживания с использованием веб-скрапинга - отправка формы. В статье, посвященной 9 способам отслеживания отправки форм с помощью Google Tag Manager, такая настройка идет под номером 7. Смысл заключается в следующем - когда пользователь заполняет форму на вашем сайте и отправляет ее данные, страница может перезагрузиться, контент поменяться, но сам URL-страницы может остаться прежним. В этом случае вы можете использовать новые элементы (сообщение об успешной отправки формы) как триггер для активации тега и передачи этой информации в Яндекс.Метрику или Google Analytics.
Другой вариант использования - это извлечение каких-то конкретных значений со страницы. Например, номера заказа, имя автора материала, цены товара, характеристик продукта (цвет, размер, наличие) и т.д.
Предположим, что после отправки формы пользователя перенаправляет на отдельную страницу, на которой отображается номер заказа:

Код заказа на странице успешной отправки формы
И мы хотим, чтобы значение кода заказа отправлялось в счетчики аналитики вместе с событием отправки самой формы. Как это сделать? Для извлечения этих данных со страницы можно создать пользовательскую переменную с типом Элемент DOM. Если у отслеживаемого элемента на странице есть идентификатор (ID селектора), то в поле Метод выбора достаточно вставить Идентификатор. В противном случае используется второй вариант Селектор CSS.
Чтобы узнать селектор отслеживаемого элемента, необходимо с помощью консоли разработчика (для Google Chrome - клавиша F12) на вкладке Elements найти его в DOM-дереве, кликнуть по нему правой кнопкой мыши и выбрать Copy – Copy selector.
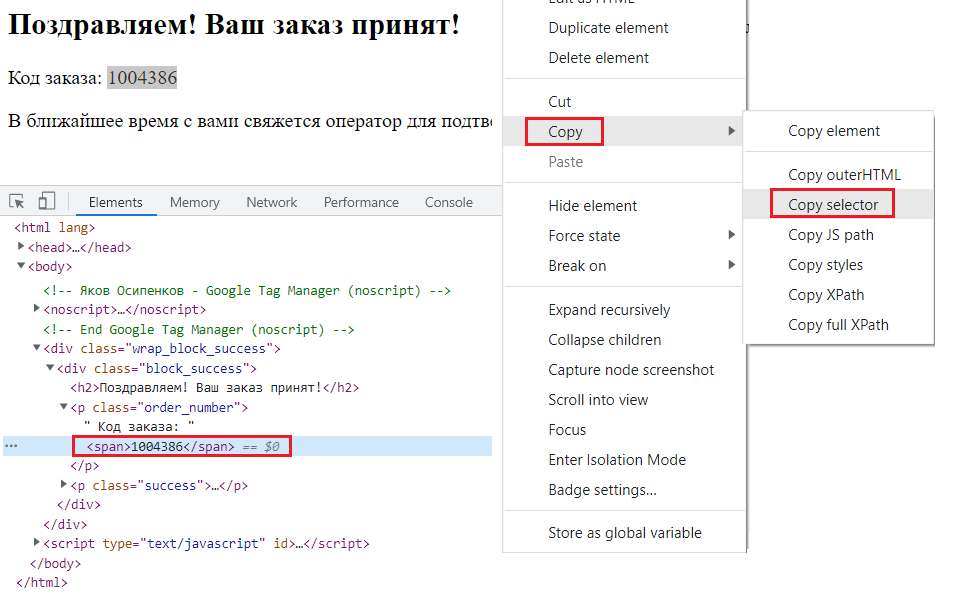
Копирование селектора CSS отслеживаемого элемента
Полученное значение добавляется в пользовательскую переменную Элемент DOM:
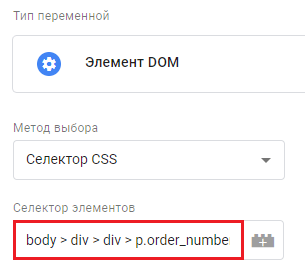
Переменная "Элемент DOM"
После этого проверить корректность извлечения данных по коду заказа можно в режиме предварительного просмотра:
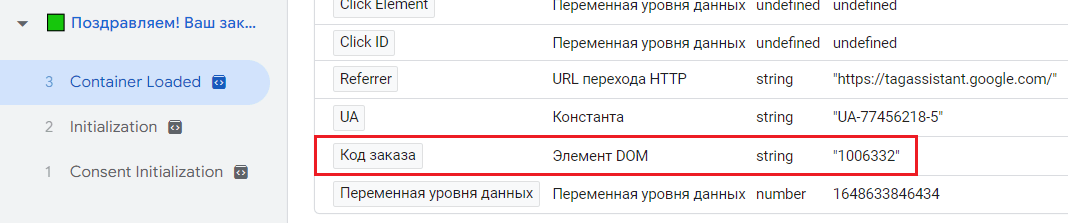
Проверка переменной в режиме отладки GTM
Теперь вы можете делать с этими данными все что угодно - запускать определенные условия активации, передавать в сторонние трекеры (в Яндекс.Метрику, Google Analytics), использовать в других переменных диспетчера тегов Google, формировать с этой переменной уровень данных и т.д. Все зависит от конкретных задач.
Этим примером я хотел показать возможность веб-скрапинга - как со страницы, на которой уже присутствует информация, извлечь ее и использовать в своих целях.
Недостаток отслеживания (GTM + Web Scraping)
Но в таком способе есть один существенный недостаток - все, что мы делаем, завязано на объектной модели документа (DOM). И при изменении каких-либо классов, идентификаторов отслеживаемых элементов на сайте или общей структуры DOM-дерева есть большая вероятность потерять все настройки. Хорошо, когда требуется извлечь одно значение со страницы. Но в той же стандартной электронной торговле таких переменных гораздо больше, и не все они присутствуют на странице, с которой вы будете их извлекать:
- для данных о транзакции обязательными параметрами являются transactionId и transactionTotal;
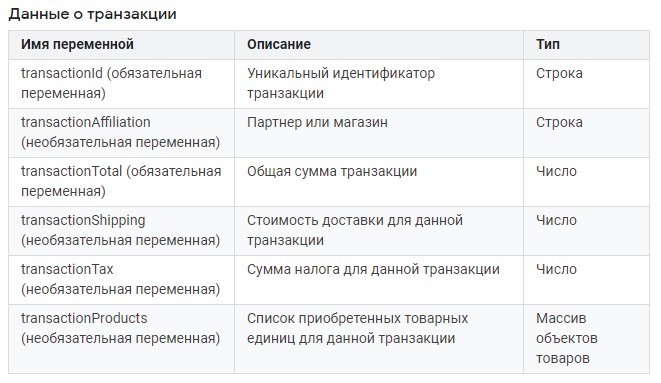
Обязательные переменные - transactionId, transactionTotal
- для данных о товарах обязательными параметрами являются name, sku, price, quantity;
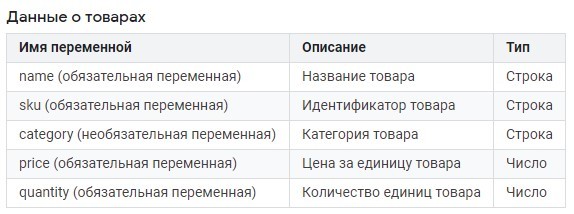
Обязательные переменные - name, sku, price, quantity
А это важное условие отслеживания. В расширенной электронной торговле таких событий еще больше, и больше обязательных параметров, требующих передачи.
Именно поэтому лучше выполнять настройку электронной торговли или любых других нестандартных событий на сайте с привлечением разработчика, который сформирует вам нужные данные и отправит их в dataLayer, а не самостоятельно делать это с помощью веб-скрапинга. Тем более, что это не так просто, как кажется на первый взгляд.
Настройка стандартной электронной торговли (Видео)
Но если вам все-таки хочется заняться этим на досуге и попробовать извлечь все данные для электронной торговли с помощью Google Tag Manager и веб-скрапинга, чтобы потом сформировать из переменных dataLayer и отправить эту информацию в Universal Analytics, я рекомендую посмотреть мое видео на эту тему.
Это отрывок из занятия по онлайн-курсу "Google Tag Manager", в котором я показываю способ настройки стандартной электронной торговли для Universal Analytics с помощью Google Tag Manager и веб-скрапинга. Специально для слушателей и наглядной демонстрации совершаемых действий я создал отдельную страницу, на которой сразу же отобразил всю необходимую информацию по заказу и товарам, поскольку это является необходимым условием для веб-скрапинга.
Извлекая поочередно обязательные параметры для события purchase с помощью Google Tag Manager, мы получаем уровень данных, понятный Google Analytics. Как вы видите, это не такой простой процесс и требует больших усилий и четкого понимания того, что вы делаете. К тому же, не на всех сайтах на итоговой странице вам будут доступны сведения по транзакции и товарам, которые нужно извлечь. Именно поэтому на курсе я создавал отдельный сайт для этого.
Резюме
Может получиться так, что количество времени, которое вы потратите на изучение моего видео, дополнительных статей в интернете и финальную настройку электронной торговли с помощью GTM и Web Scraping будет несопоставимо с тем, сколько будет стоить просто купить готовое решение для вашего сайта (20-50$). И конечный результат не оправдает ваших ожиданий. Скорее всего, что-то будет работать не так, как планировалось.
Для тех же интернет-магазинов на WordPress, использующих WooCommerce, есть бесплатные плагины, позволяющие настроить расширенную электронную торговлю, динамический ремаркетинг и User ID всего за пару минут. Об этом я писал в своем блоге:
- Расширенная электронная торговля Universal Analytics для WooCommerce (WP)
- Настройка User ID для сайтов на WordPress
Некоторые до сих пор пытаются убедить меня и других в том, что Google Tag Manager может быть инструментом для полной автономности и независимости от сторонней помощи. Я с этим не согласен и считаю, что несмотря на то, что GTM позволяет выполнять сложные и трудоемкие настройки и отслеживания, рациональнее всего привлекать для больших задач соответствующих специалистов, а не пытаться использовать его в паре с Web Scraping. Как минимум, для большой троицы - расширенной электронной торговли, функции User ID и динамического ремаркетинга.
Пересмотрите это видео и подумайте несколько раз прежде, чем будете пытаться совершить любую сложную настройку (не только стандартную электронную торговлю) с помощью диспетчера тегов Google и веб-скрапинга. Вполне вероятно, что эту задачу дешевле и быстрее поручить разработчику.




